Продолжение тестов в 2023. Диапазонн отбор, основные исходы, все по 2-4.
-
ПопулярностьТоп-5804
-
Постов153
-
Просмотров17,526
-
Подписок9
-
Карма автора+891
-
В принципе, мы всегда старались подробно отвечать на все вопросы пользователей, которые действительн
+2
-
Не стоит ему смотреть, он безнадежен. Зачем вообще тратить время на спор с полнейшим фишем? Есть люд
+2
-
Есть инфа, что он, ставя на смоллы (итф турниры в теннисе) вручную двигал линию, создавая себе искус
+2
-
колосальная работа дружище. молоток!
+1
-
Да кто вас знает ) все разные . Кто то в доту зачем то играет всю жизнь . Мало ли у кого какой извра
+1
-

-
Скопировал себе видео о дисперсионном отклонении в беттинге, с наглядными примерами, на пальцах, так сказать. Первое видео (для сохранности, в случае возможного удаления в будущем из-за разных причин) с украинским звуковым дубляжом, так как даже изменив по необходимости в настройках Гугла нужные галочки, на моем устройстве в таких новых видео со звуковым авто-дубляжом российский язык не отображается. Так что кому принципиально - ниже можно посмотреть этот ролик на платформе со своими параметрами озвучивания.
-
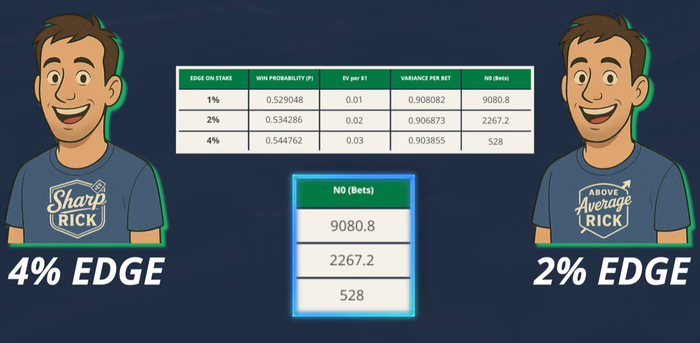
https://sportsbettingcalcs.com/betting-tools#bet_simulator
Симулятор дисперсии и разного рода калькуляторы.
-
-
-
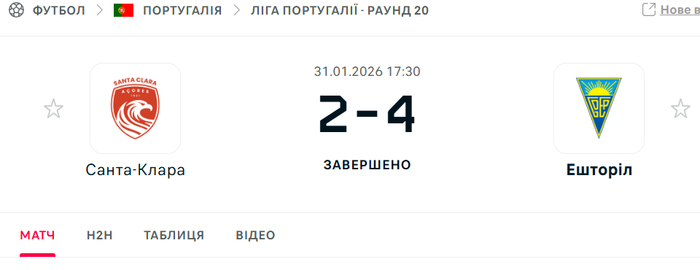
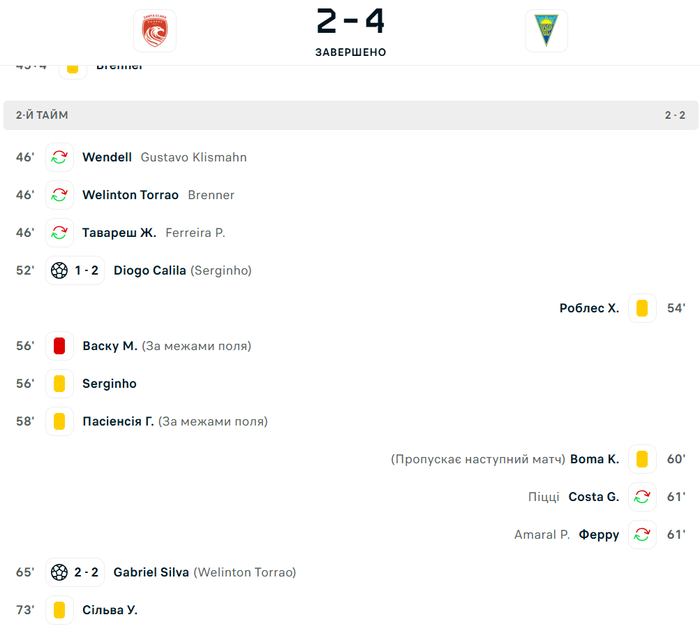
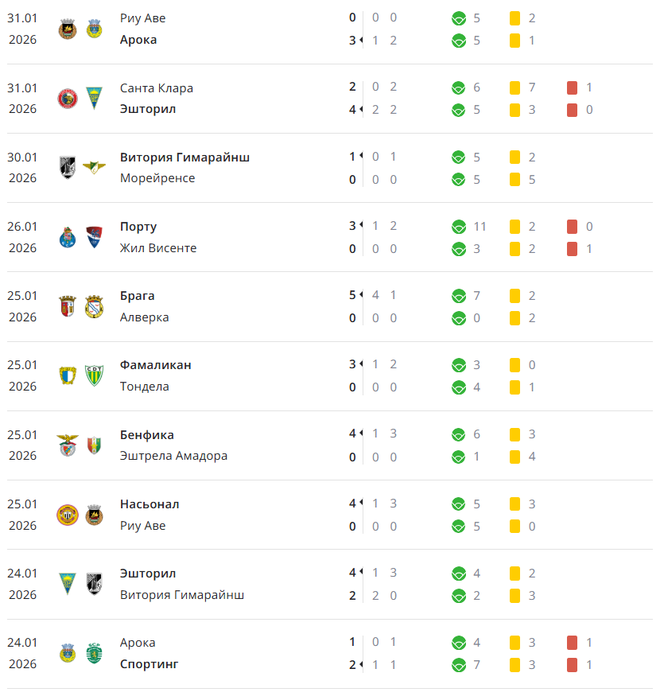
Сейчас столкнулся с таким моментом. На некоторых сайтах, у меня же речь идет о Лайвскор, откуда я записываю необходимую статистику (ну и так между прочим количество красных карт в матчах), не отображается реальная картина. Возможно для тех , кто использует другие сайты, с более детальным подходом к различной стате, с такими проблемами не сталкиваются. Но говорю именно за этот сайт. Короче, сайт не учитывает красные карточки полученные за нахождение вне пределов поля. Нарушение вроде незначительное но части игроков на поле нет. Для меня это неожиданная новость. Возможно с данного сайта берется статистика некоторыми БК для выплаты выигрышей, поэтому такие нарушения не воспринимаются ими как жесткий фол, но это просто мысли. Приведу пример с двумя матчами португальской Примейры (Лига Португалии) Санта Клара - Эшторил и Ароука - Спортинг:
1)
2)

Это статистика данных матчей из другого сайта
-
Из интересного почитать
Pope and Peel (1989) показали, что вариабельность вероятности ничьей очень мала и что коэффициенты ничьей не имеют существенного прогностического значения. Анализ ничьих, проведенный на основе нашего набора данных, подтвердил выводы Поупа и Пила (Pope and Peel, 1989), которые не выявили существенной взаимосвязи между коэффициентами на ничью и исходами во всех рассмотренных лигах. Поэтому в дальнейшем мы будем моделировать коэффициенты на победу хозяев и гостей совместно и не будем учитывать ничьи.
https://habr.com/ru/articles/844736/ Эффективность футбольного рынка ставок
https://habr.com/ru/articles/918196/ Прогнозирование исходов футбольных матчей в реальном времени с помощью байесовской модели

cappelchi20 сен 2024 в 09:00
Эффективность футбольного рынка ставок
Сложный
22 мин
1.5K
Математика*Машинное обучение*Исследования и прогнозы в IT*Статистика в ITФинансы в IT
Перевод
Автор оригинала: Giovanni Angelini, Luca De Angelis
Предисловие
Разбираем статью 2018 года Giovanni Angelini'a, Luca De Angelis'a «Efficiency of online football betting markets».
В этой статье оценивается эффективность рынков ставок онлайн для европейских футбольных лиг. Существующая литература показывает неоднозначные эмпирические данные относительно степени эффективности рынков ставок. Ниже рассматривается, основанный на прогнозах подход для формального тестирования эффективности, рынков ставок онлайн. Рассматривая коэффициенты, предложенные 41 букмекером для 11 основных европейских лиг за 11 лет, мы находим доказательства различной степени эффективности и показываем, что если выбрать лучшие коэффициенты среди букмекеров, восемь рынков эффективны, а три демонстрируют неэффективность, которая подразумевает возможности получения прибыли для игроков. В частности, этот подход позволяет оценить пороговые значения коэффициентов, которые можно использовать для установления прибыльных стратегий ставок как ex post, так и ex ante.
Спойлер: если вы только думаете в какую футбольную лигу погрузиться выбирайте Greek Super League или the Spanish Liga, которые на 2018 год являлись самыми неэффективными.
С практической точки зрения к статье остается вопрос о количестве букмекеров. Очень сложно управлять счетами в 40 букмекерских конторах и управлять, связанной с этим безопасностью. Сокращение количества, может сказать на доступности максимальных коэффициентов.

1. Введение
Вопрос о степени эффективности имеет решающее значение для анализа рынков, поскольку неэффективность рынка, при правильном прогнозировании и измерении, может создать значительные возможности для получения прибыли. Применительно к финансовым рынкам, Fama (1970) выдвинул знаменитую гипотезу эффективного рынка, которая в своей слабой форме постулирует, что рынки эффективны в том смысле, что текущие цены отражают всю информацию, содержащуюся в ценах за прошлые периоды, что исключает возможность получения избыточной прибыли с использованием методов технического анализа. В целом, информационная эффективность требует, чтобы цены отражали наилучшие прогнозы результатов будущих событий. Таким образом, инвесторы не могут получить доходность с поправкой на риск, превышающую рыночную, торгуя на основе новой информации.
Эффективность рынка, естественно, применима ко многим видам рынков, включая рынки ставок. В связи с ростом индустрии онлайн‑ставок за последнее десятилетие ряд ученых сосредоточили свое внимание на рынках ставок, в частности, потому, что они представляют собой своего рода «лабораторию реального мира», где эффективность может быть исследована простым способом (см., например, основополагающую статью Thaler & Ziemba, 1988, и всеобъемлющее исследование. обзор финансовых рынков и рынков ставок, подготовленный Vaughan Williams, 2005). На самом деле, в отличие от финансовых рынков, участники рынка ставок, как правило, хорошо информированы, мотивированы и опытны, а последние новости в спорте обычно сообщаются четко и в такой форме, чтобы агентам было легко делиться ими и обрабатывать. Другими словами, существует очень мало возможностей для утечки информации, которая влияет на эффективность финансовых рынков. (Forrest and Simmons, 2000) показывают, что частная или полуобщественная информация, которой могут располагать профессиональные информаторы английских газет, лишь незначительно улучшает прогнозы результатов матчей и что нет убедительных доказательств того, что прогнозы результатов матчей с помощью регрессионных моделей хуже, чем у профессиональных экспертов, которые утверждают, что владеют инсайдерской информацией. Более того, Spann и Skiera (2009) показывали, что для немецкой бундеслиги коэффициенты букмекеров более точны, чем прогнозы экспертов. Однако недавно Brown and Reade, (2017) обнаружили, что опросы информаторов предоставляют дополнительную прогнозирующую точность, помимо цен букмекерских контор, а Brown, Rambaccussing, Reade и Rossi, (2017) показали, что твиты в Twitter содержат информацию, которая не учитывается в ценах на ставки в режиме реального времени. Кроме того, ставки характеризуются точным сроком, по истечении которого их стоимость становится определенной, что значительно упрощает проверку рыночной эффективности.
Эффективность рынка ставок подразумевает, что рыночные цены (т. е. коэффициенты букмекеров) отражают всю соответствующую историческую информацию и представляют собой наилучшие прогнозы вероятностей исходов матчей. Поэтому после учета комиссий букмекеров игроки не могут преследовать возможности получения прибыли, поскольку вся доступная информация уже отражена в котировках. Тем не менее, Angelini and De Angelis (2017), Boshnakov, Kharrat, and McHale (2017), Dixon and Pope (2004), Goddard and Asimakopoulos (2004) and Koopman and Lit (2015), среди прочих, показывают аномальную положительную доходность на тестовой выборке от стратегий ставок, основанных на эконометрических подходах; в частности, Пуассона, ordered probit, динамического пространства состояний, двумерного Вейбулла (bivariate Weibull count) и авторегрессионных моделей Пуассона соответственно. Поскольку эти методы используют информацию о результатах прошлых матчей, их результаты подразумевают неэффективность рынка ставок. Более того, модели прогнозирования, которые дают аномально положительную доходность, были предложены для других видов спорта, включая американский футбол (Boulier & Stekler, 2003; Glickman & Stern, 1998), теннис McHale & Morton, 2011), скачки (Lessmann, Sungb, & Johnson, 2010) и австралийский футбол (Grant & Johnstone, 2010; Rydall & Bedford, 2010).
Тема эффективности рынка ставок была довольно широко разработана в литературе, но существуют неоднозначные эмпирические данные относительно степени эффективности рынков ставок. В частности, эффективность результатов матчей «победа‑ничья‑проигрыш» на рынках ставок на футбол все еще остается открытым вопросом. Насколько нам известно, в современной литературе отсутствуют работы, которые формально проверяли бы эффективность рынков ставок на онлайн‑футбол. Единственные известные нам исследования, которые строго проверяют эффективность рынка в результатах матчей «победа‑ничья‑проигрыш» в футболе, — это исследования Kuypers (2000) и Pope and Peel (1989). В частности, Pope and Peel (1989) предложили подход, основанный на линейной вероятности и логит‑моделях, для проверки эффективности рынка ставок в футбольном сезоне 1981/1982 в Великобритании. Их выводы свидетельствуют об отсутствии предвзятости в процессах установления коэффициентов букмекером для домашних и выездных побед, и, следовательно, невозможно определить прибыльную стратегию ставок. Используя регрессию OLS между вероятностью исхода и вероятностью, подразумеваемой коэффициентами, Kuypers (2000) пришел к выводу, что не было систематического смещения в коэффициентах и что рынок был слабоэффективен в сезонах 1993/1994 и 1994/1995 четырех дивизионов английской футбольной лиги. Однако Kuypers (2000) обнаружил редкое возникновение как неэффективности, так и прибыльных возможностей ставок, если использовалась упорядоченная логит‑модель с общедоступными информационными переменными. В отношении этих исследований мы предлагаем инновационный подход, в котором мы моделируем ошибки прогноза букмекера, чтобы формально проверить эффективность рынка, с учётом комиссий букмекера. Более того, наш анализ рассматривает больший размер выборки с точки зрения как временного интервала, так и количества футбольных лиг, а также с точки зрения охвата рынка ставок, поскольку Kuypers (2000) и Pope and Peel (1989) рассматривали только одну страну и одного и четырех букмекеров соответственно.
В этой статье исследуется степень эффективности европейских рынков онлайн ставок на футбол путем тестирования предсказуемости результатов футбольных матчей на основе информации, содержащейся в коэффициентах, предлагаемых на рынке. В частности, мы тестируем эффективность рынков онлайн ставок на футбол, связанных с отдельными европейскими высшими лигами, чтобы исследовать возможные различия в степени (не)эффективности рынка среди национальных клубных соревнований в Европе. Мы достигаем этой цели, рассматривая набор данных, который включает коэффициенты, предлагаемые 41 международным букмекером на 11 лиг за последние 11 лет (2006–2017), для 33 060 футбольных матчей.
Одним из известных отклонений от беспристрастности (а иногда и от эффективности) является смещение фаворита‑аутсайдера, которое утверждает, что коэффициенты на фаворитов более прибыльны, чем коэффициенты на аутсайдеров; т. е. букмекеры склонны недооценивать (переоценивать) ожидаемых победителей (аутсайдеров) (см. обзор Sorensen & Ottaviani, 2008). Это смещение хорошо документировано на рынках ставок на ипподромах, но не на других рынках ставок на спорт; например, Woodland and Woodland, (1994), Woodland and Woodland, (2001) показывают, что рынки ставок на матчи Главной лиги бейсбола и Национальной хоккейной лиги демонстрируют противоположное смещение. Используя только информацию, содержащуюся в коэффициентах, и не полагаясь на какую‑либо эконометрическую модель, Direr (2013) показал, что систематический выбор коэффициентов ставок на подавляющих фаворитов (вероятность победы которых превышает 90%) приводит к аномальным положительным доходам. Его доказательства, по‑видимому, противоречат гипотезе эффективности рынка и согласуются с литературой, которая документирует наличие предвзятости фаворита‑аутсайдера на рынках ставок. Наоборот, используя высокочастотные данные, предоставленные онлайн‑биржей ставок, Croxson and Reade (2014) проверили эффективность рынка, на голы, в течение последних пяти минут первой половины матча. Их результаты показывают, что цены обновляются быстро и полностью, так что новость о голе полностью учитывается к моменту второго тайма.
Эмпирические данные свидетельствуют о том, что коэффициенты ставок являются наиболее точным источником спортивных прогнозов. В соответствии с этой литературой мы рассматриваем вероятности, предоставляемые коэффициентами онлайн‑рынка, как «лучшие» доступные прогнозы результатов матчей и анализируем ошибки прогноза для проверки эффективности, специфичной для рынка, в рамках нулевой гипотезы эффективности рынка.
Наши основные выводы показывают, что все рынки эффективны и могут позволить букмекерам получать дополнительную прибыль только в том случае, если используются средние рыночные коэффициенты. И наоборот, если рассматривать максимальные коэффициенты, предлагаемые рынком, мы находим доказательства трех европейских лиг, где смещение фаворит‑аутсайдер достаточно велико, чтобы создавать прибыльные возможности для игроков.
Эта статья организована следующим образом. Раздел 2 описывает подход к тестированию эффективности рынка. Раздел 3 анализирует степень эффективности рынка для 11 европейских лиг. В частности, Раздел 3.1 описывает данные, Раздел 3.2 представляет результаты тестов эффективности рынка, а Раздел 3.3 исследует последствия неэффективности рынка, представляя простую, но прибыльную стратегию ставок. В разделе 4 выводы.

2. Тестирование эффективности онлайн-рынков ставок на футбол
Пусть

— дихотомическая переменная, которая принимает значение единицы, если матч i заканчивается с рассматриваемым результатом, т.е. победой хозяев поля, ничьей или победой гостей. Затем переменная

распределяется как величина Бернулли с (истинной) вероятностью

, т.е.

, где

обозначает гипотетический информационный набор, содержащий всю информацию во Вселенной. Значительная часть литературы по спортивному прогнозированию подтверждает эмпирические данные о том, что коэффициенты ставок являются наиболее точным источником данных для прогнозирования вероятностей исходов матчей (см., например, Strumbelj & Sikonja, (2010); Štrumbelj, (2014)). В связи с этим коэффициенты, указанные на рынке онлайн-ставок, представляют собой «наилучшие» доступные прогнозы вероятности исхода матча

(ex ante). Пусть

— коэффициент букмекера на конкретный исход матча i (например, победа хозяев), а

— соответствующий предполагаемый прогноз вероятности. Следовательно, вероятностный прогноз букмекера должен быть равен

, где

— это (фактический) набор информации, доступный букмекерам на матч

. Однако букмекерские конторы не предлагают справедливых коэффициентов, поскольку коэффициенты также должны включать комиссию букмекера или маржу, также известную как «vig». Таким образом, вероятностный прогноз букмекера, который де-факто используется для определения коэффициентов, предлагаемых на рынке, равен

, где

— комиссия букмекера. Как следствие,

не являются реальными вероятностями, поскольку их сумма по всем возможным исходам превышает единицу. При рассмотрении наилучших коэффициентов, предлагаемых рынком, могут возникать случаи, когда сумма обратных коэффициентов меньше единицы, и такие случаи предоставляют игрокам возможность арбитража. Возможности арбитража очень редки, если рассматривать только онлайн-букмекерские конторы. Vlastakis, Dotsis, and Markellos (2009) пришли к выводу, что менее чем в одном матче на 1000 матчей возможны арбитражные решения на рынках онлайн-ставок. Однако они также показывают, что это соотношение увеличивается до незначительных 0,5%, если учитывать как онлайн-ставки, так и ставки букмекеров. Арбитражные позиции также могут быть достигнуты путем объединения ставок на биржевых рынках и в онлайн-букмекерских конторах (Franck, Verbeek, & Nüesch, 2013).
Поскольку комиссия букмекера

, как правило, не является фиксированной и может меняться в зависимости от матча, между букмекерами и с течением времени, одним из популярных способов обойти эту проблему является нормализация коэффициентов, то есть деление обратных коэффициентов на сумму обратных коэффициентов. Однако при таком подходе подразумевается, что букмекеры пропорционально увеличивают свою маржу на все возможные исходы. Более того, несмотря на то, что существуют более сложные методы определения вероятностных прогнозов на основе коэффициентов ставок (см., например, Штрумбель, 2014), Левитт (2004) показывают, что букмекеры устанавливают свои коэффициенты таким образом, чтобы использовать предвзятость игроков, и, таким образом, подразумеваемые вероятности будут отличаться от ожидаемых даже после нормализации. В частности, в отношении американского футбола в НФЛ Левитт (Levitt, 2004) приводит доказательства способности букмекеров устанавливать коэффициенты и приходит к выводу, что они лучше, чем игроки, предсказывают исход матча. Тем не менее, коэффициенты, предлагаемые букмекерскими конторами, систематически отклоняются от ожидаемых, поскольку они направлены на то, чтобы использовать предубеждения игроков и таким образом получать дополнительную прибыль. Аналогичный аргумент приводит Кайперс (Kuypers, 2000).
Пусть

— ошибка прогноза букмекера на исход матча

. Согласно нулевой гипотезе рыночной эффективности, мы имеем, что, в общем случае,

переоценивает

, т.е.

и, как следствие, условное математическое ожидание

не равно нулю, а равно (за вычетом) комиссии букмекера и возможных искажений цен, возникающих в результате использование предвзятости игрока, делающего ставку, т.е.

.
Таким образом, рыночная эффективность для лиги

может быть оценена с помощью следующей модели:

где

— количество матчей, проведенных в лиге

, а

— фиктивная переменная, которая принимает значение, равное единице, для сезона

и равное нулю в противном случае, для

, так что

отражает среднюю комиссию букмекера для j-й лиги в сезоне 1 (как референс) и при

, для

отражает возможное изменение маржи букмекерской конторы с течением времени. Так как коэффициент регрессии

в уравнении (1) отражает возможное влияние вероятности

на ошибку прогноза

, рыночная эффективность лиги

может быть оценена путем исследования ее статистической значимости. Более конкретно, если учесть комиссионные букмекера, которые измеряются коэффициентами

в уравнении (1), эффективность рынка будет означать, что условное математическое ожидание

равно нулю, так что отклонение нулевой гипотезы

будет означать, что рынок

не является беспристрастным. Обратите внимание, что настройки, используемые в Eq. (1) для проверки эффективности рынков ставок используется стандартная методика тестирования эффективности прогнозирования, разработанная Mincer and Zarnowitz (1969); т.е. при гипотезе эффективного рынка и в случае отсутствия комиссии букмекера

независимо от регрессора относится к информационному набору

, который мы могли бы включить в спецификацию модели; см. также Clements and Reade (2016). В дополнение к этому, «кривые эффективности», описанные в разделе 3.2, позволяют нам оценить, достаточно ли велика эта погрешность, чтобы покрыть комиссионные букмекера и использовать прибыльную стратегию ставок, основанную на прошлых коэффициентах. Если это так, то рынок

неэффективен. Более того, включение фиктивных переменных для каждого сезона в спецификацию модели в уравнении (1) позволяет нам как проверить, не зависит ли маржа букмекера от времени, так и зафиксировать ее возможную эволюцию с течением времени.
Ioannidis and Peel (2005) показывают, что ошибки прогноза могут проявлять гетероскедастичность при нулевой рыночной эффективности. Мы учитываем эту возможность, получая оценку уравнения (1) с помощью взвешенных наименьших квадратов (WLS), где весовая матрица

является диагональной с элементами

. В нашей схеме

может быть приблизительно равно

. Более того, поскольку мы рассматриваем коэффициенты на победу хозяев и гостей в уравнении совместно (1), мы избегаем вопроса о возможных корреляциях между наблюдениями, рассматривая кластерно-устойчивую оценку ковариационной матрицы WLS, где кластеры состоят из (двух) наблюдений, относящихся к одному и тому же совпадению; более подробную информацию см. в Liang and Zeger (1986).
В следующем разделе мы исследуем степень эффективности европейских рынков онлайн-ставок.
3. Результаты
3.1. Данные
Данные, использованные в этой статье, взяты с сайта football-data.co.uk, большой базы данных результатов европейских футбольных матчей и фиксированных коэффициентов, где коэффициенты учитываются в пятницу во второй половине дня для матчей выходного дня и во вторник во второй половине дня для матчей в середине недели. Эти данные включают коэффициенты, предлагаемые 41 международной онлайн-букмекерской конторой, рассмотренной порталом BetBrain (www.betbrain.com (http://www.betbrain.com/)) на футбольные матчи, сыгранные в 11 главных европейских лигах за период с августа 2006 по февраль 2017 года, в общей сложности на 33 060 матчей. В ходе анализа были рассмотрены следующие лиги: Английская Премьер-лига, Шотландская Премьер-лига, немецкая Бундеслига, Итальянская Серия А, турецкая Суперлига, португальская Премьер-лига, Французская Лига 1, Испанская Лига, греческая Суперлига, голландская Eredivisie и бельгийская Jupiler League. Для каждого матча мы учитываем как средние, так и максимальные коэффициенты, предлагаемые рынком. Размеры выборки (

), которые указаны в последней строке таблиц 2 и 3 для каждой лиги, довольно велики, так что должна быть достигнута теоретическая сходимость к нормальному распределению (сумм) переменных Бернулли.
Pope and Peel (1989) показали, что вариабельность вероятности ничьей очень мала и что коэффициенты ничьей не имеют существенного прогностического значения. Анализ ничьих, проведенный на основе нашего набора данных, подтвердил выводы Поупа и Пила (Pope and Peel, 1989), которые не выявили существенной взаимосвязи между коэффициентами на ничью и исходами во всех рассмотренных лигах. Поэтому в дальнейшем мы будем моделировать коэффициенты на победу хозяев и гостей совместно и не будем учитывать ничьи.
Наш анализ также фокусируется на отклонении от объективности, обусловленном предвзятостью в пользу фаворита, что является эмпирической закономерностью, задокументированной на многих рынках ставок на спорт, как обсуждалось в разделе 1.
3.2. Эффективность европейских онлайн-рынков ставок на футбол
В этом разделе проверяется эффективность рынков онлайн-ставок для 11 основных европейских футбольных лиг, перечисленных в разделе 3.1.
Если рынки ставок эффективны, то условное математическое ожидание ошибок прогноза должно быть равно минус комиссионные букмекера. Следовательно, исходя из оценки Eq. (1) для

-й лиги мы ожидаем, что (i) оценка для

может быть (значительно) отрицательной, поскольку этот параметр отражает маржу букмекера, и (ii) мы не будем отвергать нулевую гипотезу

. Результаты оценки моделей, приведенных в уравнении (1), представлены в таблицах 2 и 3 для средних и максимальных коэффициентов соответственно.
Прежде чем сосредоточиться на результатах оценки, мы сначала проверим предположение о том, что истинная вероятность является линейной функцией вероятности букмекерской конторы, как следует из уравнения (1). 3 В частности, в таблице 1 мы рассматриваем набор повторных тестов Рэмси для определения ошибок функциональной формы. Результаты этих тестов показывают, что в целом модели в уравнении (1) указаны правильно, и, таким образом, нет необходимости применять спецификацию нелинейной модели. Однако следует отметить, что некоторые признаки нелинейности обнаружены для Англии (квадраты и кубы) и Италии (только квадраты) на уровне значимости 5% (но не 1%).

Таблица 1. p-value для тестов Рэмси для нулевой гипотезы о том, что уравнение (1) указано правильно (без ошибки в определении функциональной формы) для всех рассмотренных лиг.
Результаты, приведенные в таблице 2, показывают, что, учитывая среднее значение коэффициентов, предлагаемых 41 онлайн-букмекерской конторой, мы не отвергаем нулевую гипотезу об эффективности рынка ни для одной из лиг, за исключением итальянской Серии А и португальской Премьер-лиги, уровень значимости которых составляет 5%, а также греческой Суперлиги, даже находящейся на низком уровне. уровень значимости — 1%. Довольно удивительно, но мы находим свидетельства отрицательного тренда в немецкой Бундеслиге и голландской Eredivisie, хотя они и незначительны. Все остальные коэффициенты регрессии (включая незначительные) положительны, что означает, что в среднем ошибка прогноза букмекера имеет тенденцию к увеличению по мере увеличения вероятности прогноза. Это согласуется с известным принципом «favourite‑longshot bias», который мы исследуем ниже.
Результаты для оценок

, представленные в таблице 2, показывают, что, как и ожидалось, все они отрицательные. Сосредоточившись на

, мы видим, что некоторые из этих фиктивных переменных значимы, по крайней мере, на уровне 5%, и положительны.Это является (слабым) свидетельством того, что комиссия букмекерской конторы снизилась по сравнению с выборкой, что может быть связано с возросшим уровнем конкуренции на рынках онлайн-ставок. Однако из результатов F-тестов для (совместных) нулевых гипотез

, представленных в таблице 2, мы можем сделать вывод, что на самом деле комиссионные существенно не менялись с течением времени.Данные о комиссионных, не зависящих от времени, в нашей выборке согласуются с выводами Forrest et al. (2005, таблица 4), которые обнаружили, что, хотя цены букмекеров становились более точными с ростом коммерческого давления, их доходность оставалась относительно постоянной в период с 1998 по 2003 год.

Таблица 2. Оценки моделей в уравнениях (1) и (2), когда мы рассматриваем среднее значение коэффициентов, предлагаемых на рынке ставок.
Примечания: в скобках указаны p-значения. F -тест означает тесты Вальда для ограничения H_0: \alpha_2 = · · · = \alpha_10 = 0 (указаны p-значения). T-тест для \hat\alpha является односторонним H_1:\alpha < 0. В последней строке указано количество матчей, сыгранных N_j в каждой лиге.
*** значимость на уровне 1%.
** значимость на уровне 5%.
* значимость на уровне 10%.Поэтому мы улучшаем эффективность теста, упрощая модель в уравнении (1), вводя ограничение не зависящие от времени, и переоцениваем следующую модель:

Мы приводим результаты для уравнения. (2) в нижней части таблицы 2. Мы обнаружили, что в среднем комиссия букмекерской конторы значительно ниже нуля, по крайней мере, на уровне значимости 5%, для всех лиг, за исключением Германии, и колеблется от 2,19% (Испания) до 5,24% (Португалия). Ограниченная модель в уравнении (2) не влияет на результаты тестов на объективность с точки зрения значимости коэффициентов регрессии и последствий наличия признаков отклонения от объективности в Италии, Португалии и Греции, что может свидетельствовать о неэффективности рынка, как мы проанализируем ниже.
В принципе, при любой возможности игроки, делающие ставки, стремятся выбрать наилучшую цену, которую может предложить рынок. Поэтому интересно оценить степень эффективности рынка при рассмотрении максимальных коэффициентов (вместо средних коэффициентов). В таблице 3 представлены результаты по лучшим коэффициентам, доступным среди 41 букмекерской конторы, которые мы рассматриваем. Как и в случае со средними коэффициентами (см. таблицу 2), мы не находим свидетельств изменяющихся во времени пересечений, и поэтому мы рассматриваем ограниченную модель в уравнении (2). По сравнению со средними коэффициентами, результаты, приведенные в таблице 3, показывают, что игроки, делающие ставки, могут существенно снизить комиссионные букмекерской конторы, учитывая максимальные коэффициенты, предлагаемые рынком, поскольку только три лиги показывают значительные (отрицательные) оценки

, а именно Италия, Португалия и Греция. Опять же, эти результаты согласуются с выводами Forrest et al. (2005, таблица 4), которые показывают, что комиссия практически исключается при использовании наилучших доступных коэффициентов. Для тех же трех лиг мы также находим свидетельства значительных оценок

на уровне значимости не менее 5%, что эти рынки не являются беспристрастными, как это было обнаружено в случае средних коэффициентов.

Таблица 3. Оценки моделей в уравнениях (1) и (2), когда мы рассматриваем максимальные коэффициенты, предлагаемые на рынке.
Примечания: в скобках указаны p-value. F -тест означает тесты Вальда для ограничения
(указаны p-значения). T-критерий для \hat\alpha является односторонним

. В последней строке указано количество матчей, сыгранных

в каждой лиге.
*** значимость на уровне 1%.
** значимость на уровне 5%.
* значимость на уровне 10%.Теперь мы оцениваем степень объективности рынка и достаточно ли велики какие-либо отклонения, чтобы обеспечить выгодные возможности для игроков, делающих ставки, что, в свою очередь, означает неэффективность рынка. В частности, мы учитываем значения, полученные на основе оценки моделей в уравнении (2) для всех возможных значений вероятности и для j-й лиги выводим следующее выражение, которое мы называем «кривой эффективности»:

где

и

— оценки параметров в формуле (2), а соответствующие доверительные интервалы вычисляются следующим образом
![CI_j = [ \hat G_j (p_G) - z_{\alpha/2} s.e. (\hat G_j(p_G)), \hat G_j(p_G) + z_{\alpha/2} s.e.(\hat G_j(p_G)) ], \ \ \ \ (4)](https://external.gipsyteam.ru/index.php?path=https%3A%2F%2Fhabrastorage.org%2Fgetpro%2Fhabr%2Fupload_files%2Fb24%2F037%2F771%2Fb2403777191495e0ddcbf8b4f8fdf8be.svg "Нажмите для просмотра полного изображения")
где s.e.
![(\hat G_j(p_G)) = [ \bigtriangledown \hat G(p_G)' V_{WLS} \bigtriangledown \hat G(p_G) ]](https://external.gipsyteam.ru/index.php?path=https%3A%2F%2Fhabrastorage.org%2Fgetpro%2Fhabr%2Fupload_files%2Fc29%2F5cd%2F555%2Fc295cd555241db47dff3b1ed6c9f0f3a.svg "Нажмите для просмотра полного изображения")
,

ый процентиль стандартного нормального распределения,

— градиент,

— дисперсия оценки WLS.
На рис. 1 и 2 показаны кривые эффективности

в уравнении (3) для каждой лиги в сравнении с

для среднего и максимального коэффициентов соответственно. При фиксированном значении

, скажем,

означает беспристрастность рынка. И наоборот, когда

, есть признаки предвзятости, и знак

указывает на то, какая сторона может извлечь выгоду из этой предвзятости. В частности,

будет означать неэффективность рынка, поскольку игроки, делающие ставки, могут получать положительную прибыль, в то время как

будет означать прибыль для букмекерских контор. Таким образом, мы сосредоточимся на случаях с

, чтобы исследовать неэффективность рынка.

Рисунок 1. Кривые эффективности

из уравнения (3) и соответствующие 95%-ные доверительные интервалы из уравнения (4), рассчитанные с учетом среднего значения коэффициентов, предлагаемых рынком ставок.

Рисунок 2. Кривые эффективности

из уравнения (3) и соответствующие 95%-ные доверительные интервалы из уравнения (4), рассчитанные с учетом максимального коэффициента, предлагаемого рынком ставок.
Кривые эффективности, показанные на рис. 1, показывают, что для всех лиг, за исключением немецкой Бундеслиги и голландской Eredivisie,

имеет тенденцию к увеличению по мере увеличения вероятности исхода

, поскольку

. Таким образом, мы находим доказательства того, что рыночные вероятности проигравших (фаворитов) в среднем завышают (занижают) их эмпирические вероятности. Это означает, что ставки на аутсайдеров занижены и что игрокам выгоднее делать ставки на фаворитов. Мы можем интерпретировать эти результаты как свидетельство в пользу предвзятого отношения к фавориту. Однако, как видно из рис. На рис. 1 все кривые эффективности находятся ниже нулевой линии, за исключением случая наибольших значений

для Италии, Португалии и Греции. Аналогичным образом, соответствующие доверительные интервалы, которые показаны на рис. 1 для уровня достоверности 95%, показывают, что никаких значимых положительных значений

достичь не удается. Эти эмпирические данные свидетельствуют о том, что игроки не могут систематически получать положительную прибыль и что букмекерские конторы получают прибыль в долгосрочной перспективе, особенно от ставок на аутсайдеров. И наоборот, в немецкой Бундеслиге букмекеры, по-видимому, получают прибыль от фаворитов, а не от дальних бросков. Эти эмпирические данные (хотя и незначительные) свидетельствуют о том, что в Германии наблюдается своего рода обратное смещение фаворит-аутсайдер. Интересно, что в случае с голландским Eredivisie букмекерские конторы, похоже, получают значительную прибыль практически при любом значении коэффициента

. Таким образом, несмотря на наличие предубеждений, рынки онлайн-ставок считаются эффективными, если учитывать средние коэффициенты.
3.3 Последствия неэффективности рынка: простая и прибыльная стратегия ставок
В этом разделе предлагается стратегия ставок, направленная на использование неэффективности рынка, описанной в предыдущем разделе. На рисунке 2 показано, что кривые эффективности в уравнении (3) являются значительно положительными для трех европейских рынков онлайн-ставок при выборе максимальных коэффициентов, предлагаемых рынком. Действительно, как обсуждалось в разделе 3.2, итальянская и греческая лиги показывают положительные значения

, связанные с наибольшими вероятностями

(сторона с меньшими коэффициентами), в то время как для Испании мы имеем

для центральных значений

. Нашу стратегию ставок в лиге

можно резюмировать следующим образом:
Оцените модель в уравнении (2) с помощью

, как описано в разделе 2, рассматривая наблюдения до сезона T* как информационный набор

:

где

- количество матчей, сыгранных в

-й лиге в сезонах

.
Используя результаты, полученные на шаге 1, вычислите кривую эффективности перехода лиги в сезон T следующим образом:

и соответствующие доверительные интервалы, такие как
![CI_j^* = [ \hat G_j^* (p_G) - z_{\alpha / 2} s.e.( \hat G_j^* (p_G) ), \hat G_j^* (p_G) + z_{\alpha / 2} s.e.( \hat G_j^* (p_G) ) ]. \ \ \ \ (7)](https://external.gipsyteam.ru/index.php?path=https%3A%2F%2Fhabrastorage.org%2Fgetpro%2Fhabr%2Fupload_files%2Ff63%2Fb35%2Fe14%2Ff63b35e14a9883f7d318f18707b69f07.svg "Нажмите для просмотра полного изображения")
Определите "диапазон вероятности получения прибыли" как

, где

обозначает нижнюю границу доверительного интервала в уравнении (7), пороговые вероятности как нижнюю и верхнюю границы диапазона вероятности получения прибыли, т.е.

и

, и соответствующие пороговые
коэффициенты

и

.
Систематически делайте ставки на все матчи лиги

, коэффициенты на которые находятсяв «диапазоне выгодных коэффициентов»,
![O_j^*= [ o_j^{*(L)}, o_j^{*(U)} ]](https://external.gipsyteam.ru/index.php?path=https%3A%2F%2Fhabrastorage.org%2Fgetpro%2Fhabr%2Fupload_files%2F8a0%2Fe59%2F437%2F8a0e59437f1e421243ab24e74c98ded8.svg "Нажмите для просмотра полного изображения")
либо на все сезоны после T* (out-of-sample), либо на все сезоны в выборке (in-sample forecast).
Мы применяем вышеуказанную стратегию ставок для оценки результатов прогнозирования как в выборке (ex post), так и вне выборки (ex ante). Обратите внимание, что наш подход позволяет оценить диапазон выгодных коэффициентов, а не выбирать его произвольно, как в предыдущих анализах (см., например, Direr, 2013). Результаты представлены в таблице 4.

Таблица 4a. Прогнозируемая эффективность стратегии ставок in-sample, описанной в разделе 3.3.

Таблица 4б. Прогнозируемая эффективность стратегии ставок out-of-sample, описанной в разделе 3.3.

Таблица 4в. Кривые эффективности

из уравнения (6) (синие линии) и соответствующие 95%-ные доверительные интервалы, используемые при (out-of-sample) прогнозировании стратегии ставок, описанной в разделе 3.3. прогноз по выборке, рассчитанный в соответствии с уравнением (7).
Сначала мы сосредоточимся на прогнозе по выборке, который учитывает весь доступный набор информации, т.е.

. Результаты в верхней части таблицы 4 показывают, что стратегия ставок обеспечивает положительную среднюю доходность для всех трех европейских лиг, которые в разделе 3.2 были признаны неэффективными. В частности, систематически делая ставки с коэффициентами ниже 1,67 и 2,08, мы получаем среднюю доходность в 2,09% и 2,71% на Итальянскую Серию А и греческую Суперлигу соответственно, в то время как ставки на матчи испанской лиги с коэффициентами в диапазоне 1,09–3,12 дают среднюю доходность в 2,12%.
Далее мы исследуем, можно ли получить сверхнормативную прибыль, используя предложенную стратегию ставок. Мы оцениваем эффективность out-of-sample прогнозирования, устанавливая

в качестве out-of-sample. Мы продлили период выборки, включив в него также конец сезона 2016/17 (то есть матчи, сыгранные с марта по июнь 2017 года). На графиках, представленных в таблице 4в, показаны кривые эффективности

для всех лиг с соответствующими 95%-ными доверительными интервалами

, рассчитанными согласно уравнениям (6) и (7) соответственно. Из этих рисунков мы видим, что, в соответствии с результатами, полученными выше, для восьми эффективных лиг или Италии не найдено выгодного диапазона вероятности при рассмотрении

в качестве out-of-sample; т.е. предполагаемая нижняя граница доверительного интервала

находится ниже нулевой линии для всех значений

. И наоборот, для Греции и Испании существуют значения

, для которых выполняется условие

. Следовательно, следуя шагам 3 и 4 нашей стратегии размещения ставок, мы вычисляем диапазон прибыльных вероятностей

и соответствующий диапазон прибыльных коэффициентов

(таблица 4б). Мы отмечаем, что в греческой Суперлиге и Испанской лиге игроки могут получить прибыль, делая ставки на исходы матчей с коэффициентами ниже 2,30 и 3,22, что эквивалентно, подразумеваемыми вероятностями, превышающими 0,4348 и 0,3105 соответственно. Результаты, представленные в таблице 4б, показывают, что средние показатели отдачи положительны для обеих лиг. В частности, out-of-sample (т.е. в течение всего сезона 2016/17) стратегия ставок обеспечивает среднюю доходность в 1,35% и 2,25% для Греции и Испании соответственно.

4. Заключение
За последние десятилетия рынки онлайн‑ставок развивались и процветали, и интерес ученых к изучению характеристик этих рынков возрос. В данной статье рассматривается степень эффективности рынка онлайн‑ставок на европейский футбол с использованием большого объема данных. Учитывая средние рыночные коэффициенты, мы предоставляем доказательства того, что рынки онлайн‑ставок являются (в слабой степени) эффективными и что любые выявленные искажения приносят дополнительную прибыль букмекерским конторам. Однако, благодаря высококонкурентному рынку, игроки, делающие ставки, могут выбирать между многими букмекерскими конторами и выбирать лучшие коэффициенты, предлагаемые рынком. Повторив анализ с использованием максимальных коэффициентов, мы пришли к выводу, что большинство рынков онлайн‑ставок эффективны, но мы также находим свидетельства неэффективности, которые можно использовать для определения прибыльных стратегий ставок. В частности, наш анализ показывает, что одно из самых распространенных отклонений от объективности на рынках ставок — предвзятое отношение «фаворит‑аутсайдер» — действительно присутствует на трех европейских футбольных рынках. Мы показываем, что простая стратегия ставок, использующая эту предвзятость, приводит к аномально положительным результатам для игроков, делающих ставки, с учетом комиссионных букмекерской конторы. Более того, наши результаты показывают, что комиссионные онлайн‑букмекеров существенно не менялись с течением времени в период с 2006 по 2017 год, но, по‑видимому, различаются в зависимости от лиги.
_________________________________________________============================______________________________________
_______cappelchi13 июн 2025 в 17:01
Прогнозирование исходов футбольных матчей в реальном времени с помощью байесовской модели
Сложный
26 мин
2.2K
Статистика в ITМатематика*Исследования и прогнозы в IT*Машинное обучение*Финансы в IT
Перевод
Модели точечных процессов внесли значительный вклад в прогнозирование исходов футбольных матчей. Традиционно предполагается, что атакующие и оборонительные способности команд остаются постоянными в течение матча и оцениваются на среднем качестве игры всех других команд за прошлые периоды. В данной статье, опираясь на байесовский подход, предлагается модель динамической силы, которая снимает предположение о постоянстве силы команд и позволяет использовать информацию о текущем матче для их калибровки. Эмпирическое исследование показывает, что, хотя байесовская модель не улучшает прогнозирование разницы голов, она демонстрирует значительные успехи в прогнозировании общего количества голов и исходов матча (победа/ничья/поражение). При ставках на азиатских гандикапах, победы/ничьи/поражения и тоталы, байесовская модель может приносить положительную доходность; это явно контрастирует с моделью точечного процесса с постоянной силой, которая не способна обыграть букмекера.
1. Введение
Футбол — самый популярный вид спорта в мире, и ставки на его исходы имеют давнюю традицию. Кроме того, футбол представляет собой самый быстрорастущий рынок азартных игр. В результате моделирование и прогнозирование исходов футбольных матчей становятся всё более популярными. Прогнозирование исхода отдельного матча — сложная задача, которая делится на два типа: предматчевое прогнозирование и прогнозирование в реальном времени.
Предматчевое прогнозирование ранее использовало модель отрицательного биномиального распределения для футбольных результатов вместо модели Пуассона. Однако после ключевой статьи Махера [Maher1982] анализ данных на основе пуассоновского распределения голов, в котором результаты матчей определяются параметрами атаки и защиты двух команд, получил широкое распространение. Кроме того, поскольку пуассоновская модель применима только в случаях, когда данные однородны во времени и равномерно распределены, МакШейн [McShane2008] предложил модель, основанную на временах между событиями с распределением Вейбулла, которая способна обрабатывать как недостаточно разрозненные данные, так и чрезмерно разрозненные данные. Бошнаков и др. [Boshnakov2017] применили модель Вейбулла для прогнозирования футбольных результатов, и результаты показали, что она работает лучше, чем пуассоновская модель.
Ставки в реальном времени очень популярны, и поэтому прогнозирование в реальном времени заслуживает особого внимания. Однако среди огромного количества литературы по прогнозированию футбольных матчей лишь немногие статьи сосредоточены на прогнозировании в реальном времени. Диксон и др. [Dixon1998] разработали модель, где процессы времени голов домашней и гостевой команд считаются двумя неоднородными пуассоновскими процессами. Чтобы соответствовать практическим условиям, Цзоу и др. [Zou2018] предложили модель марковской цепи с дискретным временем и конечным числом состояний, основанную на пуассоновских процессах, где в течение минуты не происходит более одного гола, за исключением интервалов
![(44,45]](https://external.gipsyteam.ru/index.php?path=https%3A%2F%2Fhabrastorage.org%2Fgetpro%2Fhabr%2Fupload_files%2F366%2Fb00%2F67a%2F366b0067a4c3ce4d499e84d86edd9554.svg "Нажмите для просмотра полного изображения")
и
![(89,90]](https://external.gipsyteam.ru/index.php?path=https%3A%2F%2Fhabrastorage.org%2Fgetpro%2Fhabr%2Fupload_files%2F47b%2Fe43%2F07b%2F47be4307b1c3956ccaff96bef77bfb0e.svg "Нажмите для просмотра полного изображения")
с учётом компенсированного времени, и был выведен рекурсивный алгоритм для точного расчёта вероятности исхода. Вольф [Volf2008] и Титман [Titman2015] изучали влияние других событий, таких как карточки, на матч. Вольф [Volf2008] рассмотрел полупараметрическую модель, включающую непараметрическую базовую интенсивность с регрессионной компонентой, отражающей текущее состояние матча и оборонительную силу команд-соперников. Авторы в [Titman2015] использовали восьмимерный многомерный счётный процесс в реальном времени для изучения взаимодействия между процессами футбольных событий — это не только моделировало взаимозависимость между голами домашней и гостевой команд, но и количественно оценивало влияние карточек на исход игры. Результаты показали, что выдача жёлтых карточек, по-видимому, не оказывает прямого влияния на интенсивность забития голов; напротив, красные карточки оказывают значительный негативный эффект, особенно когда гостевая команда остаётся вдесятером.
Основной недостаток модели Dixon’a заключается в том, что она не учитывает использование информации о текущем матче для обновления силы команд, то есть предполагается, что сила команд остаётся постоянной в течение матча. На самом деле модель, прогнозируя следующий счёт на основе текущего счёта в момент времени

, использует только счёт в момент времени

, что повышает точность прогнозирования. Кроме того, оценённые параметры силы команды

основаны на средней производительности против всех других команд в истории. Хотя модель, учитывающая другие события, может использовать информацию о текущем матче для калибровки интенсивности забития, прогнозирование событий часто оказывается довольно сложным.
Чтобы включить как историческую информацию о матчах, так и информацию о текущем матче в модель прогнозирования в реальном времени, мы предлагаем модель калибровки динамической силы команд, основанную на байесовском методе, которая позволяет использовать информацию о текущем матче для калибровки оценок силы каждой команды. Кроме того, мы достигаем предварительной оценки силы команд, используя историческую информацию о матчах.
Остальная часть статьи организована следующим образом. Раздел 2 описывает модель распределения голов во времени, а затем вводит байесовские выводы. Раздел 4 описывает данные, результаты оценок параметров и производительность на выборке out-of-sample. Раздел 5 описывает стратегии ставок и результаты ставок. В заключение, раздел 6 подводит итоги и предлагает направления для дальнейшей работы.
2.Модель распределения голов во времени
Перед тем как описать, как обновлять силу команд с помощью информации о текущем матче, мы сначала кратко изложим модель Диксона и Робинсона (1998) [Dixon1998]. Это базовая модель для калибровки параметров способностей команд, также известная как the pure birth process model (далее: модель процесса рождения). Основное предположение модели заключается в том, что процесс забития голов домашней и гостевой команд рассматривается как двумерный неоднородный пуассоновский процесс. Рассмотрим процесс забития голов для конкретного матча

между домашней командой

и гостевой командой

. Существуют два процесса забития голов — для голов домашней и гостевой команд с интенсивностями

и

, которые могут изменяться со временем

и в зависимости от состояния процесса. Функции интенсивности задаются следующим образом:

и

где

измеряет силу атаки (чем выше значение

, тем сильнее атака) домашней команды

;

— это сила защиты (чем меньше значение

, тем сильнее защита) гостевой команды

;

— параметр преимущества домашнего поля;

и

— параметры, определяющие интенсивность забития голов при счёте

;
![t \in [0,1]](https://external.gipsyteam.ru/index.php?path=https%3A%2F%2Fhabrastorage.org%2Fgetpro%2Fhabr%2Fformulas%2Fd%2Fdf%2Fdff%2Fdff6e05ec00b53d46e366975136d0d2e.svg "Нажмите для просмотра полного изображения")
— масштабированное время, прошедшее в течение матча;

и

отражают непрерывное изменение интенсивности со временем (далее время

в функциях интенсивности является масштабированным временем). Для матчей лиги записанная информация о матче составляет 90 минут. Матчи проводятся в два периода по 45 минут. Функция

используется для моделирования эффекта компенсированного времени. Поскольку нет данных о том, сколько компенсированного времени добавлено, времена голов в 45 и 90 минут считаются (возможно) цензурированными наблюдениями. Параметры, представляющие мультипликативную корректировку интенсивности забития в периоды
![(44,45]](https://external.gipsyteam.ru/index.php?path=https%3A%2F%2Fhabrastorage.org%2Fgetpro%2Fhabr%2Fupload_files%2Fce0%2F0a0%2F853%2Fce00a085383a2c7783df28cce5c19b54.svg "Нажмите для просмотра полного изображения")
и
![(89,90]](https://external.gipsyteam.ru/index.php?path=https%3A%2F%2Fhabrastorage.org%2Fgetpro%2Fhabr%2Fupload_files%2F104%2F242%2F92a%2F10424292a7d7f60530178c732e5b1940.svg "Нажмите для просмотра полного изображения")
, задаются следующим образом:
![\begin{align} \rho(t)=\begin{cases} \rho_1, & \text{если } t \in (44/90, 45/90]; \\ \rho_2, & \text{если } t \in (89/90, 90/90]; \\ 1, & \text{в противном случае.} \end{cases} \ \ \ (3) \end{align}](https://external.gipsyteam.ru/index.php?path=https%3A%2F%2Fhabrastorage.org%2Fgetpro%2Fhabr%2Fupload_files%2Fcb3%2Ff07%2Fb48%2Fcb3f07b48c107f1003a89577cde7ec1d.svg "Нажмите для просмотра полного изображения")
Диксон и Робинсон (1998) [Dixon1998] обнаружили, что в наиболее подходящей модели параметр

может быть определён следующим образом:

и параметр

может быть определён аналогично, где счёт составляет

в момент времени

.
Основой вывода является функция правдоподобия. Для конкретного матча

функция правдоподобия, по сути, является функцией двумерного неоднородного пуассоновского процесса, которая может быть выведена путём рассмотрения процесса как последовательности независимых времён между голами. С учётом независимого приращения процесса, если общее количество голов

в матче

больше 0, функция правдоподобия принимает следующую форму:

если голов нет, функция правдоподобия принимает следующую форму:

Наблюдаемые данные — это

, где

— масштабированное время

-го гола, а

— индикатор, равный

для гола домашней команды и

для гола гостевой команды. Кроме того, Диксон и Робинсон предположили, что результаты одного матча независимы от результатов другого матча, так что общая функция правдоподобия может быть получена путём произведения по всем матчам.
В модели необходимо оценить

параметров для

команд, что представляет собой задачу высокоразмерной нелинейной оптимизации. Для решения этой задачи мы используем алгоритм координатного спуска. Кроме того, параметры модели

непрерывно обновляются в каждом раунде — это связано с тем, что в одном раунде все команды появляются и появляются только один раз, где d — число команд. Более конкретно, мы подгоняем модель на обучающей выборке и прогнозируем исходы матчей следующего раунда. После прогнозирования мы расширяем обучающую выборку, учитывая предсказанные матчи, и перестраиваем модель. Эта процедура повторяется до тех пор, пока не будут спрогнозированы матчи последнего раунда. Для прогнозирования мы применяем рекурсивный алгоритм [Zou2018] для расчёта вероятности исхода. Кодирование модели и последующий байесовский вывод реализованы в Matlab. Байесовский анализ и симуляции методом Монте-Карло (MCMC) выполняются с использованием [Gelman2013, Ross2014].
3.Байесовский вывод
Основная идея этой статьи заключается в использовании предыдущих матчей в качестве априорной информации, а затем её обновлении с помощью информации о текущем матче. Конкретная процедура байесовского вывода показана на рисунке.

Рисунок 1. Иллюстрация процедуры прогнозирования результата. Мы оцениваем параметры с помощью модели процесса рождения с использованием исторических данных и используем байесовский метод для обновления параметров силы команд с учетом информации о матче. Затем используется рекурсивный алгоритм для вычисления вероятности результата.
За исключением параметров силы команд, другим параметрам модели назначаются априорные распределения — вырожденные распределения. Другими словами, предполагается, что эти параметры известны и постоянны для всех команд в течение одного раунда, а их значения равны оценкам, основанным на модели процесса рождения с историческими матчами. Кроме того, для моделирования характеристик, уникальных для отдельного матча, мы сначала задаём подходящие распределения для параметров силы команд, а затем калибруем их с использованием наблюдаемой информации о текущем матче, предполагая, что средние значения априорных распределений равны оценкам, основанным на модели чистого процесса рождения с историческими матчами.
3.1 Априорные распределения
Для конкретного матча, от начала до времени
![T (T \in [0,90])](https://external.gipsyteam.ru/index.php?path=https%3A%2F%2Fhabrastorage.org%2Fgetpro%2Fhabr%2Fupload_files%2F8c9%2Fe9c%2Fb42%2F8c9e9cb42b4a6339df5e18d7344f7c19.svg "Нажмите для просмотра полного изображения")
, если есть

голов, наблюдаемые данные — это

, где значение

совпадает с их значением в уравнении

; если голов нет, наблюдаемые данные — это

. Для простоты обозначим

и

как количество голов домашней и гостевой команд соответственно. Согласно функциям правдоподобия

и

, функция правдоподобия выглядит следующим образом: если общее количество голов больше

от начала до времени

, то

если голов нет от начала до времени

, то

где

,

,

,

обозначает параметр интенсивности забития голов домашней команды, который определяется совместно силой атаки и защиты двух команд, участвующих в матче,

. Аналогично,

обозначает параметр интенсивности забития голов гостевой команды,

. Стоит отметить, что в приведённой выше функции правдоподобия

является константным вектором.
Поскольку времена голов обычно записываются в целой части времени гола, т.е. записываются в минутах, интегралы могут быть заменены выражениями в замкнутой форме:

Обратите внимание, что для случая, когда общее количество голов больше 0, если

,

пропорционально функции массы вероятностей пуассоновского распределения; если

или

,

пропорционально сумме нескольких функций массы вероятностей пуассоновских распределений. Широко известно, что гамма-распределение является сопряжённым априорным распределением для пуассоновского распределения. Для удобства расчётов предполагается, что априорное распределение

формируется двумя независимыми гамма-распределениями для домашней и гостевой команд, где корреляция между ними отражается через

и

. Кроме того, копула — это широко используемый метод для изучения ассоциации или зависимости между переменными. Например, простая и почти сопряжённая копула представлена в [Lee1996]. В [Boshnakov2017] использовался счётный процесс, основанный на временах между событиями с распределением Вейбулла, и копула для создания двумерного распределения числа голов, забитых домашней и гостевой командами в матче.
Кроме того, мы предполагаем, что среднее значение априорного распределения

равно

, а среднее значение априорного распределения

равно

, где

и

— это оценки максимального правдоподобия

и

, основанные на модели чистого процесса рождения со всеми историческими матчами.
Иными словами, априорные распределения для

и

— это соответственно

и

, где

и

— параметры формы, а

и

выступают в качестве параметров масштаба. Кроме того,

,

. Тогда априорное распределение

задаётся следующим образом:

3.2 Апостериорные распределения
Байесовские выводы основаны на наблюдаемых данных, и анализы непосредственно экстраполируются из апостериорного распределения, которое предоставляет априорную и текущую информацию о текущем матче по параметрам.
Когда наблюдается информация о забитых голах от начала матча до времени

, апостериорное распределение

задаётся следующим образом:

Если общее количество голов больше 0, апостериорное распределение пропорционально:

если голов нет, то есть

, апостериорное распределение пропорционально:

Заметим, что, когда голов нет, апостериорное среднее может быть получено в краткой форме. Однако, когда общее количество голов больше нуля, апостериорное среднее получается в замкнутой, хотя и относительно сложной форме. Кроме того, при дальнейшем байесовском выводе всё ещё необходимо использовать алгоритм Метрополиса для генерации выборок из апостериорного распределения. Однако, если положить

,

пропорционально функции массы вероятностей пуассоновского распределения, и тогда апостериорное распределение будет:

что является гамма-распределением. А именно, апостериорные распределения

и

будут:


Оценки параметров

и

довольно малы, обычно меньше 0.5. Например, при

,

вносит вклад

в ожидаемое количество голов, где

.
Например, если мы наблюдали информацию о первом тайме, если не учитывать эффект

, оставшегося времени игры, мы бы недооценили ожидаемое количество голов лишь на

. Кроме того, эмпирическое исследование показывает, что если оставшееся время игры не учитывается в функции правдоподобия, это мало влияет на конечную точность прогнозирования. Когда общее количество голов больше 0, для функции правдоподобия

мы используем следующее приближение:

Таким образом, независимо от того, есть ли голы в интервале
![(0, T]](https://external.gipsyteam.ru/index.php?path=https%3A%2F%2Fhabrastorage.org%2Fgetpro%2Fhabr%2Fupload_files%2F8c3%2Fa60%2Fb51%2F8c3a60b5115c427734baf8cb813ed6af.svg "Нажмите для просмотра полного изображения")
, апостериорные распределения

и

показаны в уравнениях (15) и (16) соответственно.
В этой статье мы используем апостериорные средние как оценки силы команд, калиброванные с информацией о текущем матче. С апостериорными распределениями (14) и (15) апостериорные средние оценки равны:


соответственно. В приведённых оценках,


обозначают ожидаемое количество голов в
![[0, T]](https://external.gipsyteam.ru/index.php?path=https%3A%2F%2Fhabrastorage.org%2Fgetpro%2Fhabr%2Fupload_files%2F728%2F560%2F5a3%2F7285605a3c3b94027b07f913bb3b27c2.svg "Нажмите для просмотра полного изображения")
для домашней и гостевой команд. Мы видим, что расчёт величин

и

требует интегрирования по

и

, которые зависят от случайных значений

и

,
![t \in (0, T]](https://external.gipsyteam.ru/index.php?path=https%3A%2F%2Fhabrastorage.org%2Fgetpro%2Fhabr%2Fupload_files%2Ff4e%2F1c3%2F4db%2Ff4e1c34db7467f16cd5c55584cc40747.svg "Нажмите для просмотра полного изображения")
. Для фактического вычисления ожиданий необходимо учитывать вероятности переходов базового парного процесса рождения. Другими словами, нам нужно предсказать вероятности исходов в момент времени

, используя модель процесса рождения и рекурсивный алгоритм [Zou2018].
3.3 Выбор

и

Для дальнейшего понимания, возьмём, например, домашнюю команду, мы видим, что

Тогда относительная скорость изменения апостериорной оценки по сравнению с
априорной оценкой равна

, а

— это скорость изменения фактического количества голов по
сравнению с ожидаемым количеством голов. Если

, скорость изменения будет находиться в интервале
![\left[ \frac{1}{2} \frac{|X(T) - E_H(T)|}{E_H(T)}, \frac{|X(T) - E_H(T)|}{E_H(T)} \right]](https://external.gipsyteam.ru/index.php?path=https%3A%2F%2Fhabrastorage.org%2Fgetpro%2Fhabr%2Fupload_files%2F76b%2Fb5a%2F042%2F76bb5a042fd986f8055d2a0162472b24.svg "Нажмите для просмотра полного изображения")
.
Если

, скорость изменения оценки будет находиться в
интервале

. Чем ниже

, тем больше требуется
калибровка силы с использованием информации о текущем матче. Это позволяет установить, что параметр формы

априорного распределения определяет баланс между влиянием информации об исторических матчах («априори») и информацией о голах в текущем матче.
Существует несколько вариантов выбора параметров формы априорных распределений. Один распространённый вариант — задание дисперсии, то есть добавление следующих условий:

для домашней команды и

для гостевой команды в матче, где

и

— дисперсии

и

. В сочетании с

и

получаем

и

. Однако, поскольку дисперсии довольно малы, значения

и

почти всегда находятся в интервале (30,150) — это указывает на то, что скорости изменения оценок очень близки к нулю и не приводят к улучшениям.
Другой распространённый вариант — поиск

и

для максимизации маргинального распределения наблюдаемых данных — это известно как эмпирический байесовский подход. В эмпирических исследованиях результаты оценок показывают, что

для домашней команды составляет около 3, а

для гостевой команды — около 5. Однако в матче среднее ожидаемое количество голов для домашней и гостевой команд составляет примерно 1.6 и 1.2 соответственно. Предыдущий анализ показывает, что в течение матча скорость изменения оценки будет ниже половины скорости изменения фактического количества голов по сравнению с ожидаемым количеством голов, особенно для гостевых команд. Применяя два предыдущих варианта, можно установить, что модель будет слишком сильно акцентировать внимание на априорной информации, игнорируя наблюдаемые данные.
Теперь мы сосредоточимся на поиске параметров формы априорных распределений с целью балансировки эффектов априорной информации и новой информации о матче. По мере продвижения игры уровень информации о текущем матче увеличивается. Поэтому предпочтительно слегка калибровать силы в первом тайме и усиливать калибровку этих сил во втором тайме.
Предыдущее обсуждение предполагает, что подходящее значение

может быть

, что специфично для каждого матча, чтобы учитывать различия в качестве команд и избегать чрезмерного сжатия [Baio2010]. Поскольку ожидаемое количество голов

увеличивается по мере продвижения времени матча, скорость изменения оценки силы будет находиться в интервале

в первом тайме, а во втором тайме — в интервале

. Параметр

для гостевой
команды можно анализировать аналогично, и подходящее значение

можно установить как

.
4.Результаты
4.1. Данные
Мы получили данные о времени голов в Английской Премьер-лиге за восемь сезонов с 2009/2010 по 2016/2017 от OPTA https://www.whoscored.com/. Кроме того, мы также собрали данные о живых коэффициентах ставок от OPTA букмекера SBOBet. Данные о ставках содержат информацию о рынке тоталов, рынке форы и рынке исходов (победа дома, ничья, победа гостей). Мы получили данные о коэффициентах для 950 игр с августа 2013 по май 2015 и с января 2017 по май 2017.
4.2. Оценки параметров
В этом разделе мы обсуждаем оценки параметров. Таблица 1 показывает оценки и стандартные ошибки параметров, которые предполагаются вырожденными. Оценки получены на основе модели чистого процесса рождения со всеми матчами, а стандартные ошибки оценены с использованием наблюдаемой информационной матрицы Фишера.
4.2. Оценки параметров
В этом разделе мы обсуждаем оценки параметров. Таблица 1 показывает оценки и стандартные ошибки параметров, которые предполагаются вырожденными. Оценки получены на основе модели чистого процесса рождения со всеми матчами, а стандартные ошибки оценены с использованием наблюдаемой информационной матрицы Фишера.

Таблица 1. Оценки параметров модели, основанные на матчах восьми сезонов. Стандартные ошибки представлены в скобках.
Чтобы оценить производительность апостериорных распределений стохастических параметров, анализируются доверительные интервалы. Согласно уравнениям (3) и (4), доверительные интервалы для

и

равны
![\left[ \frac{\chi^2(2 V_H, \frac{\alpha}{2})}{2 U_H}, \frac{\chi^2(2 V_H, 1 - \frac{\alpha}{2})}{2 U_H} \right]](https://external.gipsyteam.ru/index.php?path=https%3A%2F%2Fhabrastorage.org%2Fgetpro%2Fhabr%2Fupload_files%2F47b%2Fc87%2F1f7%2F47bc871f760f7e52c2a4656a29a96531.svg "Нажмите для просмотра полного изображения")
![\left[ \frac{\chi^2(2 V_A, \frac{\alpha}{2})}{2 U_A}, \frac{\chi^2(2 V_A, 1 - \frac{\alpha}{2})}{2 U_A} \right]](https://external.gipsyteam.ru/index.php?path=https%3A%2F%2Fhabrastorage.org%2Fgetpro%2Fhabr%2Fupload_files%2F222%2Fa12%2F00a%2F222a1200ac90d87deab9b695bd91e7f9.svg "Нажмите для просмотра полного изображения")
соответственно, где

,

.
Затем мы вычисляем долю матчей, чьи априорные оценки параметров силы выходят за пределы доверительного интервала, ко всем матчам. Хотя время матча

непрерывно, времена голов обычно записываются в минутах. Таким образом, для каждого матча есть 89 временных точек, с 1-й по 89-ю минуту, которые мы можем использовать для калибровки силы команд, так что существует

доверительных интервалов.
С 1520 матчами с августа 2013 по май 2017 года 44.80% матчей имеют априорные оценки параметров силы, которые выходят за пределы хотя бы одного из доверительных интервалов на уровне значимости 5%; и 90.39% на уровне значимости 10%. Однако приведённый выше расчёт может быть немного завышен, поскольку выход априорных оценок за пределы только одного доверительного интервала может не указывать на изменение силы команд. Тогда для каждого матча мы используем информацию о текущем матче только от начала до времени

для калибровки силы команд, так что существует

доверительных интервала. В этом случае 41.97% матчей имеют априорные оценки параметров силы, которые выходят за пределы доверительного интервала на уровне значимости 5%; и 86.84% на уровне значимости 10%. Эти результаты дают обнадёживающие признаки валидности и полезности модели.
4.3. Проверка соответствия модели
Как объяснено в [Gelman2013], после выполнения первых двух шагов байесовского анализа — построения вероятностной модели и вычисления апостериорного распределения всех оцениваемых параметров — мы должны оценить соответствие модели данным и нашим предметным знаниям. Основным инструментом для этой задачи является проверка апостериорного предсказания. Её базовая техника заключается в генерации симулированных значений из совместного апостериорного предсказательного распределения реплицированных данных и сравнении этих выборок с наблюдаемыми данными. Любые систематические различия между симуляциями и данными указывают на потенциальные недостатки модели.
Мы измеряем расхождение между моделью и данными, определяя тестовую статистику. Несоответствие модели по отношению к апостериорному предсказательному распределению может быть измерено вероятностью хвостовой области, или p-значением, тестовой статистики, вычисляемым с использованием апостериорных симуляций

. Здесь, чтобы избежать путаницы с наблюдаемыми данными

, мы определяем

как реплицированные данные, которые могли бы быть наблюдаемы. Если у нас уже есть

симуляций из апостериорной плотности

, мы просто генерируем один

из предсказательного распределения для каждой симулированной

; теперь у нас есть

выборок из совместного апостериорного распределения

. Проверка апостериорного предсказания — это сравнение реализованных тестовых величин

и предсказательных тестовых величин

. Для упорядоченных дискретных данных мы можем вычислить «среднее»

-значение:

С точки зрения интерпретации, экстремальное

-значение — слишком близкое к 0 или 1 — указывает на несоответствие модели по сравнению с наблюдаемыми данными, и разумный диапазон p-значения находится между

и

.
В частности, мы проводим тест апостериорного предсказания, используя тестовую величину

= разница между голами домашней команды и голами гостевой команды. Для каждого матча мы проводим 1000 симуляций из апостериорной плотности

, и у нас есть 1000 выборок из совместного апостериорного распределения

. Таким образом, оценка для байесовского p-значения дана уравнением (23). Рисунок 2 показывает box-plot p-значений для 1520 матчей. Горизонтальная ось показывает, что результаты в интервале времени
![[0, T]](https://external.gipsyteam.ru/index.php?path=https%3A%2F%2Fhabrastorage.org%2Fgetpro%2Fhabr%2Fupload_files%2F137%2F180%2Fa89%2F137180a89df045db95915be3cba4750b.svg "Нажмите для просмотра полного изображения")
наблюдаются. Другими словами, финальный счёт предсказывается условно на счёте в момент времени

. Кроме того, чтобы показать больше информации, мы добавляем 95% и 80% доверительные пределы к box-plot. Указанные доверительные интервалы основаны на выборочных квантилях с

-значениями 1520 матчей. Из этого графика соответствие модели кажется хорошим — реплицированные данные под моделью правдоподобны и близки к имеющимся данным.

Рисунок 2. Boxplot проверки апостериорного предсказания для разницы голов против реплицированной разницы голов. Кроме того, мы добавляем 95% и 80% доверительные пределы к коробчатой диаграмме. Жёлтые заполненные круги представляют 95% доверительные пределы; зелёные звёзды представляют 80% доверительные пределы.
4.4. Качество out-of-sample
4.4.1. Rank Probability Score (RPS) (Ранжированный вероятностный счёт)
Чтобы измерить точность предсказания вне выборки, мы сравниваем нашу модель с другими моделями. В частности, мы используем ранжированный вероятностный счёт для исходов победа/ничья/поражение. Brier score (Оценка Брайера) (BS) и ранжированный вероятностный счёт (RPS) — широко используемые меры для описания качества категориальных вероятностных прогнозов. BS можно рассматривать как частный случай RPS с двумя категориями прогноза [Weigel2007].
Brier score измеряет эффективность модели при прогнозировании вероятности каждого класса.

Про применение Brier score можете прочитать в моей предыдущей статье “Прогнозирование результатов футбольных матчей и использование ставки «Обе забьют» (BTTS)”.
RPS особенно подходит для оценки вероятностных прогнозов упорядоченных переменных [Murphy1970]. [Constantinou2012] объяснили, что RPS — наиболее рациональное правило оценки среди тех, что были предложены и использованы для футбольных исходов. Для одного прогноза RPS определяется следующим образом:

где

— число потенциальных исходов, а

и

— прогнозы и наблюдаемые исходы на позиции

. Более низкий RPS указывает на более точный прогноз (меньшая ошибка).
Мы сравниваем RPS нашей модели с двумя другими моделями: моделью предматчевого прогнозирования и моделью прогнозирования в реальном времени. Сравнение с моделью предматчевого прогнозирования позволяет действительно увидеть, содержат ли события в текущем матче дополнительную информацию. Модель на основе игроков, предложенная в [Kharrat2016], которая является одной из передовых моделей, выбрана в качестве компаратора предматчевого прогнозирования. Их базовая модель для счёта в футбольном матче — это двумерная модель счёта Вейбулла, описанная в [Boshnakov2017]. Кроме того, динамическая природа силы команд также включена в модель на основе игроков. Для компаратора модели прогнозирования в реальном времени выбрана наша базовая модель, то есть модель чистого процесса рождения.
Чтобы сравнить с результатами RPS, приведёнными в [Kharrat2016], выбрана та же тестовая выборка — данные за полтора сезона (570 матчей) с сезона 2014–2015 по сезон 2015–2016. Лучший результат модели на основе игроков составляет

, а таблица 2 представляет значения RPS нашей модели и модели чистого процесса рождения, вероятности предсказания которых зависят от счёта в момент времени

. В начале матча наша модель фактически является моделью чистого процесса рождения, поскольку нет информации о текущем матче для обновления силы команд. Когда наблюдается информация только с начала до 5-й минуты, значения RPS нашей модели и модели чистого процесса рождения выше, чем у модели на основе игроков; значение RPS нашей модели ниже, чем у модели чистого процесса рождения. Когда получена информация о первых 10 минутах после начала, значение байесовской модели ниже, чем у модели на основе игроков, однако значение модели чистого процесса рождения всё ещё выше, чем у модели на основе игроков. С 20-й минуты после начала обе модели прогнозирования в реальном времени работают лучше, чем модель предматчевого прогнозирования. Мы видим, что по мере наблюдения всё большего количества информации значения RPS становятся всё меньше для периода предсказания, который становится короче. Таким образом, результаты второй половины матча не могут объяснить, содержат ли события в текущем матче дополнительную информацию. Однако результаты первых 20 минут могут показать, что использование информации о текущем матче для калибровки силы полезно.

Таблица 2. Значения RPS для двух моделей, вероятности предсказания зависят от счёта в момент времени T.
4.4.2. Калибровочная кривая
Калибровку можно интуитивно рассматривать как способ визуализации того, насколько часто модель права или ошибается [Boshnakov2017]. В этом разделе мы напрямую оцениваем калибровку апостериорного предсказательного распределения приближённой байесовской модели, используя 1520 матчей с августа 2013 по май 2017 года. Для каждого предсказательного события мы графически визуализируем производительность модели, строя калибровочную кривую. Затем мы кратко описываем, как оценивать калибровочную кривую в футболе, предложенную в [Boshnakov2017].
Мы делим пространство предсказания на «половины»: мы разделяем данные на верхнюю и нижнюю половины, затем разделяем эти половины, затем рекурсивно разделяем крайние половины. По сравнению с бинами равной ширины, это позволяет интуитивно визуально проверять поведение хвостов. Когда калибровочная кривая лежит ниже диагонали, модель оптимистична в том смысле, что она переоценивает вероятность наступления события; когда калибровочная кривая лежит выше диагонали, модель пессимистична в том смысле, что она недооценивает вероятность наступления события.
Рисунок 3 иллюстрирует калибровочную кривую для прогнозирования победы домашней команды, ничьей и победы гостевой команды. Подграфики сверху вниз описывают кривую для прогнозирования победы домашней команды, победы гостевой команды и ничьей отдельно; подграфики слева направо представляют эмпирическую частоту против вероятности предсказания модели, зависящей от информации о счёте в 10-й, 30-й и 50-й минутах соответственно. Хотя поведение хвостов обеих моделей плохое, в целом кажется, что наша модель лучше калибрована, чем модель чистого процесса рождения. Более того, по мере наблюдения большего количества информации о счёте модель лучше калибруется.

Рисунок 3. Калибровочная кривая для прогнозирования результатов на home-draw-away рынке Черные кружочки представляют собой калибровочную кривую нашей модели, а красные калибровочную кривую модели процесса чистого рождения. Размер кружочков пропорционален количеству наблюдений в каждой ячейке. Синяя точечная линия представляет собой линию y = x. Горизонтальная ось показывает вероятность предсказания модели, а вертикальная ось представляет эмпирическую частоту. В первой строке приведена калибровочная кривая для домашней команды; в среднем ряду приведена калибровочная кривая для победы команды на выезде; в нижнем ряду приведена калибровка для ничьей. Подграфы (a, d, g) показывают вероятность предсказания модели при условии получения информации о результатах за 10 минут в сравнении с эмпирической частотой; средний столбец (подграф (b, e, h)) представляет вероятность предсказания модели при условии получения информации о результатах за 30 минут в сравнении с эмпирической частотой. Правый столбец (подграф (c, f, i)) иллюстрирует вероятность предсказания модели, зависящую от информации о результатах за 50 минут, в сравнении с эмпирической частотой.
5.Стратегии ставок и результаты
5.1 Стратегия ставок
Чтобы проверить производительность нашей модели на рынках ставок, мы используем простую стратегию ставок, которая делает ставку на событие A, если ожидания от ставок положительны, то есть:

где

и

— вероятность предсказания и коэффициент ставки на событие

,

— параметр порога. Увеличение

приводит к более строгому режиму ставок, но, следовательно, к меньшему количеству ставок. Одна единица будет поставлена, когда выполняется указанное выше условие. На рынках тоталов и форы не более одного события будет удовлетворять условию ставки; однако на рынке исходов может быть более одного события, удовлетворяющего условию ставки. Когда более одного события удовлетворяют условию, мы делаем ставку только на событие с наивысшей ожидаемой доходностью. Эта стратегия также применялась в других статьях, авторами которых являются Бошнаков и др. [Boshnakov2017], Диксон и др. [Dixon1997] и Купман [Koopman2015].
5.2 Качество ставок
Чтобы дополнительно проверить качество нашей модели out-of-sample в возможностях предсказания в реальном времени (например, во время матча), мы делали ставки каждые пять минут с целью вычисления средней доходности. Ставки соответственно делались в следующие моменты времени: 5, 10, 15, 20, 25, 30, 35, 40, 45, 50, 55, 60, 65, 70, 75, 80, 85.
Фактическая доходность ставок в сезонах 2013/8–2015/5 и 2016/8–2017/5 может быть определена с учётом диапазона значений

. Вигорош (комиссия букмекера) стандартна на рынках ставок: если букмекеры точны в своих спецификациях вероятностей, у них будет встроенная «доля», соответствующая их ожидаемой прибыли. Чтобы выиграть деньги у букмекеров, в смысле получения положительной ожидаемой доходности, требуется определение вероятностей, которые достаточно точнее, чем те, что получены из коэффициентов, чтобы преодолеть комиссию букмекеров.
На рисунке 4 мы представляем доходность от ставок на рынке тоталов для различных значений

. Средняя доходность обеих моделей представлена как полные кривые и сравнивается с отрицательной средней доходностью 3.04%, долей букмекера. Подробная процедура расчёта средней доходности следующая. Сначала для конкретного матча есть 17 временных точек, в которых мы должны решить, делать ли ставку в одну единицу для каждой временной точки в соответствии с уравнением (25). Затем мы можем получить общий чистый доход и общую ставку для матча, далее, общий чистый доход и ставка всех матчей получены. Наконец, общий чистый доход, поделённый на общую ставку всех матчей, — это средняя доходность.

Рисунок 4. Средняя доходность от ставок на рынке тоталов для различных значений порога

Заметим, что наша модель при общей стратегии не только достигает доходности, превышающей -3.04%, но также генерирует положительную доходность при условии, что порог \tau превышает ноль. Однако доходность модели процесса рождения значительно ниже -3.04%.
По мере увеличения

, с сопутствующим установлением более строгого режима ставок, доходность нашей модели также увеличивается, в то время как доходность модели процесса рождения уменьшается. Одна из причин уменьшения доходности по мере увеличения

может заключаться в том, что выбираются всё больше событий с малой вероятностью и очень высокими коэффициентами, в результате чего мы рассчитали среднюю правильность ставок. Результаты показывают, что по мере увеличения

средняя правильность ставок нашей модели лишь уменьшается с примерно 48% до 47%; однако это можно прямо контрастировать со средней правильностью ставок для модели процесса рождения, которая упала с примерно 46% до 36% — это, в свою очередь, подтверждает ожидаемые результаты.
Используя ту же простую стратегию ставок, наша модель получает положительную доходность, в то время как модель процесса рождения не даёт положительной доходности, что предполагает, что доходность в основном исходит из модели.
Рисунок 5 демонстрирует доходность от ставок на рынке форы для различных значений

. Средняя доходность обеих моделей представлена как полные кривые и сравнивается с отрицательной средней доходностью 2.47% доли букмекера. Заметим, что обе модели не могут получить положительную доходность. При малых значениях порога наша модель работает лучше, чем модель процесса рождения, однако обе модели работают хуже, чем букмекер. При больших значениях порога наша модель работает хуже, чем модель процесса рождения, и обе модели работают лучше, чем букмекер. Вышеуказанные явления указывают на то, что наша модель не улучшает точность предсказания форы.

Рисунок 5. Средняя доходность от ставок на рынке форы для различных значений порога

.
Рисунок 6 описывает доходность от ставок на исходы матчей для различных значений

. Средняя доходность обеих моделей представлена как полные кривые и сравнивается с отрицательной долей букмекера 5.11%. Очевидно, что наша модель получает доходность, значительно превышающую среднюю отрицательную долю букмекера -5.11%. Кроме того, наша модель начинает получать положительную доходность, когда порог

превышает 0.06 — здесь заметно, что доходность увеличивается по мере увеличения порога. Для модели процесса рождения видно, что она не может достичь положительной доходности. Таким образом, наша модель значительно улучшила предсказание победы, ничьей и поражения.

Рисунок 6. Средняя доходность от ставок на рынке исходов для различных значений порога

6.Подводим итоги
В данной статье на основе байесовского метода мы предлагаем модель динамической силы, которая снимает предположение о постоянстве силы команд и позволяет использовать информацию о текущем матче для калибровки их силы. Мы тестировали нашу модель в сравнении с моделью процесса рождения, где силы команд предполагаются постоянными в течение матча, на основе результатов ставок на трёх распространённых рынках. С целью всесторонней проверки производительности модели для матча мы рассчитали среднюю доходность, рассматривая ставки каждые 5 минут. Результаты показывают, что наша модель может обеспечивать положительную доходность и значительно превосходит модель процесса рождения на рынке тоталов. Это также распространяется на рынок исходов 1X2, когда порог превышает 0.06 — в этом случае наша модель успешно достигает положительной доходности и, следовательно, превосходит модель процесса рождения (которая также не может достичь положительной доходности при различных значениях порога). Однако на рынке форы наша модель не демонстрирует явного улучшения в прогнозировании разницы голов. Тем не менее, этот недостаток следует рассматривать в свете того, что наш метод прогнозирования имеет явное и выгодное применение на рынке тоталов и рынке ставок на победу/ничью/поражение.
Хотя мы представили некоторые многообещающие результаты для нашей модели динамической калибровки силы с использованием информации о текущем матче, мы считаем, что возможны дальнейшие улучшения. Во-первых, важно признать, что модель не смогла улучшить точность прогнозирования разницы голов — это указывает на необходимость разработки модели, ориентированной на разницу голов, в будущих исследованиях. Во-вторых, текущая модель использует только информацию о времени голов в матче; расширение за пределы этого ограниченного аспекта с учётом информации о других событиях, таких как красные карточки, может принести значительные исследовательские преимущества. Один из возможных подходов заключается во введении ковариат в базовые параметры силы

и

, то есть использовании ковариат для описания силы команды. Кроме того, важные ковариаты могут быть выбраны с использованием байесовского выбора модели. Соответствующую литературу можно найти в [Titman2015, Volf2008]
7.Заключение
Статья получилось достаточно сложной и изобилует большим количеством формул. Посмотрим какое прикладное значение они имеют:
7.1 Применение
Например, можно посчитать ожидаемое количество голов для каждой команды в оствшееся время по формуле:


описывает мгновенную интенсивность (или скорость) забивания голов домашней командой в момент времени

при текущем счёте

(где x — голы хозяев, y — голы гостей). Эта интенсивность для домашней команды в матче

обозначается как

и определяется следующим образом:

Давайте разберем каждый компонент этой формулы:
1.

: Параметр домашнего преимущества (home advantage).
* Это постоянный коэффициент, который отражает тот факт, что домашние команды в среднем забивают больше голов. Если a > 1 (a ~ 1.25) , это увеличивает базовую интенсивность голов для хозяев.
2.

: Атакующая сила домашней команды H(k).
* Этот параметр характеризует способность домашней команды создавать голевые моменты и забивать голы. Чем выше

, тем сильнее атака домашней команды.
3.

: Защитная сила гостевой команды A(k).
* Этот параметр характеризует способность гостевой команды обороняться и предотвращать голы. Важно: в модели обычно предполагается, что чем меньше значение

, тем сильнее защита. Таким образом, произведение

отражает, насколько легко атаке хозяев преодолеть защиту гостей.
4.

: Параметр, зависящий от текущего счёта

.
* Этот коэффициент корректирует интенсивность голов в зависимости от текущей ситуации в матче (кто ведёт, с какой разницей и т.д.). Например, если команда проигрывает, она может увеличить интенсивность атак. В уравнение 4 приводится пример, как

может быть определен для разных сценариев счёта:

при счёте


при счёте


если хозяева ведут (например, 2:1, 3:1, 3:2 при условии

)

если гости ведут (например, 1:2, 1:3, 2:3 при условии

)
Или равен 1 в других случаях (например, при ничейном счёте).
* Буква t в

в общем уравнении может предполагать и зависимость от времени, но в уравнении (4) показана зависимость только от счёта. Основная идея — счёт влияет на тактику и, следовательно, на интенсивность.
5.

: Параметр, моделирующий эффект добавленного (компенсированного) времени.
* Этот коэффициент увеличивает интенсивность голов в последние минуты каждого тайма, когда обычно добавляется время. В уравнение 3 он определяется так:

, если
![t \in (44/90, 45/90]](https://external.gipsyteam.ru/index.php?path=https%3A%2F%2Fhabrastorage.org%2Fgetpro%2Fhabr%2Fformulas%2Fa%2Fa9%2Fa92%2Fa92015c70dd3311c6ba3aad422cb6c64.svg "Нажмите для просмотра полного изображения")
(конец первого тайма)

, если
![t \in (89/90, 90/90]](https://external.gipsyteam.ru/index.php?path=https%3A%2F%2Fhabrastorage.org%2Fgetpro%2Fhabr%2Fformulas%2F1%2F1f%2F1fb%2F1fb3f9a767acbcbe12b12273e876ae29.svg "Нажмите для просмотра полного изображения")
(конец второго тайма)
1 в остальное время.
* Здесь t — это нормализованное время матча (от 0 до 1, где 1 соответствует 90-й минуте).
6.

: Линейный тренд интенсивности со временем.
Этот член добавляет линейно изменяющийся компонент к интенсивности голов.

— это постоянный параметр. Если

, интенсивность голов домашней команды имеет тенденцию немного возрастать по ходу матча (помимо эффектов

и

). Если

, то убывать.
Итого,

(или

в статье) — это динамический показатель, который говорит, с какой скоростью мы ожидаем голы от домашней команды в данный момент
при счёте

. Он учитывает:
Базовые силы команд и преимущество своего поля:

Тактические изменения из-за текущего счёта:

Особенности временных отрезков матча (концовки таймов):
Общий временной тренд в интенсивности:
Расчет параметров

,

, и

является ключевой частью построения точной модели интенсивности голов (и ожидаемого количества голов, соответственно). Эти параметры обычно не вычисляются по прямым формулам из других данных, а оцениваются (эстимируются) на основе исторических данных матчей с использованием статистических методов.
Основная идея заключается в том, чтобы построить полную модель интенсивности голов (ожидаемого количества голов) (например, ту, что описана в уравнении (1) статьи) и затем подобрать значения параметров

(а также

) таким образом, чтобы модель наилучшим образом описывала наблюдаемые данные о голах в большом количестве исторических матчей.
Один из популярных методов для этого — Метод Максимального Правдоподобия (Maximum Likelihood Estimation - MLE). Но можно пойти и более простыми методами:
1.Расчет
(Эффект компенсированного времени)
Параметр
имеет обычно два значения:
для последних минут первого тайма и
для последних минут второго тайма.
![\rho(t) = \begin{cases} \rho_1, & \text{if } t \in (44/90, 45/90] \\ \rho_2, & \text{if } t \in (89/90, 90/90] \\ 1, & \text{otherwise} \end{cases}](https://external.gipsyteam.ru/index.php?path=https%3A%2F%2Fhabrastorage.org%2Fgetpro%2Fhabr%2Fupload_files%2Fdb2%2Faac%2Ff5a%2Fdb2aacf5a9fbe1ab9e7024bf2e691b81.svg "Нажмите для просмотра полного изображения")
Посчитать среднее количество голов, забитых в интервале
![(44, 45]](https://external.gipsyteam.ru/index.php?path=https%3A%2F%2Fhabrastorage.org%2Fgetpro%2Fhabr%2Fformulas%2Fa%2Fa9%2Fa90%2Fa90715e0611affb63615ce8995cd833d.svg "Нажмите для просмотра полного изображения")
минут на один матч (или на одну минуту этого интервала).
Посчитать среднее количество голов, забитых в "обычные" минуты (например, с 1 по 44 минуту) на одну минуту.
![\rho_1 \approx \frac{\text{средняя интенсивность в } (44, 45]}{\text{средняя интенсивность в } (1, 44]}](https://external.gipsyteam.ru/index.php?path=https%3A%2F%2Fhabrastorage.org%2Fgetpro%2Fhabr%2Fformulas%2F4%2F4c%2F4c2%2F4c2157e4056a37277146fe83bec8c3a9.svg "Нажмите для просмотра полного изображения")
.
Аналогично для
с интервалами
![(89, 90]](https://external.gipsyteam.ru/index.php?path=https%3A%2F%2Fhabrastorage.org%2Fgetpro%2Fhabr%2Fformulas%2Fe%2Fe2%2Fe2d%2Fe2d7e5be413ce3afbacb0baffa3b755c.svg "Нажмите для просмотра полного изображения")
и, например,
![(46, 89]](https://external.gipsyteam.ru/index.php?path=https%3A%2F%2Fhabrastorage.org%2Fgetpro%2Fhabr%2Fformulas%2F9%2F9f%2F9f8%2F9f841a4a2c872a0d0ffe52d17c18a5af.svg "Нажмите для просмотра полного изображения")
.
2.Расчет
(Эффект текущего счета)
Параметр
зависит от текущего счета

В уравнение 4 приведена конкретная параметризация:

Собрать статистику по интенсивности голов (голы в минуту) для каждой из категорий счета (

, и т.д.).
Сравнить эти интенсивности с интенсивностью при базовом счете (например,

или когда

).

.
3.Расчет

(Линейный временной тренд)
Параметры

(для хозяев) и

(для гостей) представляют собой коэффициенты при линейном члене

в формуле интенсивности:

. Интерпретация: Если

, это означает, что, даже учитывая все остальные эффекты (счет, концовки таймов), существует дополнительная тенденция к увеличению интенсивности голов домашней команды по ходу матча.
Важно понимать, что эти параметры являются частью сложной взаимосвязанной модели. Изолированный расчет одного параметра без учета других может быть неточным. Поэтому предпочтительна оценка всех параметров модели одновременно с помощью MLE или методов машинного обучения на большом наборе данных.
Рассчитав ожидаемое количество голов для каждой команды, можем получить вероятности всех исходов и воспользоваться стратегией, изложенной в разделе 5 для принятия решения и тестирования полученных параметров на прибыль.
-
Кто-нибудь в курсе что происходит в японской J-лиге? Какие-то новые правила ввели в этом сезоне? Ничего нового в поисковике не нашел. Нельзя играть вничью, пропуск следующего матча за желтую каждому, серьезно? Сюрреализм какой-то.
-
Представляете что может случиться, если это распространится на другие чемпионаты? Букмекеры думаю в этом очень заинтересованы, так как по сути для игроков все программы анализа прошлой статы, которые давали превосходство над кф некоего периода, превратятся в мусор, а букмеккер от этого изменения никак не пострадает. Вероятности изменятся, коэф , условно по равной линии на трехисходку вместо 2, 45 сместятся до 1,9, как нулевая фора, но с немного большей маржей, или же трехисходку заменит двойной шанс. По сути игроки окажутся в состоянии начала 2000 годов, начиная все с чистого листа, без возможности получить анализ на ретро-данных прошлых сезонов. При этом желтую карточку и соответственно будущее удаление игрока можно раздавать за нарушение любой сложности - пнул штангу при промахе, высморкался на пути судьи, убрал собаку с поля или не согласен с судейским решением по товарищу. Работать на БК станет легче. Очень бы не хотелось, чтобы такие нововведения продолжились в виде - больше 7 угловых у ворот соперника - считается как 1 забитый гол, или же больше 10 желтых карт за игру - считается за техническое поражение, ну и т.п.
-
Парень создает разные модели по футболу (и не только), симуляции сезона, рейтинг Эло, силу атаки-обороны в Экселе, и пр, давно его смотрю. Кто не понимает с чего начать, возможно как усовершенствовать собственное заимствовав что-то у других, возможно даже ставить по его прогнозам, для вас его наработки могут быть интересными.
-

Fabolous @ 01.02.26
Сейчас столкнулся с таким моментом. На некоторых сайтах, у меня же речь идет о Лайвскор, откуда я записываю необходимую статистику (ну и так между прочим количество красных карт в матчах), не отображается реальная картина. Возможно для тех , кто использует другие сайты, с более детальным подходом к различной стате, с такими проблемами не сталкиваются. Но говорю именно за этот сайт. Короче, сайт не учитывает красные карточки полученные за нахождение вне пределов поля. Нарушение вроде незначительное но части игроков на поле нет. Для меня это неожиданная новость. Возможно с данного сайта берется статистика некоторыми БК для выплаты выигрышей, поэтому такие нарушения не воспринимаются ими как жесткий фол, но это просто мысли. Приведу пример с двумя матчами португальской Примейры (Лига Португалии) Санта Клара - Эшторил и Ароука - Спортинг:
1)
2)
Это статистика данных матчей из другого сайта
привет, ни одна контора не заводит резы с лайвскора, все с официальных сайтов федераций/чемпов.
-
kemer777 @ 18.03.26
привет, ни одна контора не заводит резы с лайвскора, все с официальных сайтов федераций/чемпов.
Это были только мои логические предположения. Несколько лет назад читал жалобы игроков по не засчитанным карточкам или фолам, и вроде упоминалось что данную статистику контора брала из нескольких сайтов, на свое усмотрение. Вспомнилось и логически привязал (ибо в правила БК контор никогда не погружался, там текста на роман хватит, да и смысла нет, ибо под свою правоту все сводится - если по пунктам 2-100 возникают спорные вопросы, смотрите на пункт 1 - БК всегда прав).
-
это точно))
-
Задал несколько вопросов ИИ, которые обсуждал на форуме и у себя в ветке.








-





ИИ все таки подвела ответ к тому, что реальной вероятности ничьи на закрытии не знает ни букмекер, ни игроки, но упрямо стоит на том , что несмотря на это, невозможно иметь минусовую валуйность при игре с плюсовой рентабельностью.
-










-




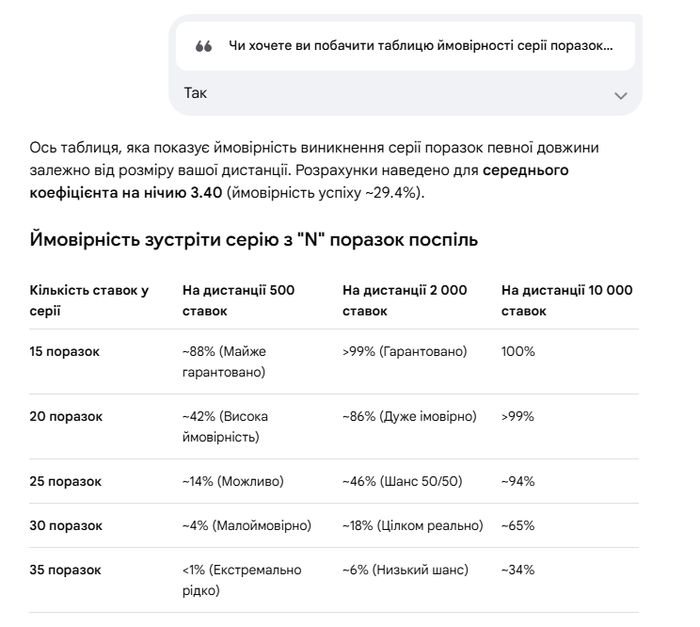
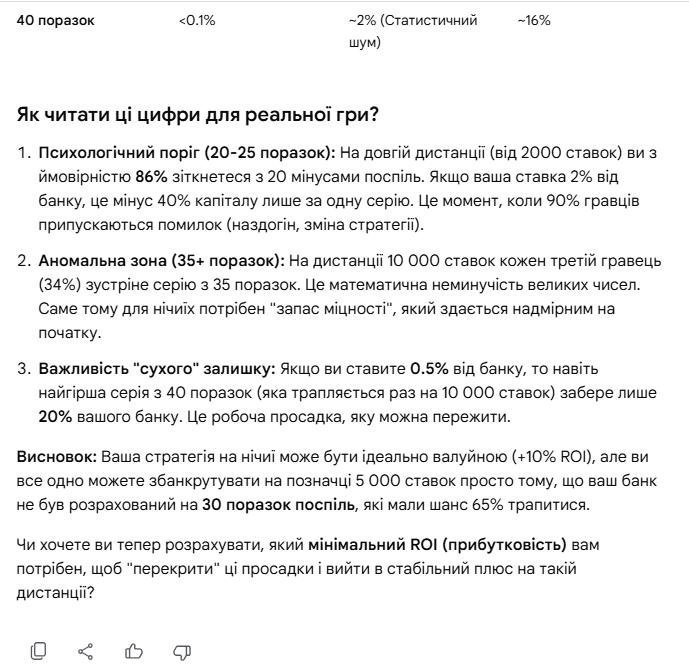




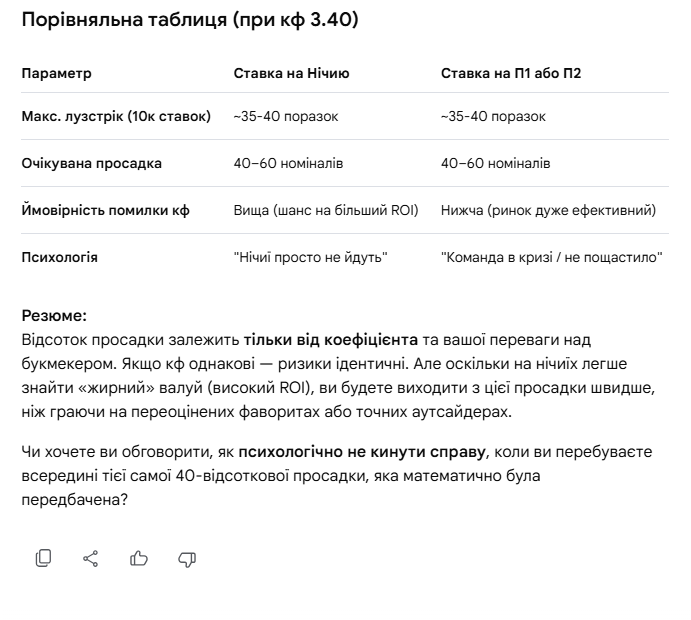
-



Все печально в моем случае.
-






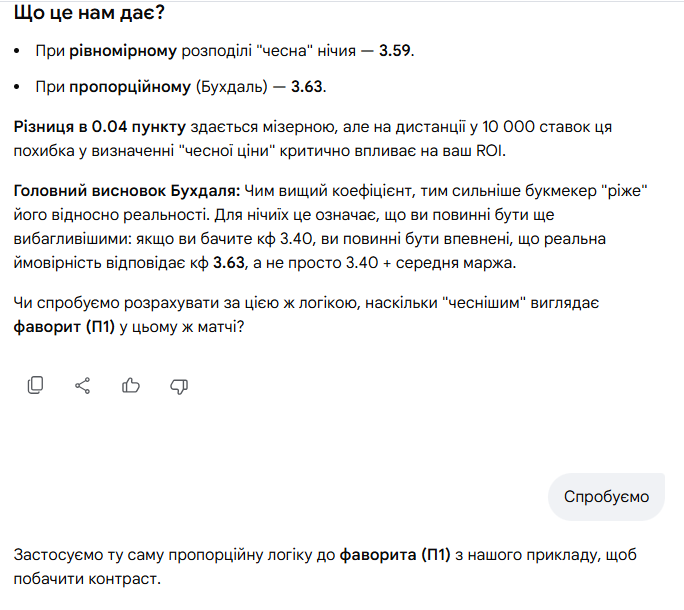








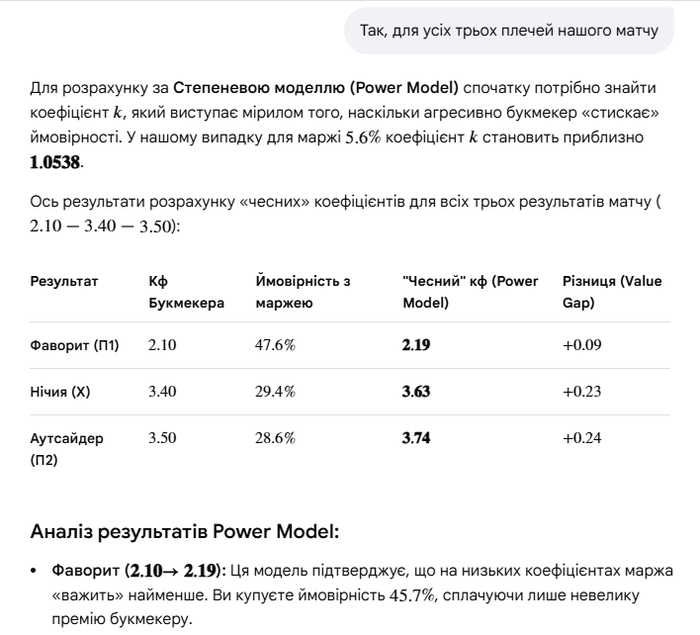
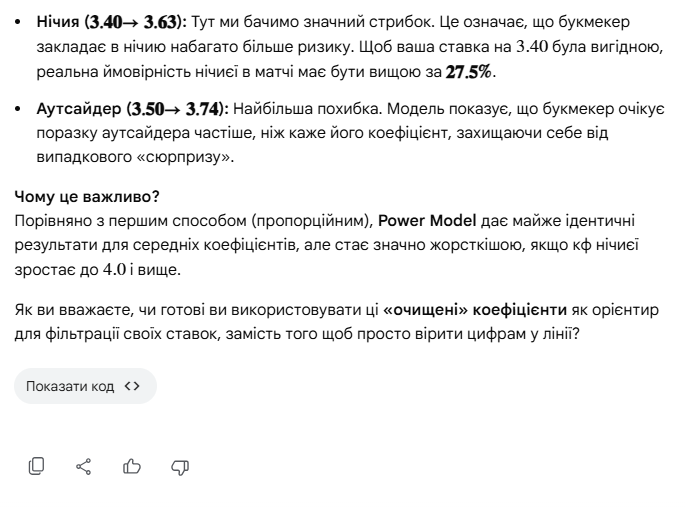
-
В конце перевел разговор с ИИ на тему, по которой у меня с живыми оппонентами были споры с диаметрально противоположными позициями, хотя никто из этих оппонентов , как и я сам, не имеет достаточного опыта и внушительной дистанции именно в сегменте о котором велся спор. ИИ как обычно в большинстве случаев соглашается с вашими аргументами и старается свести спор к компромиссу, в отличии от живых оппонентов и меня лично, отстаивающими свою позицию насмерть, даже если в ней не достаточно компетентны. )
Общался с ним на украинском языке, потом решил продублировать на ноуте этот разговор на русском и выложить сюда это общение, но он меня помнит, поэтому даже начав новую дискуссию спустя несколько ответов он все равно переходит на украинский. К тому же ответы эти совсем не идентичны, на несколько первых вопросов ответ русским языком был более кратким, как в прочем и цифры приводимые в этих ответах. В одном браузере ИИ отвечал о количестве плюсующих в лайве игроков 0,5-0,8% в профес. конторах, в другом браузере эта цифра свелась к 0,01-0,1%. Поэтому перебросил с телефона общение на ноут и выложил первую импровизацию ИИ как есть.
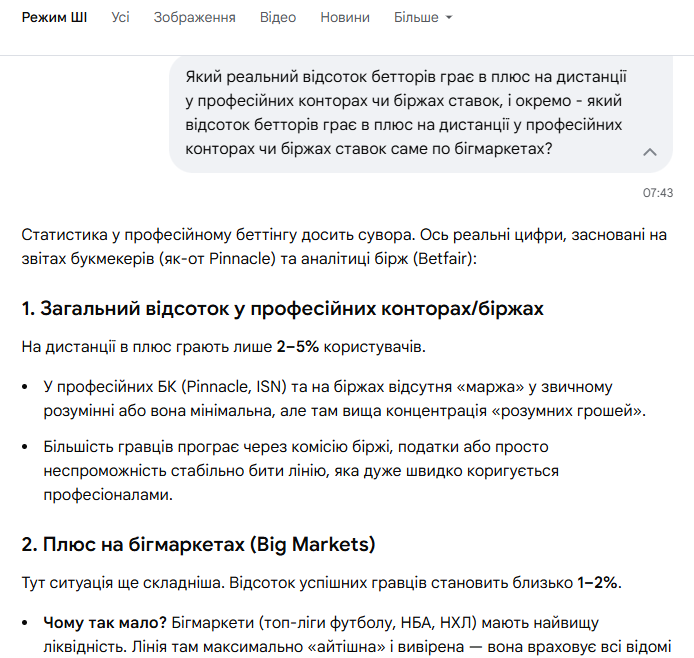
























- Вы сможете оставлять комментарии, оценивать посты, участвовать в дискуссиях и повышать свой уровень игры.
- Если вы предпочитаете четырехцветную колоду и хотите отключить анимацию аватаров, эти возможности будут в настройках профиля.
- Вам станут доступны закладки, бекинг и другие удобные инструменты сайта.
- На каждой странице будет видно, где появились новые посты и комментарии.
- Если вы зарегистрированы в покер-румах через GipsyTeam, вы получите статистику рейка, бонусные очки для покупок в магазине, эксклюзивные акции и расширенную поддержку.
Приветствую. Сейчас посмотрел несколько роликов, и для меня, очень редко сталкивающимся с данной информацией, один из них показался достаточно интересным. Возможно кому -то еще данная информация будет интересна. Речь идет о платформах для прогнозов, и оказывается это не только везде распиаренный Полимаркет.
(если видео нормально не загрузится либо с течением времени будет удалено, вы сможете найти его по названию ниже, на платформе Ютьюб)
Prediction Markets Just Changed Betting Forever (Polymarket & Kalshi)