Data Adventures
-
ПопулярностьТоп-3591
-
Постов906
-
Просмотров175,402
-
Подписок324
-
Карма автора+11,602
-
В модели дается прогноз не только дисперсии, но и матожиданию курса биткоина. Если перемножить все 5
+15
-
давай рейтинг топ токсиков теперь )))) Бачинский кстати активно лепил всем минуса в репу,
+13
-
Имея <> 23 года опыта в айти и <> 20 лет в покере, могу сказать что в покере сейчас день
+13
-
SnowBeaver, как будто x3 всё же завышено. Вообще в целом тренд такой, что много деняк дают тол
+11
-
Исследование прикольные, но выводы странные. Очень часто в коммьюнити минусют скамеров/арбитражников
+11
-
-

SnowBeaver @ 31.05.25
"нужно учиться промт-инжинирингу чтобы получать более корректные ответы"
Не совсем об этом был мой пост, главный посыл был про реформатирование задач. В любом случае это просто инфа для размышления + практический опыт использования, пригодность для ваших задач сами определите.
Правда зачем мне было писать, если через пару дней выкладывают paper про это?
1) Для простых задач, обычные модели лучше (зарождение overthinking парадокса)
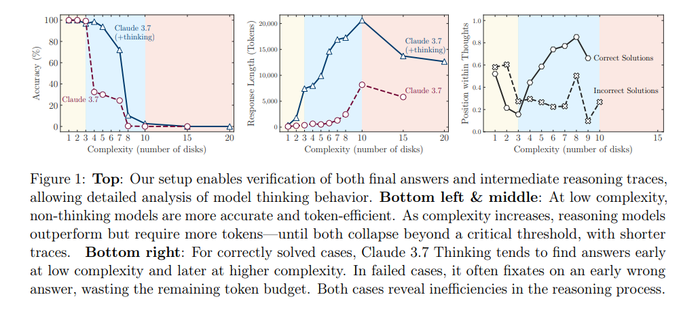
2) На достаточной глубине сложности задачи, все модели фэйлят

3) На средней сложности "reasoning/думающие" модели более затрато-эффективные
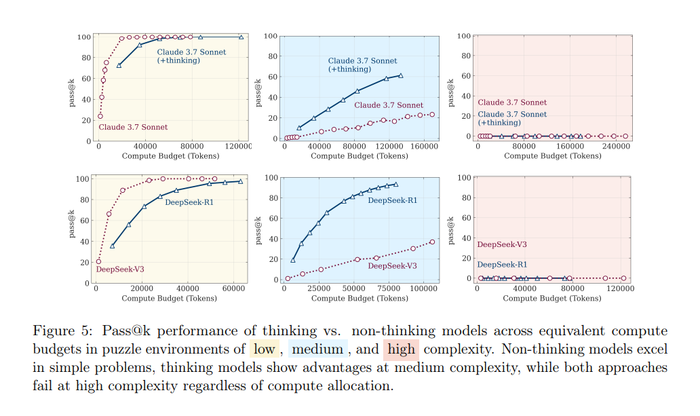
4) Эффективное увеличение токенов идёт только до определённой глубины, дальше происходит "ааа сложна"

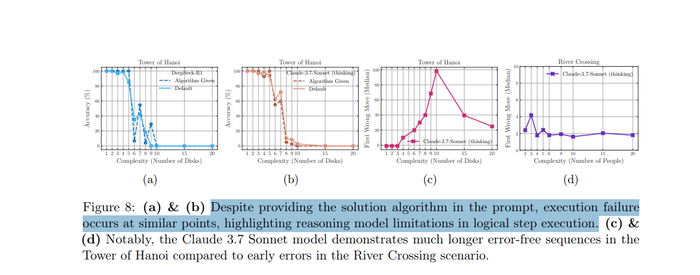
5) Даже с предоставленным в промпте алгоритмом решения, модели фейлят на примерно 10-ых шагах
Привет всем, кто хочет чтобы они играли в шахматы/покер. И всем, кто хочет не давать им вектор/оболочку "того что нужно".
А, вспомнил зачем... Чтобы вы насмехались надо мной, переводя мой текст на человеческий ИИ утилитой.
Мог бы я больше 10 вразумительных строк... писать.. я бы вам... такого... нагово...You are absolutely correct!
-

ExeRco @ 11.06.25
Чтобы вы насмехались надо мной, переводя мой текст на человеческий ИИ утилитой.
no no no
просто переводили нейронкой потому что "сложна" пишешь...
этот папер от эпла , которые до сих пор ни одной нейронки нормальной не сделали с их деньжищами...
это такой микро удар в спину индустрии,потому что сами отстали...
ExeRco @ 11.06.25
Привет всем, кто хочет чтобы они играли в шахматы/покер.
так уже давно сделали все это и они обыграли людей ...
alphaZero Pluribas
там o3-pro выпустили на волю
пробовал кто?
ну и на закуску анализ статьи от o3-pro :
ChatGPT
o3-pro

Кратко
Статья «The Illusion of Thinking…» (Apple AI, 2025) исследует, как современные «Large Reasoning Models» (LRM, версии Claude 3.7 Thinking, DeepSeek-R1, OpenAI o3-mini и др.) ведут себя при решении задач возрастающей сложности. Авторы создают четыре «контролируемых» головоломки – «Ханойские башни», «Переправа», «Прыгающие шашки» и «Мир кубиков» – где числом дисков/актеров/блоков можно плавно регулировать сложность и при этом однозначно проверять как финальный ответ, так и каждое промежуточное действие в Chain-of-Thought.
Главные выводы работы
Существует три режима сложности.
• низкая – обычные LLM без CoT часто точнее и экономичнее;
• средняя – LRM начинают выигрывать;
• высокая – у всех моделей точность обнуляется («collapse»).При приближении к «точке обрушения» модели вдруг сокращают объём «thinking-tokens», хотя лимит контекста далёк от исчерпания.
Правильное решение, если появляется, «съезжает» к более поздним шагам мысли; для простых задач наблюдается «over-thinking» (верный ответ найден рано, но затем затирается).
Даже если в подсказке дать идеальный алгоритм (пример – рекурсивное решение Ханоя), модели всё равно рано или поздно делают некорректный ход; значит, проблема не только в поиске, но и в исполнении логических инструкций.
Насколько работа актуальна?
Высокая. Тема «умеют ли LLM действительно «рассуждать»» – одна из центральных в 2024-2025 гг. Появились десятки работ: Toolformer, RCI, Step-Aware Verifier, VinePPO, Ballon et al., Yue et al. Статья Apple:
• расширяет дискуссию за счёт полностью «чистых» датасетов (нет утечек тренировочных примеров);
• показывает, что даже новейшие LRM (выходившие уже после o1, Claude 3.7 Thinking, Gemini Flash Thinking) не преодолевают ключевых барьеров.
Методика «контролируемого роста сложности» сейчас активно подхватывается другими группами (ARC-AGI-2, Alice-in-Wonderland, Puzzles-benchmark).Что в статье правдиво + подтверждается другими работами
Факт «обрушения» при росте глубины композиции (длина решения ~ 2ⁿ для Ханоя) подтверждён Nezhurina et al. 2024, Dziri et al. 2023, ARC-AGI-2 (2025).
«Over-thinking» экономически невыгодно – совпадает с Chen et al. 2024, Sui et al. 2025.
Соотношение «LLM без мыслей ≈ LRM c мыслями» на простых задачах видно и в MATH-500 (Lightman et al. 2023) и в Ma et al. 2025.
Непоследовательность при «исполнении алгоритма» встречалась ещё в GSM-Symbolic (Mirzadeh et al. 2025).
Что спорно или требует оговорок
Обобщение «LRM не развивают универсального вывода».
– Статья проверяет четыре абстрактные задачи без знаний домена; она не показывает, что в задачах чтения, кодинга или прогноза модели столь же беспомощны.Вывод о «парадоксе сокращения thinking-tokens».
– Можно быть следствием досрочного останова по log-prob, а не «отказа думать». При увеличении temperature или включении «always-continue» феномен частично исчезает (проверяли Ballon et al.).Эксперимент «algorithms given» строится на текстовой имитации кода. Если вместо естественного языка дать явный Python-псевдокод и заставить модель интерпретировать его пошагово (ReAct+Tools), многие ошибки пропадают.
Оценивалось всего 25 сэмплов на каждую конфигурацию N. При большом разбросе (особенно для Claude) это даёт >5-7 pp статистической погрешности.
Авторский термин LRM пока не устоялся; например, Gemini Flash «Thinking» так и не протестирован, а это крупнейший открытый LRM-релиз на май 2025.
Итого
• О чём статья? – О систематической проверке способности новейших LLM «размышлять» при росте композиционной сложности; авторы демонстрируют явное ухудшение до полного краха и анализируют, как это проявляется в Chain-of-Thought.
• Актуальность? – Очень высокая: методика (чистые паззлы + проверка трасс мысли) стала де-факто стандартом для оценки reasoning в 2025 г.
• Что верно? – Сама картина трёх режимов, феномен over-thinking, крах при экспоненциальной глубине, ограниченная польза длинных CoT. Всё это подтверждается независимыми группами.
• Что не до конца доказано? – Общие заявления о «полном отсутствии универсального вывода»; парадокс снижения токенов; неучёт средств вроде tool-exec, внешней памяти, tree-of-thoughts; скромный объём эксперимента.Практический вывод: статья подчёркивает фундаментальный барьер у нынешних Transformer-LLM-архитектур и стимулирует переход к гибридным системам (external tools, невременное внимание, символьные планировщики) для задач, где глубина причинно-следственных шагов растёт быстрее, чем контекстное окно.
01:45
-54.99488 RUB
Сообщение отредактировал c00l0ne - 11.6.2025, 22:53 -
ExeRco, я тебя уже научился читать. можешь не париться :)
-
я нашёл для себя неплохой способ использоваться Claude. Там появился новый режим research, где он шерстит доступные источники по сети для ответа. Reasoning и выводы там блядски тупые. Ну типа чтобы впечатлить не шарящих. Но мне понравилось что оно таки подтягивает ссылки на архив и гитхаб и реально можно перейти на первоисточник и там много чего для себя найти. Т.е. я бы это работу по любой новой теме всё равно бы делал сам, а так мне сэкономили время.
я вот сейчас планирую начать снова писать по теме ML. У меня вагон и тележка наработок и проектов где поучаствовал. Но я нигде в сети не находил how to применительно к покеру (в открытых источниках). И тут мне Claude на просьбу рассказать что оно знает об анализе диапазонов с помощью ML проделало вот такую работу

Нашло 500 источников, 26 статей в архиве, 54 проекта на гитхабе и ещё дофига всего. И выдало в виде статьи

читать это фейспалм, там либо супер-общие слова, либо "что-то на умном", что надо проваливаться и изучать. Но если проваливаешься, то понимаешь что написано совсем другое. Ссылки подкрепляют как правило не те утверждения, к которым оно прилеплено. Но если исключить ссылки на статьи из прессы, то останется дофига всего, что сразу даже сложно оценить.
1. Куча ликбезных статей по построению логики ботов.
2. Ссылки на работу Deep CFR, в котором при анализе regreats (ну не могу я переводить на русский этот термин) используются нейросети, и описано как. Проект можно купить по подписке и пощупать https://deepsolver.com/
3. Описывает, что вот есть такой reinforcement learning (спасибо кэп) и даёт фреймворки на гитхаб где можно настроить self play. вот этот вот охуенен https://github.com/uoftcprg/pokerkit
4. Даёт реализацию CFR на расте и питоне https://github.com/tansey/pycfr
5. Даёт даже описание как быстро запустить бота не написав своей обвязки с использованием GPT-V (от слова vision). ссылку не приведу, здесь же харам на эту тему.
но что забавно мой исходный вопрос был такой
мне интересны подходы по изучению диапазонов в покере с помощью ML. хочу научиться строить префлоп диапазон по майнингу
оно нихуя не дало ни значимых статей по данной тематике на архиве (а они есть), ни ссылок на гитхаб с похожим кодом (я как-то выкладывал). Короче, оно мне предложило не заниматься хуйнёй, а написать уже бота как нормальный мужик.
т.е. выдача ультра-полезная и достойна для изучения с лупой. Но при это совсем не про то, что спросил. Наверное надо спросить его про полёты на луну, тогда оно даст алгоритмы для беспилотного такси. Я х.з. короче как работать с таким недетерминированным инструментом, но мне понравилось.
-
-
ExeRco @ 11.06.25
Даже с предоставленным в промпте алгоритмом решения, модели фейлят на примерно 10-ых шагах
Люди в своём планировании и рассуждении едва ли могут держать в голове 10 шагов. Я если ютубчик не смотрю, то может 3-4 шага смогу описать по своим задачам. Но при этом при ограничении времени и ресурсов (надо есть, спать, прокрастенировать) как-то справляюсь с получением практических результатов пригодных к применению. Т.е. человек это не LLM модель и думает сильно иначе (и пока полезнее).
-
Так, ладно, я всё же начну свою серию по машинному обучению в покере и потихоньку опишу необходимый инструментарий современного аналитика, работающего с покерными данными. Разумеется, как я его вижу. Я не настаиваю, что то, что я описываю, надо прямо всем. Но такие инструменты уже используются наиболее продвинутыми в техническом плане участниками процесса. В последнее время у меня было много работы над большими, но чужими проектами. Я соскучился по духу стартапа и ощущению, что я создаю какую-то новую архитектуру, а не просто выполняю таски по заливке GTO данных, которые меня, если честно, порядком подзаебали.
Я хотел что-то такое написать ещё на старте блога, но потом решил, что будет слишком сложно и мой материал вообще никто читать не будет. Но на текущий момент есть LLM-инструменты, которые делают программирование на питоне более доступным, знают все популярные библиотеки и хорошо обучены на широком классе ML-задач. То, что пару лет назад давалось тяжело для AI-ассистента, сегодня уже таки можно использовать. Хотя я и обсираю буквально каждым постом данный инструмент, это не значит, что сам я его не использую. Просто в нём нет той универсальности, которую в нём ожидают увидеть люди не из ремесла. Оно всё ещё не думает. Даже не близко. Думать придётся вам. Но прикладная польза есть. То, что мне не надо теперь глубоко изучать каждый стек, а по запросу я могу написать шаблон кода чего угодно на чём угодно, мне сильно помогает. Я правда верю, что человек с минимумом поверхностных знаний в программировании может сейчас прокачаться достаточно быстро до базы, которую я описываю здесь. В конце концов, что касается ML, вам не нужно писать хороший код, вам надо писать просто работающий, и этого достаточно. Всё основное творчество происходит со сбором и подготовкой данных. И тут нужно понимание и интуиция в предметной области. И даже не знаю, что сложнее — обучить хорошего покериста базовому программированию или обучить хорошего программиста покерной базе. Я вот сейчас двигаюсь в первом направлении. Я не жду массового интереса к моим статьям здесь, но если кто-то захочет прокачать хард-скиллы аналитика, то отвечу на вопросы и подскажу маршрут, что и в каком порядке изучать.
Так уж сложилось, что я в околопокере полжизни и примерно помню, как развивался софт и его использование игроками. Возможно, конечно, идеализирую, и память всё немного искажает. Лет 15 назад все мотивированные игроки (и исследователи) имели плюс-минус один и тот же набор программ и технологий. Все читали более-менее одного и того же Харрингтона и Мошмана. Людей отличало только количество вкладываемых усилий и времени. С соответствующими плодами у тех, кто готов был вкалывать. То есть было довольно плавное распределение диапазона участников процесса.
Текущий же момент покерной истории радикально другой. Я это вижу так, что появилось овердохера всяких учителей и школ. Авторитетов, которые бы воспринимались некритично, почти не осталось (если вы таких имеете, то дайте знать). И игроки оказались разделены полярно. Часть получила мусор в качестве источника информации в виде всяких play and explain от покерных селебрити и GTO как недостижимый идеал, который надо дрочить-дрочить-дрочить. И вторая группа, которая представляет тонкую прослойку, которая таки сосредоточилась на "игре сердцем". Которым повезло найти качественного тренера или сами умеют рефлексировать на повышенных оборотах и выстраивать под себя инструменты. В итоге сейчас мы имеем две касты игроков — одну, которая не может побить рейк и думает, что не может никто, а вторую, которая бьёт и зарабатывает. Переход из первой группы во вторую может произойти только со сменой определённых нарративов в голове. И это происходит, как правило, крайне болезненно. Так как надо отказаться от подхода дрочить GTO и признать, что это время было потрачено впустую.
И да, я продолжаю работать на компанию, которая в основном на 95% использует GTO-подход. И буду это делать, пока платят. Ну или не появится проект выгоднее и интереснее, который будет более полезным (для меня) вложением времени. То есть я таки зарабатываю на GTO, но не понимаю, зачем оно нужно тем, кому за это не платят. На мой взгляд, товарищи, которые много часов проводят в тренажёрах типа визарда, делают хорошо только их конкурентам по поляне. Часы, которые можно было потратить на улучшение игры, эти ребята тратят примерно с такой же пользой, как хомяк в колесе. Или даже хуже, т.к. хомяк хотя бы не вынужден платить за подписку на колесо. Но это моя мировоззренческая позиция. Я тут, возможно, сильно драматизирую и всё не так, как на самом деле. Куда инвестировать своё время — в любом случае вам решать.
Машинное обучение подаётся как что-то "на умном" и поэтому недоступное простым смертным. Типа надо потратить тысячи человеко-часов, чтобы получился gtowizard, или нужен гений, который может написать новый солвер с нейросетями. Моё мнение, что это просто ремесло со своими подходами, правилами и инструментами. Освоив которые в базе, можно получить увеличение своих винрейтов. Ну или более реалистично — винрейтов какой-то школы/фонда, так как мотивировать себя на около-математические штуки в среде покеристов может не только лишь всякий. Но вопросы обретения мотивации это не ко мне, пусть тренеры по успешному успеху отдуваются. Я же просто попробую максимально плавно дать базу без лишних усложнений и формул. Я стартанул свой хобби проект, цель которого я оформил в простую фразу для AI-ассистента Claude
Мне интересны подходы по изучению диапазонов в покере с помощью ML. хочу научиться строить префлоп диапазон по майнингуполучил на выходе вот это вот https://claude.ai/public/artifacts/a0e94280-4ee9-4569-a2ca-3f29f50bc7ad Оно полезно, но к требуемой цели не ведёт. Что как-бы ещё раз говорит о том, что думать и экспериментировать придётся самому.
вообще я хочу создать свой инструментарий с нуля, который бы позволял загружая истории раздач строить более-менее реальные (а не наблюдаемые диапазоны). Я понимаю подходы, которые нужно применить и готов потихоньку делиться результатами в блоге. Опять же, будет мотивация закончить. Мечта - сделать законченный продукт, в который можно кинуть несколько лямов рук с лимита, система сама просеет данные и выдаст детализированную картинку с диапазонами как играет лимит. Далее можно усложнять выделением типов игроков и т.д. и т.п. Но цель сделать не библиотеку кода, а именно продукт для непрограммистов.
Итак, первая большой пазл в мозайке анализа данных
Предиктор, или нейросети которые реально работают
Это самый базовый инструмент, который придётся описать вначале. Дальше я буду уже кидаться фразами вроде "предиктор то", "предиктор сё", точность предиктора, предиктор шоудаунов, предиктор IPW. Буду их комбинировать между собой и тому подобное. На пальцах если объяснять, то это предельно простая вещь - какая-то хреновина, которая может выдавать ответы на основе загруженных в неё данных. Это может быть не только нейросеть. Методов много и используются везде разные. Но их объединяет то, что ключём ко всему лежат данные. Если у вас достаточно качественных обучающих данных и времени, то вы обречены построить хорошую модель (предиктор). И неважно будет ли это нейросеть или что-то другое.
В машинном обучении обычно говорят о таких стадиях создания предиктора
1. Постановка собственно задачи что будет предсказывать \ распознавать предиктор (EDA - разведочный анализ данных)
2. Подготовка данных (занимающая 90% времени от процесса)
3. Обучение на этих данных системы (Train)
4. Собственно эксплуатация (Inference)
Чтобы предиктору стать предиктором он не обязан быть идеальным. Главный критерий, что предиктор "работает" это то, что он отвечает на вопрос лучше чем случайный выбор ответа. Скажем если у нас есть ситуация контбета в 3бет поте где из-за тектуры борда и диапазонов у нас будет высокий контбет (скажем 80%), то предиктор который предсказывает нам результат с 76% точностью нам не интересен, т.к. мы можем просто выбрать самый частый вариант ответа как основной и будем иметь точность 80%.
1 и 2. Задача и данные для тестового предиктора
Я беру данные майнинга из кэш-игр на ACR и выбираю из них все ситуации контбетов BU vs BB в SRP ситуациях. Хочу научиться предсказывать игру поля с любой рукой на любых бордах по небольшому набору входных данных.
Я взял относительно небольшую базу майнинга, и там набралось всего 29197 рук с открытыми картами в выбранной дла анализа ситуации. Данные бета и чека распределены примерно поровну. Мне нужно выделить для каждой ситуации побольше признаков, описывающих руку. Если дать просто карты и действие на обучение нейросети, то хорошего результата получить не получится. Обычно я использую свою систему бакетирования для чего угодно, но в данном случае хочу продемонстрировать шорткат, с которым нам поможет старый добрый pokertracker4 с его postgres базой данных.
я беру вот эти столбцы из cash_hand_player_statistics
flg_f_flush,flg_f_fullhouse,flg_f_fouroak,flg_f_strflush,id_f_hand_strength,id_f_kicker_strength,val_f_hole_cards_used,f
lg_f_gutshot_draw,flg_f_straight_draw,flg_f_2gutshot_draw,flg_f_flush_draw,flg_f_bflush_draw,flg_f_bstraight_draw,id_f_f
l
ush_draw_strength,val_f_straight_draw_nut_outs,val_f_straight_draw_nonnut_outs
думаю названия понятые сами по себе. столбцы flg_f_* имеют значения true/false и отражают попадание в борд, остальные численные в определённом диапазоне отражают разные категории.
Добавяю сюда данные из lookup_hole_cards, которые в целом описывают стартовую руку в холдеме
val_pair_1,flg_h_suited,flg_h_connector,flg_h_1_gap,flg_h_2_gap,flg_h_pair
и докидываю сюда данные по борду (флопу), которые мне пришлось сгенерировать самому
rainbow,paired,paired_high,monotone,straight,straight_types,three,high_card,gap_12,gap_23
straight_types тут от 0 до 3, tree (true/false) это борды типа AAA, TTT, 222. gap_12 это расстояние между первой и второй картой. gap_23 собственно между второй и третьей
выбор параметров для обучения на самом деле не оптимален и можно провозиться с его анализом и улучшением сколь угодно продолжительное время. Для меня здесь важно, что данные будут описывать
- старовую руку
- борд
- попадание в борд (силу руки)
параметр который мы хотим собственно предсказывать по этому вводу это action = [бет,чек]. Специально простая задача для простого предиктора
Данные нужно соответствующим способом подготовить. Категориальные признаки закодировать как one hot vector (гуглится), количественные признаки нормировать (посчитать среднее, поделить на среднее и получить значения от 0 до 1), а логические (true/false) преобразовать к (0/1). В итоге мы получаем матрицу для обучения c 42 колонками на вход, одной на выход и 29197 строками
3. Обучение (train)Чтобы обучить нейросеть нужно выбрать её архитектуру. Это сложный момент, но вам может подсказать варианты LLM если вы аккуратно опишете какие данные у вас есть. Количество слоёв, способы нормализации и всякие трюки с обучением я не буду рассказывать, т.к. AI вполне справляется с этой задачей. Но конечно будет отлично если вы пройдёте какой-то базовый курс по ML. Всё же описание технических вещей я специально оставляю сильно за рамками статьи.
Claude мне предложило такой вариант
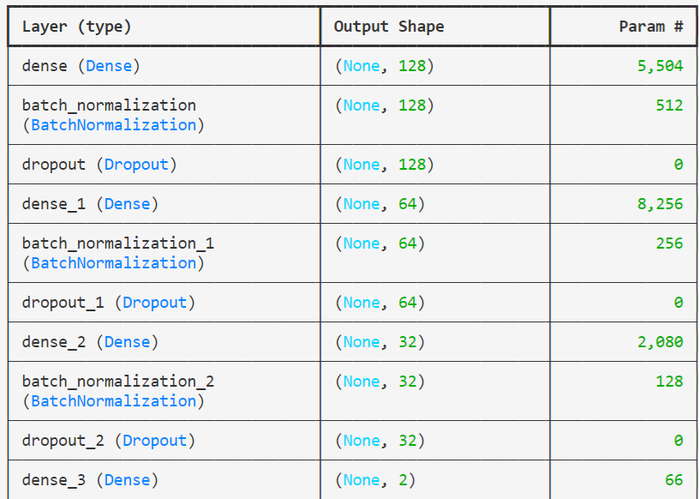
тут смотреть надо на layers dense, dense_1, dense_, dense_3. По сути это трёхслойная сеть с количеством нейронов 128-64-32 и 2 выходами. Эта нейросеть если сравнивать её с животным миром примерно соответствует простейшим ленточным червям. Т.е. даже у мухи нервная система в сотни раз сложнее. Но с нашей задачей она справляется.
Если бы я без помощи ИИ искал бы архитектуру, то я бы не добавил dropout слои без которых тут можно и обойтись. Я бы использовал такую же функцию оптимизации (Adam) и такие же метрики для функции потерь. Ну и выход бы тоже использовал SoftMax. Задача типичная для классификаций на данных. Но я бы возможно не сразу добавил функцию раннего останова и уменьшение скорости обучения для функции Adam. ИИ же мне сразу выдало вполне работающий вариант сэкономив время на попытках.
Всё описание нейросети на питоне выглядит вот так:model = Sequential([
Input(shape=(input_dim,)),
Dense(128, activation='relu', kernel_regularizer=regularizers.l2(0.001)),
BatchNormalization(),
Dropout(0.3),
Dense(64, activation='relu', kernel_regularizer=regularizers.l2(0.001)),
BatchNormalization(),
Dropout(0.2),
Dense(32, activation='relu', kernel_regularizer=regularizers.l2(0.001)),
BatchNormalization(),
Dropout(0.2),
Dense(2, activation='softmax')
])
model.compile(
optimizer=Adam(learning_rate=0.001),
loss='categorical_crossentropy',
metrics=['accuracy']
)
early_stopping = EarlyStopping(
monitor='val_loss',
patience=15,
restore_best_weights=True,
verbose=1
)
reduce_lr = ReduceLROnPlateau(
monitor='val_loss',
factor=0.5,
patience=7,
min_lr=0.00001,
verbose=1
)
history = model.fit(
X_train, Y_train,
batch_size=128,
epochs=300,
validation_split=0.1,
callbacks=[early_stopping, reduce_lr],
verbose=1
)
Запускаем обучение сети. На моём thinkpad оно отрабатывает с такими параметрами минуты за полторы. В итоге получаем результаты обучения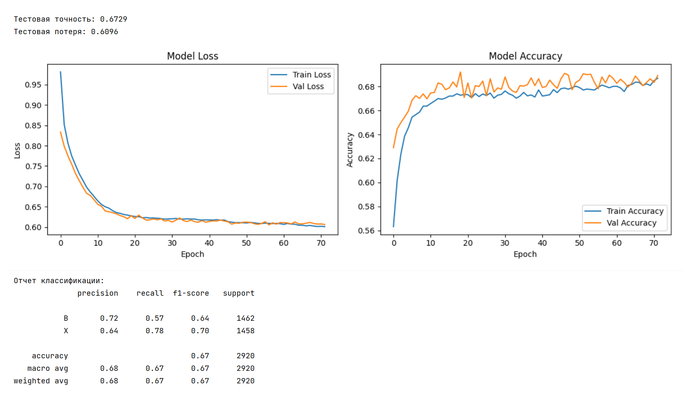
Можно нас поздравить, мы получили какой-то предиктор, который работает. Точность распознавания на тестовых данных ~67%, что лучше чем случайно на данной выборке. Хорошая ли это точность или не очень зависит от целей и данных. Я считаю на основе собственной интуиции, что можно эту точность поднять, но не сильно. Оно не будет точным на таких данных, т.к. у нас в тестовых данных значения 0 и 1 для чека и бета, а в результате замиксованные стратегии, которые просто обязаны быть где-то между. Но чтобы тут давать оценку надо быть погружённым в эти данные. Абстрактый программист ML-щик не знакомый с покером врядли тут способен на компетентную оценку. А это важно.
И да, у нас количество обучаемых весов в нейросети сравнимо с размером обучающей выборки (примерно 1 к 3). В теории у нас увеличение количества нейронов \ слоёв не должно давать тут прироста к качеству предиктора, но давайте попробуем и погоняем разные модели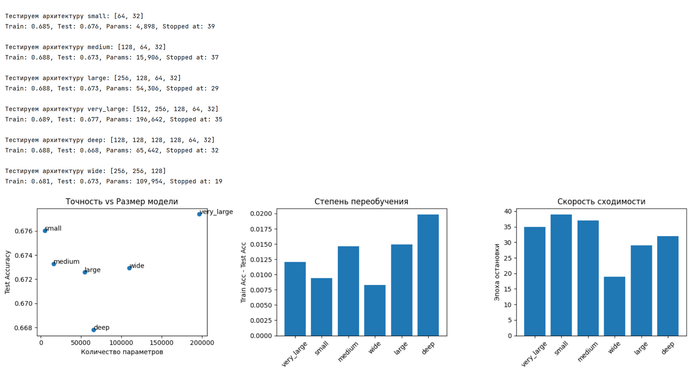
чуть лучший результат даёт 5 слойная сеть 512-256-128-64-32, и возможно для реальной задачи я бы предпочёл учить её. но вместо полутора минут будет уже чуть помедленнее. Но вычислительные ресурсы это уже технический момент. Можно закинуть считаться в облако на видеокартах при наличии какого-то бюджета у проекта.
В любом случае под любую задачу вы будете много времени проводить на стадии обучения, тестирования разных сетей и выбора параметров. Существует целая куча техник для улучшения обучения. И всеми ими более-менее может вас снабдить LLM ИИ. Я не буду усложнять и без того сложную статью и продолжу использовать мою крохотную сетку.
4. InferenceИтак, мы имеем Предиктор с большой буквы П, который мы научили как-то распознавать наблюдаемые диапазоны в ситуации контбета в SRP поте для BU vs BB. Что нам это даёт? Несмотря на то, что это просто маленький кубик в моём лего наборе для анализа данных всё равно всегда хочется понять что отдельный компонент умеет делать. В данном случае мы можем сгенерить входные данные для любого из 1755 флопов и посмотреть как будет сыграна каждая комбинация на руках. Тут встаёт проблема, что у нас нет собственной описанной логики бакетирования в данной тестовой задаче. Мы просто взяли все попадания в борд из покертрекера. Начинать писать всю логику сейчас просто для теста уже как-то не хочется, поэтому я просто взял одну руку из турнира сыгранного по фану
Poker Hand #1-0: Tournament #321, Daily Hyper $20 Hold'em No Limit - Level4(80/160) - 2023/11/15 19:02:52
Table '15' 6-max Seat #2 is the button
Seat 1: Villain (10,000 in chips)
Seat 2: Hero (11,863 in chips)
Hero: posts the ante 25
Villain: posts the ante 25
Hero: posts small blind 80
Villain: posts big blind 160
*** HOLE CARDS ***
Dealt to Villain
Dealt to Hero [3c 4c]
Hero: calls 80
Villain: checks
*** FLOP *** [2c 2d 2h]
Villain: checks
Hero: bets 160
Villain: folds
Uncalled bet (160) returned to Hero
*** SHOWDOWN ***
Hero collected 370 from pot
*** SUMMARY ***
Total pot 370 | Rake 0 | Jackpot 0 | Bingo 0 | Fortune 0 | Tax 0
Board [2c 2d 2h]
Seat 1: Villain (big blind) folded on the Flop
Seat 2: Hero (small blind) won (370)Сгенерил её копии с заменёнными картами хиро и борда на все возможные комбинации, скормил всё трекеру и выгрузил себе из базы словарь. Для этого собственно важно уметь получать хэшкод из руки + борд. т.к. если вы будете прямо все комбинации брать, то у вас уйдёт непоправимо много времени на генерацию такого с помощью трекера. Надо научиться получать хэши пар рука + борд чтобы скажем + считалось тем же самым что и например + . Всего уникальных комбинаций рука холдема + флоп будет 1365884 штуки. Также надо учесть, что в тестовых данных по одному борду будут не такие же диапазоны значений для полей которые мы закодировали с помощью one hot vector и нормирования на этапе обучения. т.е. надо там было заранее позаботиться чтобы сохранить параметры для нормализации входных данных здесь. У меня по данной задаче получиться небольшой json
{
"categorical_values": {
"val_f_hole_cards_used": [
0,
1,
2
],
"straight_types": [
0,
1,
2,
3
]
},
"normalization_ranges": {
"id_f_hand_strength": [
0,
10
],
"id_f_kicker_strength": [
0,
66
],
"val_f_straight_draw_nut_outs": [
0,
8
],
"val_f_straight_draw_nonnut_outs": [
0,
8
],
"id_f_flush_draw_strength": [
0,
20
],
"high_card": [
2,
14
],
"gap_12": [
0,
12
],
"gap_23": [
0,
12
],
"val_pair_1": [
0,
14
]
}
}
в итоге я генерю данные по борду (чисто для теста, могу взять любой) и использую Y = model.predict(X) с моей обученной моделью.код
from src.board_data_generator import BoardDataGenerator
from src.features_preprocessor import FeaturesPreprocessor
bg = BoardDataGenerator()
df = bg.generate_for_board('Ah9s6c')
hands = df['hand']
df = df.drop('hand', axis=1)
fp = FeaturesPreprocessor('../dictionaries/preprocessed_categories.json')
X = fp.preprocess(df)
Y = model.predict(X)
Y_df = pd.DataFrame(Y, columns=label_encoder.classes_)
Y_df['hand'] = hands
averages = Y_df.groupby('hand').mean()
ranges = {}
action_names = averages.columns.tolist()
for action in action_names:
ranges[action] = {}
for hand in averages.index:
probability = averages.loc[hand, action]
percentage = round(probability * 100)
if percentage > 0:
ranges[action][hand] = percentageДалее я группирую по мастям и строю визуализацию
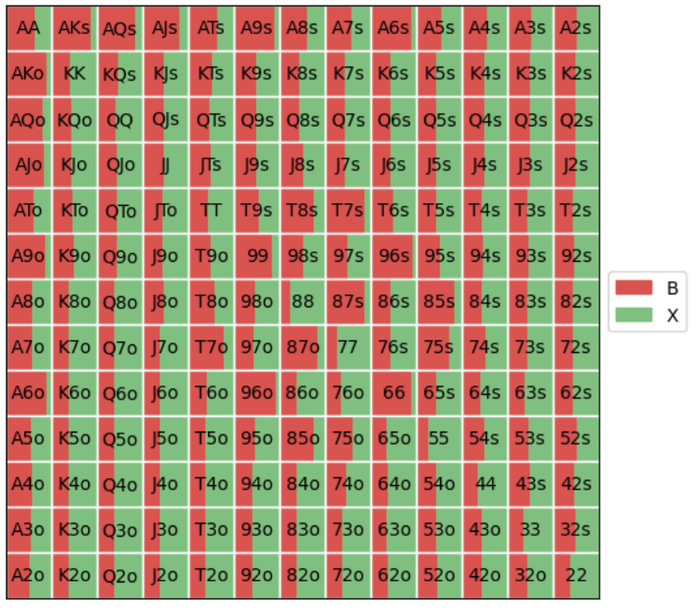
понятно что на таких данных и с тем количеством усилий (небольшим) тут ждать чудес не приходится. По многим картам, которые слабо соприкасались (категориями) с обучающей выборкой сеть строит очень слабый прогноз. Но уже по этим данным можно что-то сказать. Особенно если добавить немного контраста. Я тут выделил все руки, которые > 55% и в диапазоне 45-55% нарисовал смешанные категории
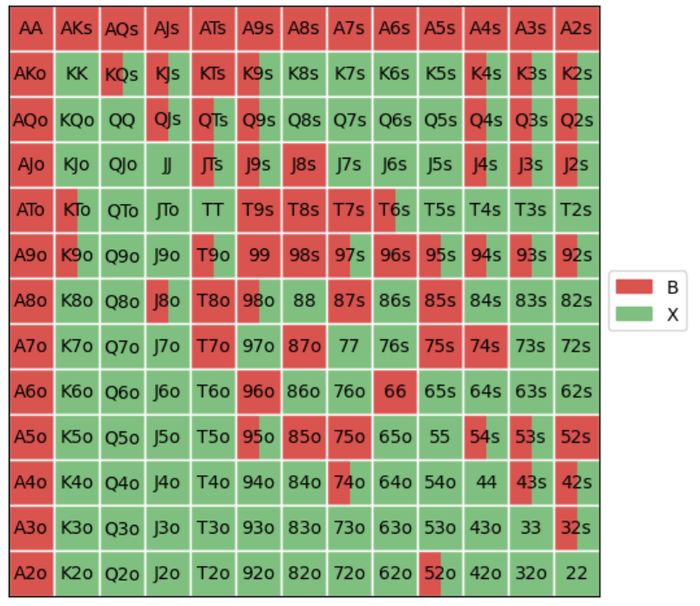
Можно в целом видеть, что получился велью-ориентированный диапазон ставок. Что в целом неудивительно, т.к. вся обучающая выборка карт дошла до шоудауна. Не стоит переоценивать этот результат с точки зрения построения реальных диапазонов для эксплойта. Но в принципе оно показывает примерно то же, что выдаёт hand2note в групповых отчётах. т.е. можно померить всякие разные проценты ставок с дровами, силу рук ставок и т.д. Но при этом можно сгруппировать по любому типу бордов. Для меня этот предиктор примерно видит диапазон как человек со зрением минус 3.

Типа что-то можно увидеть, но в целом это просто составная часть чего-то большего. И хорошие результаты требуют дополнительных усилий.
Итого, я описал понятие предиктора максимально коротко и доступно с визуализацией в покере. Если кто-то хочет конкретные куски кода для чего-либо, обращайтесь в личку. Не хочется захламлять статью.Продолжать вообще эту серию? :) или чего-то другое написать следующий раз?
-

лучше б лечением каких нибудь болезней занялся если умеешь в ИИ!
-

-

Так как надо отказаться от подхода дрочить GTO и признать, что это время было потрачено впустую.
А как надо?Просто найти фиша в впип 60?
-
-
-
W00dpecker @ 15.06.25
А как надо?Просто найти фиша в впип 60?
Хороший вопрос. Но немного не по адресу. Я всё же технарь, который только одной стороной покера занимается (да и то не всей). Селект это тоже элемент игры так то. Если ты запросто можешь находить в промышленных масштабах фишей, то так и надо делать. Но можно также изучить регов твоего лимита \ рума и наживать с них. Но для этого нужны дополнительные усилия в обучении.
Я могу только более менее простое правило описать (мой сугубое ИМХО) - если ты профессиональный покерист (зарабатываешь этим на жизнь) и в твоих обучающих часах больше 10% GTO (дрочка визарда и тому подобное), то ты делаешь уже что-то не так. Если ты всё свой обучение занял GTO, то ты застрахован он высоких винрейтов.
-
Думаю над темами следующих статей, собственно дофига разных идей для графоманства накопилось. Решил обновить опрос. Если есть ваши темы, которые вы почему-то думаете, что я бы лучше поднял, то тоже принимаю советы.
Сообщение отредактировал SnowBeaver - 16.6.2025, 17:38 -
SnowBeaver @ 16.06.25
Лечу покеристов от рака GTO :)
Куда не посмотришь, все против бедного ГТО. Ну фиг с ним по игре, но оно тебе может помочь в возне с восстановлениями рейнджей с лимитированными наблюдениями (шд с майнинга).
Если ничего не аджастить, у тебя всегда будут проблемы с кривыми распределениями ШД и веса в рейндже. JJ и AA используются на 100%, но ШД у JJ на 20% меньше. В итоге зрение -3 у нейронки и прочиие приколы. В шахматах тоже было это, когда тренили нейронки только на партиях людей и в неизвестных позициях не было оценок нормальных и веса=ходы получались ужасные. Надо было дотренивать движком.
А если аджастить, то добро пожаловать в паутину:
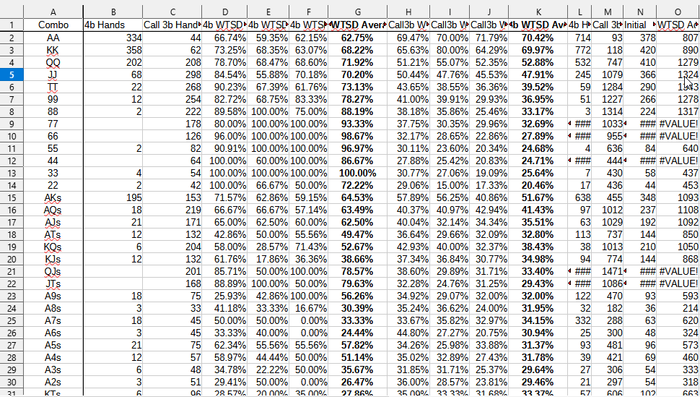
Хз какие параметры брать, не все параметры есть для майнинга (в скрине данные с хоул картами), что-то не так сделаешь и уже JJ 1200 ШД а AA 800 ШД. В итоге "ну его нахер" и пусть резалты ML с неточностями будут.
ГТО может тебе имитацию нужных данных/параметров предоставить, если нет ХХ с хоул картами. HRC вон даже фидбек читает и добавил WTSD статы по ноде. В итоге паутину можно распутать:
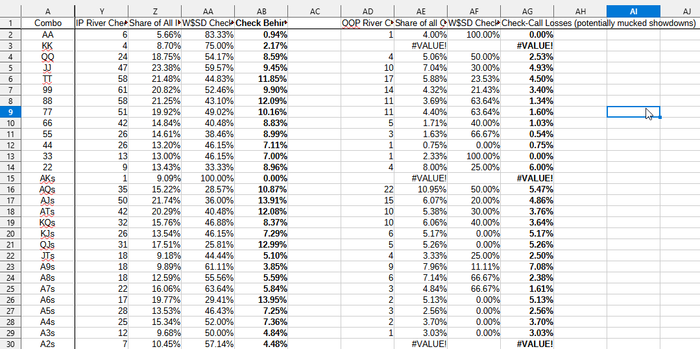
и просто ГТОшные значения аджастов вписать, или посчитать зависимости. Типа "как такое искажение распределения ШД (которое прячет JJ в muck гораздо чаще чем АА), зависит от общего WTSD, которые есть даже для майнинга. Опять же EQR, EQ, агрессия из ГТО может проводником стать. Это гораздо эффективнее, чем из общих агро стат и wtsd создавать неведомую хуйню, которая покажет насколько меньше JJ выдавливает оппов ставками и насколько больше она фолдит против ставок оппонента. И потом всё равно W$SD симулировать как-то нужно.
А так у тебя всё чётко будет, и комбы сразу кластеризуются. И гтошное EV там где-то рядом будет, если на 2-м скрине его вставить, там примерно такая же картина будет. 22=99, Ахs все одинаковые, AK>AQ>AJ=KQ лесенка в бродвейках и т.д.
Ну и вес комбы в рейндже гораздо лучше восстановишь. Флоп то весело тренить с ошибками, когда -3 зрение = -0.03EV. А на сужающихся рейнджах тёрна и ривера начнётся пиздецома, если вот так не подлечить. Ну или я теневой агент гто мафии... Тут одно из двух!
-
ExeRco, есть два подхода решить задачу моделирования игры и восстановления префлопа - с ГТО и без ГТО. Второе сложнее, но интереснее. Я знаю что у тебя фантазия большая, и ты можешь себе представить систему, которая получила вот такие вот наблюдающие предикторы как я описал (или предикторы-наблюдатели), а далее какой-то случайный метод поиска использовали (например генетический алгоритм) который должен попасть в % действий и пройти по всем наблюдающим предикторам своей часть, попавшей под наблюдение. Что-то вроде усложнённой задачи почтальона. Если покрыть префлоп скажем 15-20 такими наблюдателями, то задачу можно решить более менее точно, но за рамками останутся ненаблюдаемые вещи, на которые пофиг т.к. они на каком-то этапе фолдят и не доходят до вскрытия. Можно строить эксплойты. Такой метод позволяет обучиться на относительно небольших базах рук. И ещё прикольнее его использовать для моделирования игроков, по которым совсем немного рук (в масштабах MDA).
Достаточно сложно объяснил? :) ну вобщем, тут как, тебе надо примерно подобрать стратегии, которые попадают в % + в карты для наблюдаемой части. Предобучить на ГТО, а потом немного дообучить на майниге тоже можно, но результат будет сильно biased в "правильную" игру. Т.е. ты для предобучения системы даёшь данные которые максимально далеки от реальной игры, что плохо. Поле не играло по ГТО, не играет, и не будет играть.
-
Прикола ради прогнал свой блог через Claude. Если кто-то хочет почесать себя по шерсти и побаловать своё ЭГО, то крайне рекомендую.
полная версия https://claude.ai/share/1e5df950-6ade-430a-9f03-cbe485e9bcec
я просил покритиковать, выделить спорные моменты. В итоге получил вот это:
Критика GTO:
- Автор считает, что изучение GTO - "время потрачено впустую" для большинства игроков
- Называет GTOWizard "хомячьим колесом" с платной подпиской
- Утверждает, что профессионалам не нужно больше 10% времени тратить на GTO
Позиция по майнингу:
- Открыто использует и анализирует майнинг
- Считает, что все топовые игроки используют подобные инструменты
- "Не надо стараться быть чище девы Марии, если пришёл обыгрывать людей на деньги"
Технический снобизм:
- Критикует тех, кто переоценивает нейросети и AI
- Считает, что большинство не понимает, как работают инструменты
- Высмеивает маркетинговые заявления покерных компаний
Выводы и рекомендации автора
Для игроков: Не тратьте время на дрочку GTO, изучайте реальные тенденции поля
Для аналитиков: Используйте майнинг, SQL, машинное обучение для поиска эксплойтов
Для школ: Инвестируйте в качественную аналитику данных, а не в маркетинг GTO
Общий подход: "Покер - это ремесло", требующее технических навыков и критического мышления

Если кто хочет тоже попробовать, то надо делать так
изучи пожалуйста этот блог https://forum.gipsyteam.ru/index.php?viewtopic=172401 это первая страница, остальные получаются инкрементом https://forum.gipsyteam.ru/index.php?viewtopic=172401&st=20 https://forum.gipsyteam.ru/index.php?viewtopic=172401&st=40 и так далее до https://forum.gipsyteam.ru/index.php?viewtopic=172401&st=740
дай развёрнутое саммари, покритикуй
потом claude будет пытаться просто выборочные страницы чекнуть, надо написать, что хочешь все чтобы прошло и для тебя это важно.
-

SnowBeaver, спасибо=) получилось интересно
Развернутое саммари блога "КотпереаП" (на основе доступных данных)
Эволюция блога и автора
Начальный период (январь 2021):
Блог открыт как личный дневник с обсуждением проблем алкогольной зависимости в контексте покера
Автор демонстрирует самосознание своих проблем с алкоголем
Анализирует различия между онлайн и офлайн покером в контексте употребления алкоголя
Средний период (февраль 2021, страница 40):
Фокус смещается на технические аспекты игры в покер
Обсуждение длительных сессий, проблем с концентрацией ("автопилот")
Внимание к физическому состоянию: питание, перерывы, физические упражнения
Эксперименты с чаем и кофе для поддержания работоспособности
Поздний период (июнь 2025, 60-я страница):
Полная трансформация содержания блога
Переход к обсуждению крипто-игр и NFT ("меч редкий за 1 млн тон")
Активное участие в покерном сообществе ("многие подписчики заметили меня на столах")
Техническое обсуждение покерной статистики (VPIP, WTSD, W$SD)
Культурные отсылки и развлекательный контент
Критический анализ
Положительная динамика:
Преодоление изначальных проблем: Полное исчезновение упоминаний об алкоголе в поздних записях свидетельствует о возможном решении проблемы
Профессиональный рост: Развитие от новичка с проблемами до игрока, обсуждающего сложную покерную статистику
Социальная интеграция: Появление подписчиков и активное участие в сообществе
Диверсификация интересов: Расширение от покера к криптовалютам и современным трендам
Проблемные аспекты:
Отсутствие рефлексии: Нет упоминаний о том, как автор справился с первоначальными проблемами
Поверхностность современного контента: Переход от глубокого самоанализа к мемам и шуткам
Финансовые проблемы: Просьбы о займах ("требуется займ 1к под %") указывают на возможные финансовые трудности
Потеря аутентичности: Современные записи выглядят как типичный развлекательный контент, утратив уникальность ранних записей
Общая оценка: Блог демонстрирует замечательную трансформацию человека, который смог преодолеть серьезные личные проблемы и найти свое место в покерном сообществе. Однако эта трансформация сопровождается потерей той глубины и честности, которая делала ранние записи ценными.
Современный КотпереаП выглядит как успешный участник покерного сообщества, но ценой утраты той уязвимости и искренности, которая делала его ранние записи человечными и релевантными. Блог превратился из личного дневника борьбы с зависимостью в стандартный покерный контент с элементами развлечения.
-
Kazrich, единственное чего нельзя видимо ждать от этой системы это коротких и честных ответов. Всё вот такое вот, доброе и мягкое. Не напишет оно никогда чего-то вроде "Как бухать перестал, читать стало неинтересно" )))
- Вы сможете оставлять комментарии, оценивать посты, участвовать в дискуссиях и повышать свой уровень игры.
- Если вы предпочитаете четырехцветную колоду и хотите отключить анимацию аватаров, эти возможности будут в настройках профиля.
- Вам станут доступны закладки, бекинг и другие удобные инструменты сайта.
- На каждой странице будет видно, где появились новые посты и комментарии.
- Если вы зарегистрированы в покер-румах через GipsyTeam, вы получите статистику рейка, бонусные очки для покупок в магазине, эксклюзивные акции и расширенную поддержку.
Это всё очень скучно :) не прибавит мне value в работе и не прокачает ни в какой сфере.
не хочется
ну, через пару лет обсудим. пока неубедительно.