Data Adventures
-
ПопулярностьТоп-145
-
Постов919
-
Просмотров178,251
-
Подписок324
-
Карма автора+11,896
-
В модели дается прогноз не только дисперсии, но и матожиданию курса биткоина. Если перемножить все 5
+15
-
давай рейтинг топ токсиков теперь )))) Бачинский кстати активно лепил всем минуса в репу,
+13
-
Имея <> 23 года опыта в айти и <> 20 лет в покере, могу сказать что в покере сейчас день
+13
-
SnowBeaver, как будто x3 всё же завышено. Вообще в целом тренд такой, что много деняк дают тол
+11
-
Исследование прикольные, но выводы странные. Очень часто в коммьюнити минусют скамеров/арбитражников
+11
-
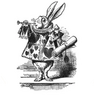
-
nardaykotu @ 08.07.23
Хочется уточнить: верхний график нормализован относительно количества рук? Интуиция вообще подсказывает, что чем глубже стеки, тем больше фишек разыгрывается и нормализованный график должен получится монотонно возрастающим. При этом частота игры в глубоких стеках низкая -- это да, и не нормализованный как раз должен выглядеть так. Но не уверен тут, поэтому собсна вопрос)))
Нет, он нормализован относительно общей суммы выигранных или проигранных всеми игроками фишек в данном турнире.
Что касается интуиции, то моя интуиция тут тоже не сработала. Это нормально. Я для этого в данные и полез. Хотел проверить свои гипотезы.
Ну и по факту, я не защищаю конкретные расчёты. я могу и ошибиться как в методе, так и в результатах. Я ещё буду другие эксперименты ставить и перепроверять всё. Просто мне показалось интересным описать инструменты.
Если меня вдруг осенит, что я люто накосячил, я просто напишу ещё одну статью, а в той сошлюсь, что смотри типа ниже как правильно :)
Сообщение отредактировал SnowBeaver - 8.7.2023, 21:53 -

SnowBeaver, не, ну если по колву рук верхний график не нормализован, то результаты получились как раз интитивными. Это как в ХА игре все фишки собираются так и же и тут, просто за счет того что в 30-40бб идет почти вся игра, и наибольшее колво рук отыгрывается в этих стеках то и сумма там окажется выше, чем в глубоких стеках несмотря на то что банки в глубоких стеках будут дороже, но просто это более редкие ситуации)
чтобы проверить это можно верхний график отнормализовать по количеству рук. Интуитивно должна получится монотонно возрастающая кривая. Будет интересно узнать, если это окажется не так)))
В общем, понял)) спасибо за ответ и удачи в рисече!
п.с. судя по графикам я так понимаю использовался matplotlib? могу посоветовать еще глянуть plotly, по коду тоже простая, а по информативности визуализаций там возможностей побольше) ну это если не лень разбираться)
-
nardaykotu @ 08.07.23
п.с. судя по графикам я так понимаю использовался matplotlib? могу посоветовать еще глянуть plotly, по коду тоже простая, а по информативности визуализаций там возможностей побольше) ну это если не лень разбираться)
Да мне всегда лень, хоть не в Экселе сделал, уже хлеб :) а так у меня весь инструментарий есть, сложности не пугают.
Можно строить графики по разному, но смысл такой, что ты конечно будешь разыгрывать большие банки в глубоких стеках, но не долго и где-то в начале турнира, где цена бб существенно меньше. А раз вся игра для тебя это в основном стеки 20-40, то и упор в обучении должен быть на них.
-

-
odt @ 09.07.23
А насколько сложно так же извлечь данные из базы х2на? Я сходу даже не смог разобраться, как её увидеть и подключить, даже его собственный пгадмин её не видит - всё где-то в конфигах есть, а я совсем не шарю, подскажи плз
добраться до базы можно, но смысла мало. Там всё в формате ключ-значение лежит. Как-то ревёрсить этот формат при наличии живого pokertracker я смысла не вижу. Т.к. мне было не надо, я не тратил на это слишком много времени.
-
Сегодня постараюсь рассказать про использование monkersolver в прикладных задачах, продолжу сыпать кодом на sql и исправлю немного ошибки из предыдущей статьи.
Вообще надо сказать, что использование солверов уже является стандартным инструментом для всех серьёзных игроков, а не только для профильных программистов и аналитиков. Если вы всё ещё возлагаете надежды на обучающее видео и думаете, что солверы это слишком сложно, что GTO не работает, что солверы дорогие и т.д. то к сожалению шансы зарабатывать в покере для вас становятся слишком малы. Любой кто хочет адекватные деньги в покере сегодня должен быть готов испачкать руки и хорошенько потрудиться. По факту даже самая подробная статья, которую я бы мог написать даёт лишь некоторый намёк как вы можете творчески подойти к процессу для себя. Я не в курсе, написал ли кто-то нормальный подробный обзор чем весь зоопарк солверов отличается, и как их выбирать под задачу. Могу как-нибудь изложить своё мнение, если будет интерес. Сам использую на постоянной основе 3 солвера и ещё 2 эпизодически.
Чтобы понять почему для конкретной задачи я использую monker, а не скажем HRC или SPH нужно разобраться с базовым принципом инструментов, которые считают равновесные стратегии. Хотя сейчас каждый второй (если не 2 из 3х) покеристов претендует на Знание (с большой буквы) GTO и работы солверов, по факту, когда кто-то пишет корректные с точки зрения логики вещи, то у многих подгорает. Я про эту статью https://www.gipsyteam.ru/news/29-03-2023/gto-dlya-chaynikov-vlastelin-mikrolimitov-delitsya-mudrostyu
и реакции на неё

Я для себя не люблю использовать аббревиатуру GTO, вместо этого я использую понятия "равновесная стратегия" и "оптимальная стратегия". Цель моего анализа перейти от первой ко второй. Идти по этому пути можно быстрыми и дешёвыми шагами, а можно мелкими и дорогими. В идеале нужно сначала пробовать дешёвые методы, а потом при наличии ресурсов и желания использовать дорогие и сложные. Зависит от того насколько оптимальной вы хотите получить стратегию. Ну и разумеется от того какие методы вам в принципе доступны. Можно себе условно представить между этими двумя терминами бегунок, где на каждое новое движение в право нужно приложить больше усилий. При этом для решения практической задачи (выигрыш денег за столом) скорее всего нет необходимости доводить эту задачу до конца и строить что-то сильно оптимальное. С какого-то момента price / reward ratio этой оптимизации становится слишком невыгодным.
Далее, для того чтобы эффективно пользоваться солверами необходимо разобраться EV (Expected Value). Это краеугольный камень, без которого дальше никуда. Если совсем по-простому, то это количество фишек (блайндов, денег...) которые вы на дистанции выигрываете в какой-то ситуации если играете по выбранной стратегии. Равновесная стратегия в солвере показывает ваше EV по позициям (в monkersolver, в других программах может выглядеть иначе).

Эти цифры соответствуют выигрышу \ проигрышу на дистанции для каждой позиции если все игроки за столом играют также по равновесной стратегии. Например по чартам gtowizard + ещё также идеально балансируют постфлоп. Эти значения являются усреднёнными для всех ситуаций, которые могут случиться с игроком на каждой из этих позиций. Если скажем вы находитесь на баттоне и перед вами все сбросились, то у вас будет EV выше чем 29.5 bb/100. чтобы узнать сколько именно надо экспортировать все диапазоны в данной ситуации и проделать с ними нехитрое преобразование, для которого нет публично доступного софта :) почему не знаю кстати. Но на всякий случай делюсь кодом
namespace ev_position
{
public class Program
{
private static Dictionary<string, (float weight, float ev)> LoadFromFile(string filename)
{
var res = new Dictionary<string, (float weight, float ev)>();
foreach (var line in File.ReadAllLines(filename))
{
var tokens = line.Split(new char[] { ',' });
res[tokens[0]] = (float.Parse(tokens[1]), float.Parse(tokens[2]));
}
return res;
}
private static float CalcEv(List<Dictionary<string, (float weight, float ev)>> items)
{
var hands = new HashSet<string>();
foreach (var item in items)
foreach (var h in item)
hands.Add(h.Key);
var evs = new Dictionary<string, float>();
var weights = new Dictionary<string, float>();
foreach (var h in hands)
{
evs[h] = 0;
weights[h] = 0;
foreach (var item in items)
{
if (!item.ContainsKey(h))
continue;
evs[h] += item[h].weight * item[h].ev;
weights[h] += item[h].weight;
}
}
var ev = evs.Sum(t => t.Value) / weights.Sum(t => t.Value) / 2000 * 100;
return ev;
}
public static void Main(string[] args)
{
var fold1 = LoadFromFile(@"C:\holdem\fold1.txt");
var call1 = LoadFromFile(@"C:\holdem\call1.txt");
var mr1 = LoadFromFile(@"C:\holdem\mr1.txt");
var evbb100 = CalcEv(new List<Dictionary<string, (float weight, float ev)>>() { fold1, call1, mr1 });
/*var fold1_new = LoadFromFile(@"C:\holdem\fold_new.txt");
var call1_new = LoadFromFile(@"C:\holdem\call_new.txt");
var mr1_new = LoadFromFile(@"C:\holdem\mr_new.txt");
var evbb100_new = CalcEv(new List<Dictionary<string, (float weight, float ev)>>() { fold1_new, call1_new, mr1_new });
var fold2 = LoadFromFile(@"C:\holdem\fold1.txt");
var call2 = LoadFromFile(@"C:\holdem\call1.txt");
var raise2 = LoadFromFile(@"C:\holdem\call1.txt");
var allin2 = LoadFromFile(@"C:\holdem\allin2.txt");
var evbb100_vs_co = CalcEv(new List<Dictionary<string, (float weight, float ev)>>() { fold2, call2, raise2, allin2 });
var fold3 = LoadFromFile(@"C:\holdem\fold3.txt");
var call3 = LoadFromFile(@"C:\holdem\call3.txt");
var raise3 = LoadFromFile(@"C:\holdem\call3.txt");
var allin3 = LoadFromFile(@"C:\holdem\allin3.txt");
var evbb100_vs_all_limp = CalcEv(new List<Dictionary<string, (float weight, float ev)>>() { fold3, call3, raise3, allin3 });*/
}
}
}и в этой ситуации открытия из BU для hero полученное EV будет равняться 41.17 по солверным данным. Обозначим эту ситуацию как А. Можете проверить свою интуицию и сравнить это EV с тем, что будет иметь игрок на той же позиции если против него зарейзил CO (ситуация B) или например залимпил весь стол - С.
расставьте по порядку A,B,C. Если для вас результат очевиден, то у вас интуиция, которая превосходит мою :) Ответ под спойлером
A = 41.17 bb/100, B = 46.06 bb/100, С = 24.26.
итого: C < A < B
Третий базовый принцип, который необходимо осознать для эффективного использования солверов это то, как степени свободы влияют на EV. Каждый раз, когда вы посчитали в солвере какую-то ситуацию, то на каждой позиции у вас будет какое-то исходное EV. Допустим у вас два игрока в ХА. игрок в позиции на префлопе зарабатывает какую-то сумму фишек +M, а игрок без позиции теряет эту сумму -М. Если скажем у вас для игрока в позиции заданы 3 разных сайза открытия и вы убираете один из этих сайзов, то вы уменьшили степень свободы этого игрока и его +М станет немного меньше и соответственно -М второго игрока чуть чуть увеличится. Если вы у игрока без позиции (на ББ) добавите разных сайзов 3бетов. скажем был один сайз, а вы добавили ещё возможность сделать allin, то его EV также возрастёт. И этот принцип работает практически везде. Я в начальных статьях рассказывал про найденную "ошибку" у gtowizard, где стратегии менялись от того, что не было возможности у игроков MP, CO поставить лимп вслед за ранним лимпером из UTG. Если им добавить эти лимпы, то их EV немного возрастёт за счёт отобранного EV у других позиций.
Самый крутой прирост EV можно получить если мы точно знаем диапазон опа. Например изучили его методами ML на больших данных по майнингу, или например мы знаем тот чарт, по которому играет наш оппонент, или скажем мы детально изучили как он разыгрывает разные руки на постфлопе и построили для себя контрстратегии. Но этот путь как раз дорогой. Он хоть и сильно смещает исходный бегунок в сторону эксплойта, но стоит значительных усилий и наличия большого количества данных. В действительности мы можем уточнить наше решение с помощью любой информации, которую мы знаем об оппонентах, в том числе и общие % статистик. Только из-за этой возможности я и использую здесь monkersolver. В нём можно для любого узла дерева выставить не только диапазон рук (что может каждый солвер), но и можно также задать общий % какого-то действия, и солвер будет балансировать дерево с учётом этого ограничения. К сожалению можно зафиксировать таким образом только какое-то одно действие. Это ограничение конкретной реализации, а не алгоритма, но что имеем, то имеем.
Я нашёл у себя ошибку в запросе из предыдущей статьи, где я обнаружил очень высокий пуш (рейз больше 4х бб) в стеках 19-21бб. Оно там возникло, т.к. я не выкинул из запроса коротышей. Более аккуратно посчитанный результат будет выглядет вот так

(sql)
with
limp_button_hands as
(select id_hand from tourney_hand_player_statistics s where s.flg_p_open_opp and s.flg_p_limp and s.position = 0),
limp_sb_hands as
(select id_hand from tourney_hand_player_statistics s where s.flg_p_limp and s.position = 9),
open_bu_hands as
(select id_hand from tourney_hand_player_statistics s where s.flg_p_open_opp and s.flg_p_first_raise and s.position = 0),
regs as
(select id_player from tourney_hand_player_statistics
group by id_player
having count(*) > 1000)
select p.position, p.description as pos_str,
round(sum(case when flg_p_open_opp and flg_p_first_raise then 1 else 0 end) * 100.0 /
nullif(sum(case when flg_p_open_opp then 1 else 0 end),0),2) as rfi,
round(sum(case when flg_p_open_opp and flg_p_first_raise and s.amt_p_raise_made < s.amt_before*0.4 then 1 else 0 end) * 100.0 /
nullif(sum(case when flg_p_open_opp then 1 else 0 end),0),2) as rfi_raise,
round(sum(case when flg_p_open_opp and flg_p_first_raise and s.amt_p_raise_made >= s.amt_before*0.4 then 1 else 0 end) * 100.0 /
nullif(sum(case when flg_p_open_opp then 1 else 0 end),0),2) as rfi_push,
round(sum(case when flg_p_open_opp and flg_p_limp then 1 else 0 end) * 100.0 /
nullif(sum(case when flg_p_open_opp then 1 else 0 end),0),2) as first_limp,
round(sum(case when cnt_p_face_limpers > 0 and flg_p_limp and cnt_p_face_limpers > 0 then 1 else 0 end) * 100.0 /
nullif(sum(case when cnt_p_face_limpers > 0 then 1 else 0 end),0),2) as limp_w_other,
round(sum(case when bo.id_hand is not null and amt_p_raise_facing < 0.15*least(amt_before,amt_p_effective_stack) and
flg_blind_def_opp and a.action = 'F' then 1 else 0 end) * 100.0 /
nullif(sum(case when bo.id_hand is not null and amt_p_raise_facing < 0.15*least(amt_before,amt_p_effective_stack) and
flg_blind_def_opp then 1 else 0 end),0),2) as fold2steal_bu,
round(sum(case when lb.id_hand is not null and cnt_p_face_limpers = 1 and flg_p_first_raise then 1 else 0 end) * 100.0 /
nullif(sum(case when lb.id_hand is not null and cnt_p_face_limpers = 1 then 1 else 0 end),0),2) as iso_bu,
round(sum(case when lb.id_hand is not null and lsb.id_hand is not null and cnt_p_face_limpers = 2 and flg_p_first_raise then 1 else 0 end) * 100.0 /
nullif(sum(case when lb.id_hand is not null and lsb.id_hand is not null and cnt_p_face_limpers = 2 then 1 else 0 end),0),2) as iso_bu_sb,
count(*) as hands
from tourney_hand_player_statistics s
--join regs r on r.id_player = s.id_player
join tourney_blinds b on b.id_blinds = s.id_blinds
join tourney_hand_summary ts on ts.id_hand = s.id_hand
join lookup_positions p on p.position = s.position and p.cnt_players = 9
join lookup_actions a on a.id_action = s.id_action_p
join tourney_summary tts on tts.id_tourney = ts.id_tourney
left join limp_button_hands lb on lb.id_hand = s.id_hand
left join limp_sb_hands lsb on lsb.id_hand = s.id_hand
left join open_bu_hands bo on bo.id_hand = s.id_hand
where b.amt_bb != 0 and round(least(s.amt_p_effective_stack, s.amt_before) * 1.0 / b.amt_bb,1) between 19 and 21
group by p.position, p.description
order by p.positionя также добавил в этот запрос статистики фолда на стил против баттона и изолейта против баттона и баттона+sb. Получить эти статистики напрямую в трекере уже не получится, но их всё ещё можно получить в запросе к базе.
В итоге я делаю lock на
- RFI по всем позициям кроме баттона
- Fold2steal для SB и BB
- ISO для SB и BB
- удаляю лимпы из всех позиций до баттона
Т.е. я лочу что-то у всех позиций кроме баттона и ограничиваю там степени свободы. Потому что я собственно и хочу сейчас оптимизировать игру для баттона с учётом поля. Результат выглядит вот так : VPIP на баттоне сильно вырос, что логично. теперь вместо фолда в 54% солвер предлагает делать это только в 39% случаев.

И наши локи в дереве привели к росту EV на BU с 29.5 bb/100 до 32.3 bb/100. Смысл здесь такой - даже если оппоненты играют идеально отбалансированно в рамках зафиксированных % их лока, они теряют деньги по сравнению с неэксплуатируемой стратегией. В реальной игре на практике эта теоретическая разница в 2.8bb/100 можно вылиться в любую сумму, которая >= 2.8bb/100. Т.е. следует ожидать, что живые люди играют хуже солвера. Если заглянуть чуть поглубже в это значение и сравнить исходное значение A = 41.17 с тем что получилось с локами, то A' = 49.22. т.е. в ситуации стила блайндов мы увеличили EV аж на 8бб/100, что на самом деле дохрена. Весь банкет за счёт игрока на BB с его оверфолдом. И это ещё очень хорошее значение для игрока на BB, т.к. солвер пытается оверфолд (8.1% -> 39.5%) перекрыть агрессией и задирает 3бет, чего обычные игроки скорее всего делать не будут. В базе будет крайне мало игроков, которые разгонят здесь 3бет до 20%.

И на практике мы скорее всего улучшимся на значения куда выше, чем 8бб/100 в игре против блайндов.
Что мы можем ещё здесь придумать для игрока на баттоне чтобы он ещё сильнее нагнул поляну? Я дальше вижу уже более дорогие усилия, которые требуют творческого подхода. Я уже усилил его на очень солидно просто загрузив сервер на ночь расчётом с локами, и в целом я вполне доволен результатом и могу на нём остановиться. Но какой дальшений план по улучшению я могу выбрать если таки решу это делать?
Первое что приходит в голову - кластеризация игроков. Очевидно, что реги и рекреационные игроки играют по-разному. Да и оба этих класса делятся на подтипы и можно купить дополнительный майнинг и "испачкать руки" данными ещё сильнее. Например если мы выкинем из нашего запроса статистик всех игроков, кто в данной базе наиграл меньше тысячи, то видим, что реги вообще не лимпят.

Т.е. я то ожидал, что наоборот реги чуть умнее будут играть и ближе к gtowizard, но всё наоборот.
Второе что можно использовать это собственно проанализировать диапазоны, которые не искажены постфлопом. Т.е.
- пуши
- колы пушей
- 3бет пуши
- колы 3бет пушей
И отсчитать против этих диапазонов стратегию в солвере с учётом того, что мы уже знаем по данным.
Дальше уже сильно более дорогие шаги с использованием методов машинного обучения, дешёвые карты из рукава уже разыграны :) Теперь уже мы захотим анализировать диапазоны, часть карт из которых не доходит до вскрытия, хотим определять тип игрока по малой выборке раздач на основе общей базы и т.д. И вовсе не факт, что мы где-то на этом сложном пути найдём такие крупные дыры в EV как 8бб/100
P.S. если у нас на малом блайнде будет нит с фолдом 93% (ну или вообще в ситауте), то стил с баттона становится выгоден с any two :)
Сообщение отредактировал SnowBeaver - 16.7.2023, 10:23 -
Сегодня я буду рассказывать как анализировать пиханину. Как бы нам не хотелось показывать скил и обыгрывать наших оппонентов на стеки в МТТ, это всё равно игра где нам придётся часто пихать. Ну и если мы будем играть хорошо, то в нас будут пихать чаще, чем мы в них :) В любом случае нужно уметь анализировать это по базе и выстроить набор инструментов для анализа.
Я как раз прикупил чуть побольше майнинг и результаты запросов, которые я далее покажу получены на базе турниров big / bigger 22$. Общий объём базы 8 миллионов рук. т.е. если нам важны статистики и диапазоны, то у нас будет примерно 50м записей игрок-рука, что уже немало.
Pokertracker хранит данные как по отдельным картам хиро, так и в генерализованном формате (AKo, T8s и т.д.). Нас будет интересовать второй для анализа. Вообще анализировать можно разные ситуации, но общий принцип - те руки что мы селектим не должны иметь возможность быть сброшенными после действия. т.е. скажем 3бет-пуш подходит, а лимп-колл (не пуша) уже нет, т.к. далее у этой руки есть постфлоп и мы не можем выстроить диапазон по вскрытым картам. Также я не буду описывать каждую ситуацию, а возьму для примера обычный пуш с баттона. Если вы уже переварили предыдущие мои статьи с запросами, то наверное поняли, что первое что нужно сделать это научиться считать вручную через базу статистики, а потом их кастомизировать.
Для того чтобы заселектить диапазон пуша с баттона в 10ББ я делаю следущее (sql)
with pls as
(select id_player, count(*) as cnt
from tourney_hand_player_statistics s
group by id_player),
raw_query as
(select lhc.hole_cards, lhc.flg_h_suited, lhc.enum_pair_type, count(*) as n
from tourney_hand_player_statistics s
join tourney_blinds b on b.id_blinds = s.id_blinds
join lookup_hole_cards lhc on lhc.id_holecard = s.id_holecard and lhc.id_gametype = 1
join pls ps on ps.id_player = s.id_player
where s.flg_p_open_opp and s.flg_p_first_raise and s.id_holecard != 0 and position = 0 and cnt_players between 6 and 8 and
s.amt_p_raise_made >= s.amt_before*0.5 and
round(least(s.amt_p_effective_stack, s.amt_before) * 1.0 / b.amt_bb,1) between 9 and 11 and
--ps.cnt < 500
group by lhc.hole_cards, lhc.flg_h_suited, lhc.enum_pair_type),
qweights as
(select q.hole_cards, q.n,
case when q.enum_pair_type = '1' then 2 when q.enum_pair_type = 'N' and q.flg_h_suited then 3 else 1 end * q.n as weight from raw_query q),
max_weight as
(select max(weight) as w from qweights),
res as
(select q.hole_cards, round(q.weight * 100.0 / mw.w) as percent, q.n,
q.hole_cards || ':' || round(q.weight * 1.0 / mw.w,2) as pio_txt
from qweights q
cross join max_weight mw
order by 2 desc)
select STRING_AGG(cast(pio_txt as text),',') as pio_range from resв этом запросе встречается закомментированная строчка --ps.cnt < 500, её я использую дальше чтобы выделить из общей массы игроков, на которых мало статистики (предположительно слабых, как минимум не регов). Что ещё в этом запросе можно увидеть важного для понимания - важно нормализовать встречаемость рук. Если у нас в колоде каждой пары 6 штук, suited - 4, а offsuit - 12, то соответственно чтобы получить классический диапазон нужно домножить в первом случае на 2, во втором на 3, а с offsuit ничего не делать (множитель 1). А также нужно потом нормировать диапазон поделив на максимальный найденный вес.
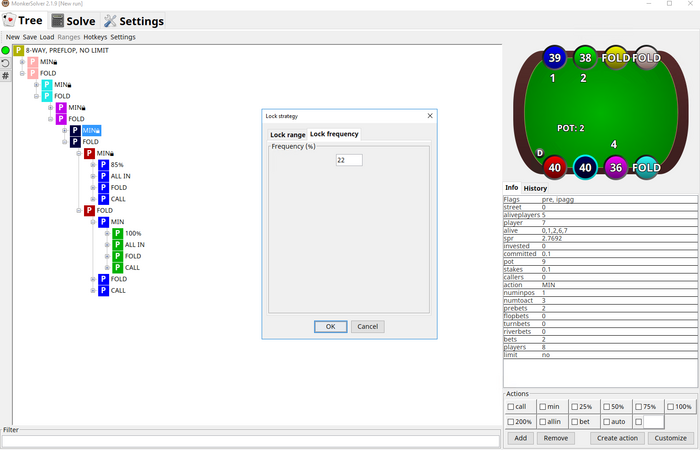
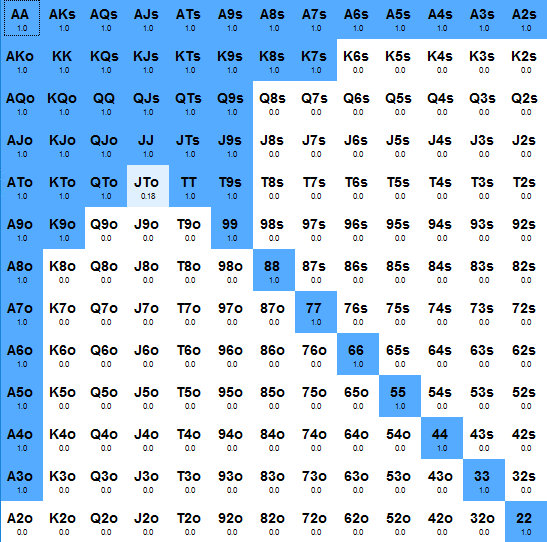
В итоге если скопировать результат запроса в pio, то диапазон получится вот такой

Можно видеть, что от GTO визарда он довольно сильно отличается
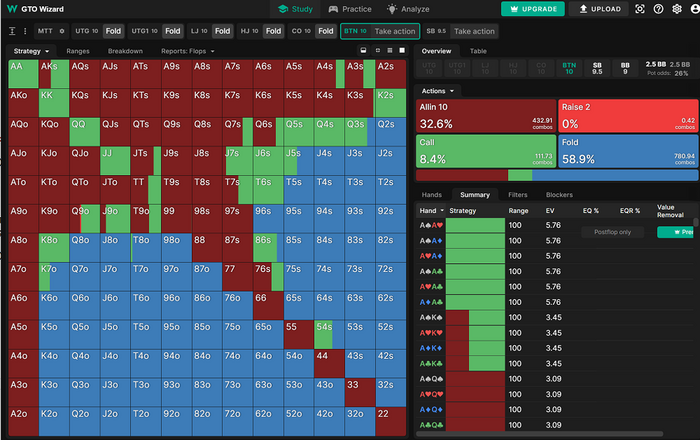
Но как увидим реакция на такой пуш с SB и BB отличается не сильно. Чтобы отсчитать эту реакцию нам сначала нужно преобразовать диапазон из формата piosolver в формат PPT, который понимает monkersolver. Сделать это можно с помощью например вот такого кода
class Program
{
private static HashSet<string> GetHandsFromGen(string genHand)
{
var list = new HashSet<string>();
var suits = new List<char> { 'c', 'd', 'h', 's' };
var pair = genHand.Length == 2;
var suited = genHand.EndsWith("s");
var leftCard = genHand.Substring(0, 1);
var rightCard = genHand.Substring(1, 1);
foreach (var s1 in suits)
{
foreach (var s2 in suits)
{
if (s1 == s2 && (pair || !suited) || s1 != s2 && suited)
continue;
var tmpList = new List<string>();
tmpList.Add($"{leftCard}{s1}");
tmpList.Add($"{rightCard}{s2}");
tmpList.Sort();
list.Add(string.Join("", tmpList));
}
}
return list;
}
static void Main(string[] args)
{
var pio_text = "сюда скопируйте ваш диапазон из sql";
var hands = pio_text.Split(new char[] { ',' }).ToList();
var res = new List<string>();
foreach (var h in hands)
{
var tokens = h.Split(new char[] { ':' }).ToList();
var strHands = GetHandsFromGen(tokens[0]);
var w = decimal.Parse(tokens[1]);
var str_w = Math.Round(w * 100).ToString();
foreach (var item in strHands)
{
res.Add($"{item}@{str_w}");
}
}
var result = string.Join(",", res);
}
}Ничего сложного, просто надо каждую генерализованную руку преобразовать в соответствующее количество рук с мастями.
Monkersolver даёт такой ответ на SB
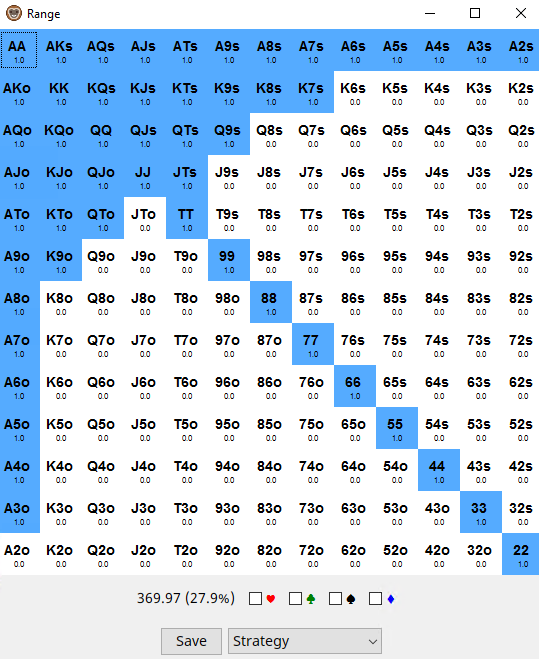
А такой на BB
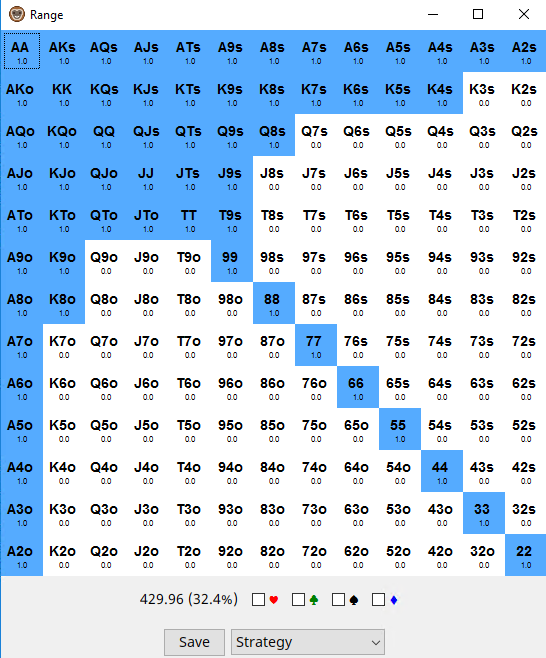
Если сравнить эти диапазоны с gtowizard, то мы можем видеть, что диапазоны приёма чуть-чуть шире, на SB добавились руки K9o, K7s, K8s, Q9s, JTo, а на BB теперь можно колить K8o, K4s, Q8s.
Это была отправная точка для творчества. Далее уже включается фантазия с вопросами "А что если?" например мне приходит в голову вопрос, а что если типизировать игроков и посчитать реакцию на регов и фишей раздельно. Типизация игроков это отдельная творческая задача, но есть и простые достаточно результативные методы. например количество игроков - если рук в майнинге мало, то это скорее всего рекреационный игрок. Насколько мало определить сходу сложно. я решил что 500 это достаточно мало чтобы посчитать игрока не регуляром. Но это пальцем в небо :) просто для того чтобы показать метод.
Я раскоментирую строчку ps.cnt < 500 в моём запросе и получаю такой диапазон пуша

который сильно меньше в процентном выражении, но слабее по составу рук. Т.е. если поле в целом пушит здесь 27-28%, то игроки рекреационные игроки делают так всего с 15% и можно видеть, что сильные руки пушат менее охотно. Как результат наша реакция на SB и BB должна быть такая
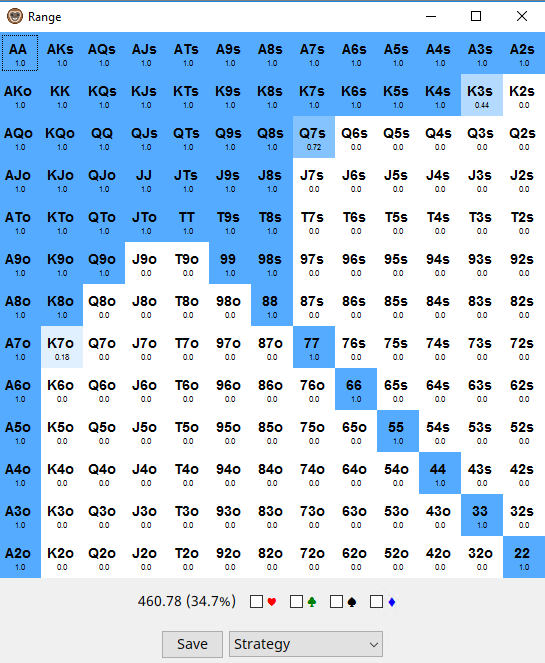
Что как видим ещё шире, чем я насчитал ранее для поля в целом.
Для тех кто захочет сам анализировать базы покертрекера из майнинга дам ещё один совет - учите базы данных :) К сожалению хотя база покертрекера и реально хороша, она всё же не предназначена для больших запросов по майнингу. Чтобы мои запросы отработали за разумное время пришлось добавить 3 индекса на основную таблицу с данными. делается вот так (sql)
CREATE INDEX "idx_thps_id_holecard" ON "public"."tourney_hand_player_statistics" (
"id_holecard"
);
CREATE INDEX "idx_thps_id_blinds" ON "public"."tourney_hand_player_statistics" (
"id_blinds"
);
CREATE INDEX "idx_thps_player_id" ON "public"."tourney_hand_player_statistics" (
"id_player"
);Но в целом если у вас пробел по базам данных, но вы уже освоили базовые инструменты, в которых можете написать запрос и построить план выполнения, то можно всегда скормить эти две вещи в chatGPT и получить советы по оптимизации. Если база будет не 8М рук, а например 80, то добавлением всего 3х индексов здесь не отделаться. А также для эффективной работы стоит подыскать что-то более удобное, чем инструменты идущие стандартно вместе с postgres. Рекомендую navicat, она топ.
И да, тем кто меня читает - если вы будете комментировать мои статьи или писать в личку что бы вы хотели видеть, то я смогу быть чуть более полезным для вас. Могу улучшить подачу материала и попробовать научить чему-то полезному и реально работающему. Возможно стоит уже переключиться с МТТ на что-то другое?
-

А вот вопрос, ты брал ГТО Визард ЧИП ЕВ модель?
Там есть варианты ICM пуша, они более узкие, возможно стоит с ним сравнивать
-
SnowBeaver, интересно как реги реагируют именно на Лимп от регов в примерно этих стеках. очевидно что в пушах не так много эксплоита как в лимпах тех же.
регов можно отсечь по той же стате лимпа, а Не только количеству рук
-
yanxi @ 22.07.23
А вот вопрос, ты брал ГТО Визард ЧИП ЕВ модель?
Там есть варианты ICM пуша, они более узкие, возможно стоит с ним сравнивать
у меня нет платной подписки на этот инструмент. Т.к. у меня нет никакого практического способа заработать на этих данных. Я описываю схему как в принципе можно работать с данными, а gto wizard просто доступный референс для сравнения. Любому кто хочет выжать из этих инструментов практическую ценность для себя придётся потрудиться. Если я поверх описания инструментов накину ICM, то статьи станут длиннее и сложнее. Как минимум придётся в запросах учитывать кто коротыш (хиро или пушер в хиро). А так да, в monkersolver тоже можно отсчитать с учётом ICM. Если есть понимание, что это нужно сделать, то надо брать и делать :)
-
sqwadr @ 22.07.23
SnowBeaver, интересно как реги реагируют именно на Лимп от регов в примерно этих стеках. очевидно что в пушах не так много эксплоита как в лимпах тех же.
регов можно отсечь по той же стате лимпа, а Не только количеству рук
то что я наблюдаю по данным:
- реги вообще почти не лимпят, делают это даже меньше рекреационных игроков
- по ГТО лимпа дофига.
- вообще всё поле недостаточно сильно изолейтит лимпы, что делает оптимальный лимп в солвере ещё чаще
- адекватно проанализировать как изолейтит рег другого рега сложно, т.к. случай редкий.
эксплойта вагон :) но надо учиться играть постфлоп с широким лимпом и недорейзом от опов. Если потратить на это дополнительное время, то можно очень неплохо усилиться. Пока я знаю, что лимп в стратегии есть только у очень топовых регов мтт. их мало. Если бы я сам сейчас играл и шёл вверх по лимитам, то я бы сделал упор на изучение игры от лимпа.
ну и я конечно же только простой пример отсечки по количеству рук привёл. можно и статы проанализировать и expected chip won. Выделение типов игроков это отдельная творческая задача, которую каждый решает под свои нужды.
-

SnowBeaver, Не думал в школу какую нить пойти тренером подрабатывать там и разбирать тенденции поля?
Пишешь хорошо, и с кодами даже. Но для рядового рега-покериста = это несет мало инфы, твои знания будут полезны тренерам, и школам, которые дадут твоим знаниям и возможностям расскрыться полностью. Покеристу лень бывает 1-2 стата в ХУД добавить, не говоря уже дабы учить sql
-

SnowBeaver @ 21.07.23
Если у нас в колоде каждой пары 6 штук, suited - 4, а offsuit - 12, то соответственно чтобы получить классический диапазон нужно домножить в первом случае на 2, во втором на 3, а с offsuit ничего не делать (множитель 1). А также нужно потом нормировать диапазон поделив на максимальный найденный вес.
Для академической точности неплохо бы нормировать против ренжа закрытия ещё, а так красивая работа, респект
Например мы закрыли на АА, в этом случае соперник пушит меньше Ах , потому что у нас АА, и Ах меньше в колоде, твой метод нормирования даст небольшую ошибку
В идеале конечно же учесть ещё ренжи фолда до батона) но это уже совсем другая история...
-
parenel @ 22.07.23
SnowBeaver, Не думал в школу какую нить пойти тренером подрабатывать там и разбирать тенденции поля?
Пишешь хорошо, и с кодами даже. Но для рядового рега-покериста = это несет мало инфы, твои знания будут полезны тренерам, и школам, которые дадут твоим знаниям и возможностям расскрыться полностью. Покеристу лень бывает 1-2 стата в ХУД добавить, не говоря уже дабы учить sql
Поэтому я и открыл блог в рубрике околопокерных тем :) Я давно работаю со школами, иногда с несколькими одновременно. И делаю там всякое... А бложек решил создать как личный марафон. Хочу проверить смогу ли раз в неделю выпускать по статье продолжительное время. Ну год например. Тут меня никто не ограничивает выбором темы, т.е. в теории меня хватит писать так много лет. А на джипси на самом деле легко наберётся 50 человек, кто шарит на моём уровне. Просто пока они меня не читают. Потихоньку обрету свою аудиторию. Буду миксовать технические статьи с более-менее философскими.
ну и опять же, если человек готов напрягаться и делать вещи выше своей головы, то со временем они станут для него привычными и он будет зарабатывать хорошие деньги на них. Т.е. сесть и изучить то что я написал для человека с мозгами не должно быть слишком сложно. Современный профессиональный покер вещь сложная, я показываю один из его аспектов. Ленивые покеристы просто не моя аудитория, пусть воды смотрят :)
-
c00l0ne @ 22.07.23
Для академической точности неплохо бы нормировать против ренжа закрытия ещё, а так красивая работа, респект
Например мы закрыли на АА, в этом случае соперник пушит меньше Ах , потому что у нас АА, и Ах меньше в колоде, твой метод нормирования даст небольшую ошибку
В идеале конечно же учесть ещё ренжи фолда до батона) но это уже совсем другая история...
ну, делается не так чтобы сложно. у меня есть серия коротких статей по card removal https://www.buymeacoffee.com/pokerrabbithole/posts . Я хотел сначала там всё выкладывать и на английском. потом понял, что площадка дико неудобная, и я не смогу держать темп по статье в неделю если мне придётся на хорошем английском их писать. т.е. у меня есть код для вычитания диапазонов. Да и солверы есть более корректные, чем monkersolver. типа можно было бы на HRC считать, и там оно бы ещё и ранауты учло в эксплойте. Но нафига тут кому-то такой лонгрид? Те кто такое готов прочитать, могут и сами всё это проделать :)
Я здесь больше описываю базовый ликбез по применению программирования в покере. Могу сильно переключить передачу и начать про уже серьёзный ML. Типа как например по майнингу получить диапазоны рук, которые не дошли до вскрытия и чтобы это было обосновано. Но мне нужна для этого своя core аудитория, которая может это прочитать и переварить.
-
-
SnowBeaver @ 21.07.23
В итоге если скопировать результат запроса в pio, то диапазон получится вот такой
у меня такой результат получился (40 млн рук где то )

ждем информацию как кластеризовать игроков и нейросетевой анализ )

а по этим расчетам что можно сказать , недопушивает поле низы относительно гто и закрывать надо наоборот чуть чуть уже А2о фолд и к8с фолд и ДТо фолд, но двойки колл относительно гто :

ГТО SB :

расчет в HRC :
SB:

BB без изменений, закрывать надо по гто, *упд не заметил к5с надо фолд жать :

 Сообщение отредактировал c00l0ne - 24.7.2023, 8:32
Сообщение отредактировал c00l0ne - 24.7.2023, 8:32 -
могу добавить что 3-5бб/100 поляна не добирает относительно нэша ...
казалось бы пуш в 10 бб на батоне что может быть проще ...
-
c00l0ne @ 24.07.23
у меня такой результат получился (40 млн рук где то )
О, класс, какого рума майнинг? Какие турики? 40м именно handhistory? Можно обменяться, я как раз закончил импортировать big / bigger. купил с таким называнием всё что нашёл по лимитам 22, 27, 33, 44, 55, 82, 109, 215$. Получилось около 30М раздач.
Это абсолютно нормально получать различающиеся результаты. я пока что очень поверхностно анализировал и то что ранее показывал было по базе 22$. Если кому-то нужно руководство к действию и качественный чарт, то это отдельная работа на много часов. Вообще можно продумать план и сделать что-то вроде "MTT blueprint", найти грамотного продавца и попытаться на этом заработать. В целом я не знаю есть ли такое вообще в публичном доступе хотябы и за деньги... Ну типа чтобы люди хотябы обоснованный префлоп выстроили на основе реальных данных. То что модно сейчас это людям продавать "GTO". На этом уже много хорошо работающих бизнесов, а на анализе данных пока ноль. Видимо потому что это стерильная тема, к ней невозможно доебаться, что это читерство :) Но я например знаю крутых регов, которые даже с омахой справляются благодаря своему анализу. Собственно все крутые как раз не ограничивают себя в технических средствах.
И да, HRC имхо лучше подходит для отсчёта префлопа, чем манкер. Просто потому что там MCCFR (Monte carlo CFR) и оно учитывает card removal просто на уровне самой модели без костылей. Да и экспорт из этой тулзы божественный. Json на выходе и не надо разбираться что значат внутренние коды манкерсолвера применительно к дереву. Почему gtowizard используют манкер как основу, а HRC только для глубоких стеков я не знаю, наверное должна быть какая-то причина. Возможно просто так сложилось.
А по поводу нейросетей. У меня вызывает саркастическую улыбку каждый раз, когда я что-то про это слышу или читаю. Наверное потому что я уже старпёр и мне не понять зумеров ну никак :) Могу только в плане аналогии привести - кто давно живёт помнит тему про стволовые клетки, что типа все болезни будут ими лечить, что любой орган человеку починят или заменят, что можно будет вырастить себе новую печень из пробирки. В итоге некоторые люди из р.ф. элиты, кто этим бахались (ну реально люди себе покупали за охулиарды серию уколов стволовыми клетками) закончили онкологией в относительно нестаром возрасте. При чём здесь нейросети? ну типа у каждого поколения есть своя дичь в которую оно неудержимо верит. В покере мало кто применяет нейросети, да и вообще почти нигде они массово не применяются. Есть свой спектр задач, где они лучше подходят, чем какой-нибудь катбуст или деревья решений. Например в распознавании фото, но использовать их на любых данных и причём как основной инструмент это лютейшая глупость от незнания. В итоге это ещё и скучно рассказывать про ML может быть, т.к. люди ждут техночудес, а им опять рассказывают про линейную алгебру и теорему байеса.
- Вы сможете оставлять комментарии, оценивать посты, участвовать в дискуссиях и повышать свой уровень игры.
- Если вы предпочитаете четырехцветную колоду и хотите отключить анимацию аватаров, эти возможности будут в настройках профиля.
- Вам станут доступны закладки, бекинг и другие удобные инструменты сайта.
- На каждой странице будет видно, где появились новые посты и комментарии.
- Если вы зарегистрированы в покер-румах через GipsyTeam, вы получите статистику рейка, бонусные очки для покупок в магазине, эксклюзивные акции и расширенную поддержку.
он так покажет потому что профит в МТТ основной тоже делается в ХА :) Да, все деньги всех игроков за какое-то килополе скопились в руках двух игроков и какой-нибудь неправильный контбет может стоить тысячи баксов притом что байин был двадцатка. Но изучать ХА игру на примере МТТ нет никакого смысла, поэтому я потом отсекаю эти ситуации и смотрю остальное