
Дневник c00l0ne
-
ПопулярностьТоп-63
-
Постов11,030
-
Просмотров987,061
-
Подписок88
-
Карма автора+891
-
Заходят три математика в бар. Бармен спрашивает: - Все будут пиво? Первый математик:&nbs
+25
-
c00l0ne, я ещё никогда так не впахивал как до развития claude code :) Появление LLM
+24
-
Shtirlitz, fastdecision, Feliz, вы не представляете как вам повезло что вы это только здесь читаете,
+20
-
+17
-
Мне однажды сказали примерно следующее: -Не так страшно ,когда человек творит откровенную чушь , куд
+17
-
 Сообщение отредактировал c00l0ne - 16.4.2026, 13:32
Сообщение отредактировал c00l0ne - 16.4.2026, 13:32 -
c00l0ne, я просто не отношу себя к верующим :) если что-то работает, использую. Я пришёл к выводу, что нужны жёсткие практики по сдерживанию использования если надо контроллировать результат разработки (не прототипы, продуктовая). Мой бывший коллега написал, который главный по технической части в одной продвинутой конторе. Я сейчас на эти практики перехожу
AI-Assisted Software Engineering. A Field Manual.pdf (2.1 мегабайт)
Самая зрелая практика это spec-driven подход, который требует определённой дисциплины. по нему уже есть курсы
Т.е. тем кто хочет закрепиться в программировании на AI сейчас нужно в этом направлении своё обучение строить. Вайбкодинг всё. Десятки тысяч инженеров поняли, что само оно задачи не решает, нужен очень структурированный подход чтобы бустить разработку.
И вот типа в программировании оно уже отлежалось 2 года и лучшие умы изучили практики чтобы дать хоть какой-то вразумительный подход с чем мы имеем дело. В математике сильно меньше людей, формализация её работает крайне слабо во многих областях. Иногда люди свой новый формальный язык создают чтобы что-то сделать. Как правило те, кто защищает докторские не могут себе комиссию собрать годами, т.к. их тему понимают в мире 10 человек. Да и на обычном человеческом уровне обычных практиков AI не тянет в задачах, где у неё просто нет точной инфы "как правильно".
Сейчас 99% контента это AI-слоп. в том числе и по теме науки. В публикации попадает изрядное количество бреда от AI в том числе. Если что-то удаётся в практику утащить и это реально работает, то это хорошо. У меня пока ситуация, что задачки из практического ML приходится делать много итераций шаг за шагом понимая какие методы "подходят". Я уже месяц на ней. Не непрерывно выполняю, итерациями. Но всё же это не серьёзная академическая математика, а прикладные модели, которые AI понимает слабо. Так что для меня то что копипастишь это из категории "Английские учёные доказали" :) типа смысл читать AI-сгенерированный текст, если он непосредственно к работе не относится? С точки зрения науки там бред почти наверняка. Из категории как кто-то с помощью chatgpt излечил собаку от рака... это уже становится похожим на религиозный фанатизм.
Нет никакого смысла решать уже решённые задачи или какие-то головоломки. Ещё можно понять зачем это делать самому - типа мозг потренить. Но с помощью AI зачем решать эти ханойские башни если профита ноль?
-
SnowBeaver, так и знал сюда этот курс притянешь ) ну бро тебя отблагодарит)
понятно что продукт дев это другое ... где ошибка стоит минус все... но на продукт деве ты в плюсе оказываешься ...
а от решения задач эрдеша толку маловато в этом мире...
SnowBeaver @ 16.04.26
помощью chatgpt излечил собаку от рака
ну не только собаку, уже и сооснователь github излечился от рака собирая вакцину себе с помощью суперкоманды биологов и иишки :
https://habr.com/ru/news/1016590/
на деле оказалось не сложно , процесс дорогой и трудный сам по себе чтобы делать каждому человеку
лет через 10 будет в паблике
SnowBeaver @ 16.04.26
AI зачем решать эти ханойские башни если профита
это тест технологический... на чем то надо технологию обучения тестировать ... берут простые игры ...
а выхлоп ну 1% энергии на обучения вместо 100% помоему очевиден...
если раньше тебе нужно было 100 видеокарт 3090 geforce стоимость 5млн руб
то теперь ты можешь на одной это сделать ...
-
c00l0ne, от любого выхлопа AI ровно 0% толка если человек не может понять решение. мне вот интересна математика типа мой уровень (понятно сразу) и мой уровень + 1, которую я могу проанализировать. Математику уровня типа +10 от моего я не способен понять никогда (или почти). И поэтому не могу извлечь пользы из AI. Никакой.
Если на что-то трачу время, это что-то должно либо конвертироваться в бабло, либо в улучшение моих скилов \ компетенций. Если ни того ни другого не происходит, то я потратил время на суходрочку. Стараюсь этого избегать. Сейчас нагрузка информационная на мозг и так избыточна.
если AI галлюцинирует на простых задачах, которые мы можем понять, то какой смысл ему доверять на тех задачах, на которых не можем? Нет альтернативной валидации - нет результата.
-
SnowBeaver, истина конечно, но время все равно идет ) хоть как живи )
наша задача "остановить время"... )
ладно ушел работать а то тут вечно можно лить воду ... из одного ведра большого и узкого в другое низкое и широкое ... и обратно...
-
-
Разберем попозже
интуитивно я думаю будет очень похожая технология как в солверах от Олега Остроумова
дал приказ агентам разобраться ) ждем)
задача Эрдёша №1196
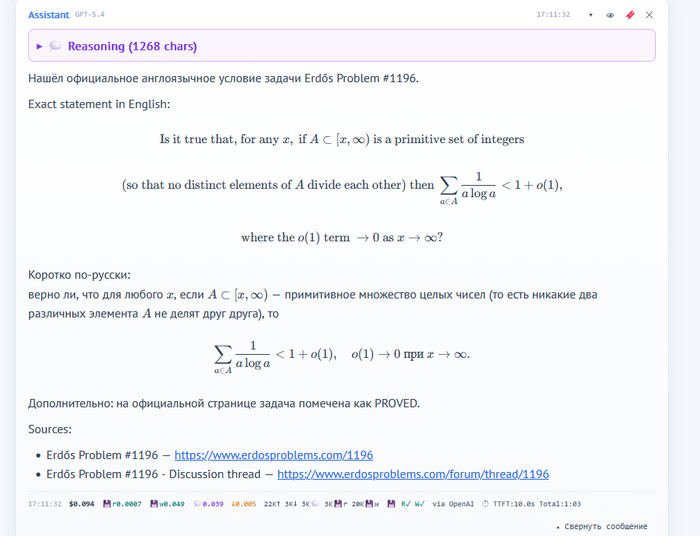
простым языком:

кратко это зависимость целого множества чисел целых по делимости
"Задача спрашивает:
если брать только большие числа и запрещать ситуации типа “одно число делит другое”, то можно ли доказать, что суммарный вес такого набора почти всегда ограничен единицей?
"
короче голову не грейте, ждем решение
-
c00l0ne @ 16.04.26
если не секрет можешь подробнее, может подскажу что -нибудь
задача сугубо практическая
У нас есть майнинг (например холдема 6max)
нужно построить модель предикторов пре и постфлоп такую чтобы ей можно было моделировать игру. Типа скажем делать запрос как поле ставит контбет на каком-то флопе. Или какой диапазон был у игрока в какой-то момент. Первая упрощённая итерация без разбиения на типы игроков. Просто интересует "поле". Вторая задача уже со звёздочкой это дать оценку сколько рук нужно для какого-то предиктора. Типа насколько точна наша оценка контбета на флопе у подобных ситуаций.
Отправная точка работа 2010 года на которой выросли все ботнеты современные. Тот же популярный NZT работает по данному алгоритму. Собственно бот = задача по моделированию + задача по эксплуатации. Вторая мне нахер не нужна с этими RTA возиться, а вот первая для MDA очень бы помогла.
Tom_van_der_Kleij_Thesis.pdf (5.1 мегабайт)
У меня раньше был совместный проект по анализу, который решал качественно данную задачу, т.е. я уже один раз добивался успеха в этом анализе и у меня есть опыт. Теперь хочу свой проект с нуля создать использовав общие принципы заложенные статьёй и современные технологии LLM. Fitfunction здесь это частотные статистики и то что показано на вскрытии. Т.е. если я скажем какой-то второй баррель посмотрю в майнинге по спаренным бордам, то модель тоже долна повторить процент рейза. Ну, опять же, посроение систем метрик тоже часть модели, которую надо построить.
на выходе у тебя условный чёрный ящик, ты ему кормишь майнинг, оно обучается. потом кидаешь любую раздачу без вскрытия карт и оно тебе пишет диапазон игрока по каждому решению. Далее используешь это для построения эксплуатирующих стратегий. Как допишу полностью работающий прототип, то займусь оптимизацией по цене\скорости работы.
если ты это скормишь любой LLM без статьи Вандеркляя, то будет полный бред. Если со статьёй, то частичный :) Но в любом случае ни один LLM агент не способен построить такую ML модель на сегодня. Но будет старательно делать вид.
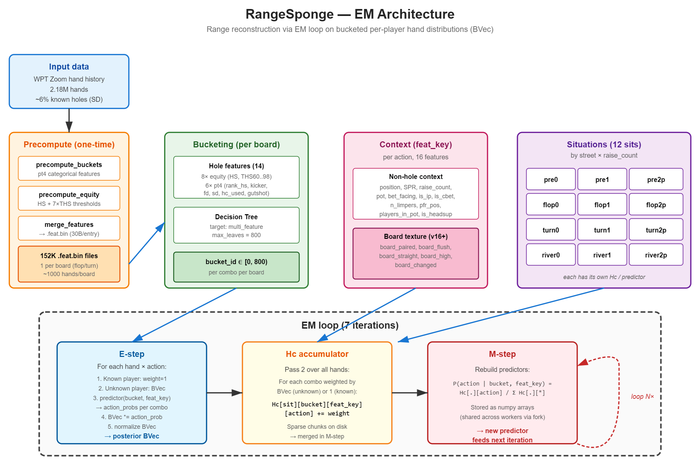
Я в принципе уже написал систему, сейчас борюсь за точность и ставлю эксперименты на серверах. Пока архитектура выглядит вот так. Если что, то до неё я шёл месяц так что будет не вполне честно её сразу скормить LLM если надо показать чисто, что LLM могёт. Но даже если скормить, то LLM просто начнёт ошибаться в терминах, которые человек не поймёт, если он сам не дошёл до этой архитектуры.
-
SnowBeaver @ 16.04.26
один LLM агент не способен построить такую ML модель на сегодня. Но будет старательно делать вид
ахахаха
ну задача хорошая, будут идеи напишу... что в качестве ML модели ? сколько параметров? какая версия трансформера ?
все больше ничем не могу подсказать , это создание на самом деле эксплойт стратегии для бота, ты занимаешься этим...
-
c00l0ne @ 16.04.26
ахахаха
ну задача хорошая, будут идеи напишу... что в качестве ML модели ? сколько параметров? какая версия трансформера ?
Ну ты решение спросил уже :) Это не в полне честный подход. но даже если я тебе всё подробно опишу, что у меня сейчас в текущей итерации вертится это всё равно не поможет LLM написать разумную модель, которая решит задачу.
1. трансформеров я не использую (ты можешь если считаешь нужным, я считаю overkill)
2. Я ушёл от нейросетей в сторону катбуста, на моих данных он работает лучше
3. Параметры частично на скрине. Но я разные пробую и гоняю в пакетном режиме на серверах. Если бы LLM был всевидящий и всезнающий, то он бы сразу структуру параметров бы выдал. Но увы, он не таков.
-
c00l0ne @ 16.04.26
все больше ничем не могу подсказать , это создание на самом деле эксплойт стратегии для бота, ты занимаешься этим...
любой метод работает в зависимости от того где ты это применяешь. я занимаюсь исследованием данных и MDA. Не RTA. По факту любой исследователь данных в покере будет неизбежно знаком со всеми статьями реализующими ботов. Это тупо смежные отрасли.
-
-
c00l0ne @ 16.04.26
знаешь лучше оверкилл чем недобить )
задача инженерная. сделать так чтобы работало на разумных ресурсах, а не кластере MIT. С задачей разделения качественных признаков катбуст работает быстрее и чаще всего лучше чем нейросети. В пределе на бесконечных данных все модели дают 100% точность. Но на реальных задачах поиск компромисса всегда на совести исследующего. Но я бы так сказал - если для задачи нужны дорогие видеокарты типа H100 и не хватает стандартного контабовского сервака, то задача не решена.
трансформеры тут не нужны как минимум потому что нет последовательностей. Типа мы не анализируем текст, речь и тому подобное. У нас табличные данные, которые нужно аппроксимировать. Те кто шарят в ML (даже поверхностно) никогда даже не будут пробовать здесь трансформеры. Но LLM может :) они любят.
-
SnowBeaver @ 16.04.26
разумных ресурсах
100 млн параметров хватит ... можно начать с 10 млн ...
пс про объемы мда думаю лучше не спрашивать, они у тебя ВСЕ)
чиво ? для работы ? видеокарты типа H100
да ты чего это для обучения нужно ...
а для работы интерференса 100 млн параметров хватит 3090 видяхи и сервака 64+ ядра
все возвращаемся к решению Эрдёша ) пердеша)
SnowBeaver @ 16.04.26
пробовать здесь трансформеры
ну такое я все сказал ... дальше тебе решать )
Сообщение отредактировал c00l0ne - 16.4.2026, 14:52 -
c00l0ne, я бы мог деньги на спор ставить, что ты таким походом не решишь :) причём любые. Но это будет не этично с моей стороны. Тут дело не в количестве параметров, а в архитектуре и понимании процессов. Собственно в математике. LLM не думает, и эту задачу не решит. Типового решения в сети никто никогда не выкладывал для подобной задачи. Железному болвану будет не за что зацепиться даже если ты скормишь ему всё что я написал (а я по сути описал уже решение). Чтобы обсуждать параметры количественно надо выбрать модель в которой мы считаем. Я лично не считал у этой модели количество параметров, т.к. это не влияет на процесс никак.
Инженеру со знанием покера достаточно статьи отправной и времени. Ну и з.п. хотябы 100 в час на месяца 3-4.
-
SnowBeaver, ты заблуждаешься , LLM в паре с человеком сделают такой проект за пол года ... если не раньше, если есть ресурсы для тренировки , майнинг уже весь обсчитанный до мелочей ... то это вообще 1-2 месяца работы ...
про трансформеры лучше ничего не пиши ) это не так работает как ты думаешь)
трансформеры обладают уникальными возможностями фокусироваться на главном и отбрасывать маловажное ... это так называемые головы внимания... и не важно это ТЕКСТОВЫЕ ТОКЕНЫ или ЦИФЕРЫ СТАТИСТИКА или КАРТЫ ... все это в цифры преобразуется , потом ембеддинги присваиваются образуется вектор цифорок и потом уже трансформер делает грязь с этими векторами , а потом в MLP прогоняет жестко
-
c00l0ne, если ты что-то сгенеришь в практическом плане для меня ценное по этой задаче, то я за это даже заплачу :) пока что у меня этот подход не оправдался. Решение через трансформеры это экстенсивный подход с затратой ресурсов больше чем требует задача + без гарантированных шансов на решение.
Оценка времени здесь приблизительная. Я помню за сколько прошлая команда пришла к результату. И примерно понимаю что я сейчас на полпути. Но это не точно :)
У меня есть объективный способ тестировать результат прогоняя по данным, где я знаю карты hero на большой базе.
То что трансформеры это типа самый сложный компонент, который можно применить в AI сейчас не означает автоматом, что его надо применять на всех классах задач. Опишу почему нельзя это тут эффективно применить (ну как я понимаю)
- Трансформеры нужны для equence-to-sequence задач, а у нас тут conditional density, т.е. задача аппроксимации
- Для трансформера нужно как можно больше размеченных данных, а у нас до шоудауна доходит только ~6% рук и надо извлекать знания из статистик. Всё равно нужна архитектура описывающая данные.
- Мы уже в значительной степени знаем покер и структуры. Типа симметрия рук например AsKs и KdAd на префлопе одна хуйня для нас, а трансформер будет учиться с нуля.
- Интерпретируемость результата будет нулевая. Модель чистый чёрный ящик. В своей же модели я могу частично отвечать на вопросы "почему" на основе деревьев решений.
- С точки зрения количества параметров, у меня реализована non-parametric estimator, т.е. если будет больше других отличающихся данных в выборке, то она выростет, сейчас же там 109м параметров которые sparse (разреженные). И мой метод будет работать при любом количестве входных данных без архитектурных изменений и количество параметров добавляется в процессе пополнения новыми данными. В трансформере тебе придётся задавать архитектуру и потом её переобучать если не хватило. Скорее всего тебе придётся использовать х10 если не х100 в параметрах трансформера чтобы получить результат как у меня сейчас на 109м (который ещё очень кривой).
но я не могу сказать, что в теории тут нельзя применить трансформеры. Очень даже можно когда базовая модель хорошо заработает
- можно сделать context-aware бакеты, и я об этом думал. Сейчас у меня бакеты строятся независимо на каждой точке в предикторе, за счёт этого теряется часть инфы. История кодируется примитивно. А это sequence и тут можно добавить трансформеры как дополнительную оптимизацию. т.е. я скажем последовательность BB call - BTN 3bet - BB call - flop свожу к информации (sit=flop0, raise_count=1, pfr_pos=BTN). Трансформер мог бы использовать всю последовательность с большей детализацией. Это интересное улучшение могло бы быть. Но это уже вишенка на торте. Надо сначала испечь остальное.
Сообщение отредактировал SnowBeaver - 16.4.2026, 15:32 -
SnowBeaver, ну такое обсуждать это бред , это плодить ботоводов ... будут мысли я напишу в лс...
-
траснформер очень внимательный : я реально отвлекся и не тот файл ему дал скушать, не ту версию файла, честно я вообще другими делами занимаюсь)
ок оно заметило это +реп
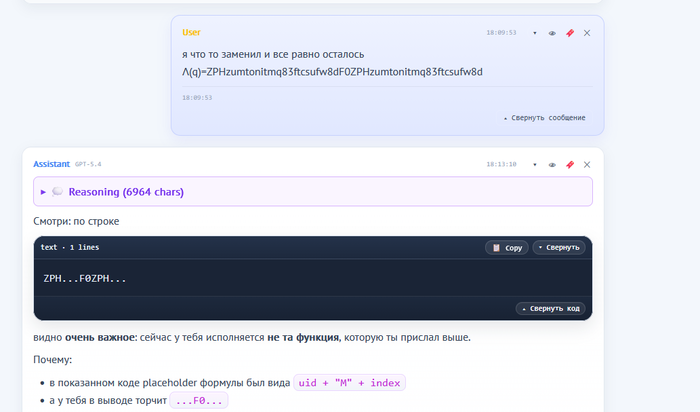
вывод формул поправлю посмотрим решение, что там наворотил gpt-5.4 pro
-
мда тут сложновато :
кому интересно решение gpt-5.4 pro задачи



gpt-5.4 pro это сила
попроще если разбираться


жаль дорогая силушка
- Вы сможете оставлять комментарии, оценивать посты, участвовать в дискуссиях и повышать свой уровень игры.
- Если вы предпочитаете четырехцветную колоду и хотите отключить анимацию аватаров, эти возможности будут в настройках профиля.
- Вам станут доступны закладки, бекинг и другие удобные инструменты сайта.
- На каждой странице будет видно, где появились новые посты и комментарии.
- Если вы зарегистрированы в покер-румах через GipsyTeam, вы получите статистику рейка, бонусные очки для покупок в магазине, эксклюзивные акции и расширенную поддержку.
вот это кстати невероятный прорыв:
хочу попробовать обучить такую систему
как ручки дойдут