



Если я верно понял: симуляции независимы, и могут обсчитываться параллельно.
Возможно даже по несколько на одном ядре. Даже не знаю, что там сейчас. https://ru.wikipedia.org/wiki/SIMD
Статистика
Всего постов
11887
3,560,622 просмотров
Новых постов
+2
3 в день
Лучшие посты автора
Лучшие посты читателей
Самые активные читатели
| Julio | 679 |
| Soul | 285 |
| iYeti | 179 |
| barbeysize | 144 |
| kain1987 | 132 |
-

-
Мы сейчас как раз заняты распараллериванием этих симмуляций. Да симмуляции независимы и можно 1 000 000 симмуляций разбить на 10 блоков по 100 000 и запустить каждый блок в отдельном потоке.Но даже 100 000 симмуляций выполняются меньше чем за одну секунду, а время создания потока не нулевое и поэтому выгода от этого не такая, как бы хотелось. Но , повторю, мы как раз работаем в этом направлении.
-

Хорошая новость. Наш разраб, который отвечает за техчасть, смог таки обойти проблему с последовательными вычислениями.
Осторожно заявляю, что проблема многопоточности решена. Всем, кто накидывал рекомендации, спасибо.
-
Вообще, судя по коду программы, у вас слишком много допущений. Особенно существенные, на мой взгляд эти:
1. Если ProShares сбегает с деньгами (шанс 1/50000), то в следующей итерации мы опять закупаем несуществующий URPO.
2. Бесплатная ребалансировка портфеля ежедневно.
3. Мелочь, но бьёт по небольшим депозитам: нельзя выключить ровно 1 доллар с депозита (вывести), если требуется продавать ETF.
-
Marauder62, очень правильные замечания. Каждый из этих пунктов был исследован до начала написания кода. Отвечу по пунктам, почему сделано как сделано.
Цитата (Marauder62 @ 24.12.21)
1. Если ProShares сбегает с деньгами (шанс 1/50000), то в следующей итерации мы опять закупаем несуществующий URPO.
Буквально пару страниц назад Jak привел пример аналога Упро. Так что с этим разобрались.
Цитата (Marauder62 @ 24.12.21)
2. Бесплатная ребалансировка портфеля ежедневно.
Фактическая стоимость ребалансировки (под ключ, включая спред и брокерские комиссии) около $3 для портфеля в $1M. Решили не усложнять код этими копейками. Мы полагаем, что даже если заморочиться и вставить их в код, результат будет отличаться незначительно. У нас нет цели дать хирургическую точность. Достаточно, чтобы точность была достаточной.
Цитата (Marauder62 @ 24.12.21)
3. Мелочь, но бьёт по небольшим депозитам: нельзя выключить ровно 1 доллар с депозита (вывести), если требуется продавать ETF.
Да, вывести ровно 1 доллар нельзя (вернее, не нельзя, а нерентабельно). Но никто и будет выводить по 1 доллару. Бифф подразумевает реальную жизнь. А в ней вывод будет актуален тогда, когда инвестор выйдет на пенсию. Это означает, что у инвестора накопился крепкий шестизнак на счету. А лучше - семизнак. Суммы вывода там будут другие.
-

Цитата (LikeAA @ 23.12.21)
Скачал код, посмотрел. Я лет 20 не писал на Delphi, но, кажется, использование типа real для хранения вещественных чисел никогда не было хорошей идеей. Это же какой-то специфичный для Паскаля 6-байтный тип данных, и все вычисления в нём делаются программно. Желательно всё переделать под double (он 8-байтный) или single (аналог 4-байтного float для Паскаля, если такой точности будет достаточно).
Это нативные типы данных для сопроцессора и вычисления в них выполняются существенно быстрее.
Хотя может быть они real в какой-то версии Delphi уже переделали под double и я просто не в курсе.
Также можно подумать над тем, чтобы все вычисления сделать целочисленными, если это возможно, это будет ещё быстрее.
Привет, я участвую в проекте Бифф как программист и отвечаю пока за параллельность вычислений. Тоже начинал с Делфи 15 лет назад.
Интересные замечания, я заглянул в исходники Делфи 7, на которой идет разработка. Там Real это синоним Double: 8 bit exponent (bias 129), 39 bit fraction, 1 bit sign. Так что все должно быть ок.
Вчера я добавил многопоточность для вычисления таблицы. Каждый поток создается на моем процессоре за 1-5 мсек, особых потерь нет. Уже увидели ускорение примерно в 4 раза по сравнению с одним потоком, и еще есть пространтво для небольших оптимизаций. Для понимания насколько ускоряются вычисления нужно больше тестов, т.к. многое зависит от ядер процессора. Например у меня ядра по 2.8 гигагерц, но первое умеет разгонятся до 4 гигагерц. Плюс архитектура, кеш процессора и тд. В дальнейшем хочу перенести вычисления на амазоновский AWS и провести тесты в их облаке, там мощности на целый порядок выше.
-

По предложению Меркатора публикую копию сообщения из лички. Там, конечно, многое упрощённо, без технических деталей. Я знаю, что функции можно проверять юнит-тестами, а exe-файлы состоят не из исходного кода, а являются результатом работы компилятора/линкера/итп. Что корректность вычислений с плавающей точкой надо сравнивать не на полное совпадение, а с погрешностью.
Но основной посыл остаётся: чтобы упростить помощь со стороны, если она всё-таки понадобится, нагенерите публичных тестов и дайте возможность писать вычисление на любом языке программирования. Паскаль нормальный язык, но всё-таки совсем непопулярный.
Давай попробую через аналогию с более примитивной программой.
Допустим, ты написал программу, которая отвечает пользователю, плюсово ли колировать пуш на тёрне в омахе. Он вбивает в формочку диапазоны в покерджусовском синтаксисе (AssAK, 678+, и т.п.), накликивает карты флопа и тёрна, выбирает размеры банка и пуша - и программа даёт ответ в виде "Колл" или "Фолд".
Чтобы дать ответ, программе надо вычислить вероятности победы игроков. Для этого где-то в коде есть функция CalculateChances(yourRange, oppRange, board). Затем её ответ сравнивается с шансами банка и пользователю даётся ответ. Всё хорошо, программа корректная и невероятно полезная, только медленная. Тебе надо ускорить функцию CalculateChances.
Я прихожу к тебе и говорю: "Вот мой код функции, который считает то же самое в 10 раз быстрее!" Ты хочешь проверить, что код работает правильно, но как это сделать? Видимо, ты вставляешь мой код в свою программу, запускаешь две версии (с моим кодом и твоим), вводишь какие-то диапазоны, меняешь шансы банка и смотришь, в какой момент ответ Фолд поменяется на Колл. Это надо сделать много раз- в моём коде может быть баг, который проявляется только на части входных данных, поэтому надо проверить разные синтаксические конструкции, доски с разными комбинациями, и т.д.
Даже если у тебя уже подготовлен проверочный набор диапазонов, это приходится делать руками каждый раз, когда я приношу тебе очередную гениальную реализацию вычислений. И время приходится мерять самому с секундомером. Из-за того, что запустить функцию можно только через графическую оболочку, проверка превращается в ад.
А теперь представь, что вместо функции CalculateChances у тебя есть exe-файл, который можно просто запустить кнопкой Enter. В основе этого файла лежит та же функция CalculateChances, просто теперь он читает диапазоны и доску не из графической оболочки, а из файла input.txt и пишет вероятности победы игроков в файл output.txt . Тогда можно один раз написать 100 файлов input1.txt, input2.txt и т.д. с разными входами и положить их в папку input. Легко за полчаса (тут просто поверь) написать программу, которая в цикле будет запускать exe-файл с разными входами и генерить файлы output1.txt, и т.д., одновременно замеряя время работы. Ты запускаешь её одним нажатием кнопки и спокойно идёшь слушать свои любимые песни из дискографии Бритни Спирс. Так как все её песни - любимые, то как раз к последней программа закончит работать, и у тебя будет набор из 100 входных и правильных выходных данных.
Теперь я прихожу к тебе не с реализацией функции, а со своим exe-файлом. Ты, не снимая наушников, запускаешь в цикле уже мой exe-файл и продолжаешь слушать теперь уже Кристину Агилеру. Когда будут готовы мои 100 выходных файлов, сравнить их на одинаковость с твоими тоже тривиальная задача, которую легко автоматизировать.
При этом для exe-файла неважно на каком языке программирования он был написан, поэтому вместо Паскаля я могу писать его на своём любимом фортране.
Это всё не даёт ускорения программы само по себе. Но это облегчает разработку и проверку чужих результатов. Тебе не надо больше обсуждать, хорошую тебе предложили идею по ускорению или нет. Ты просто отвечаешь: "вот по этой ссылке есть проверочный набор данных. У кого будет готов exe-файл, который его корректно и быстро посчитает, с теми я готов продолжать разговор".
Так вот, у вас в коде тоже есть функция, которая рассчитывает таблицы и медленно работает. Я предлагаю вам на основе этой функции сделать exe-файл, которые принимает на вход файлы и пишет выход в другие файлы. И сделать с его помощью набор тестовых пар input-output. Часть тестов для короткого промежутка времени, чтобы быстро проверять корректность работы, а часть для длинного - чтобы измерять скорость. Это чисто организационный вопрос на самом деле.
-

Цитата (3voluti0n @ 24.12.21)
Интересные замечания, я заглянул в исходники Делфи 7, на которой идет разработка. Там Real это синоним Double: 8 bit exponent (bias 129), 39 bit fraction, 1 bit sign. Так что все должно быть ок.
Да я тоже посмотрел уже, сейчас real это тот же double, а для старого шестибайтного real они для совместимости сделали тип real48
-
Вы тратите слишком много ресурсов в пустую.
Моделировать что-то на д7 в 2021 году - это сопоставимо с использованием счёт вместо калькулятора.
Я уже скинул автору дневника скрипт, который делает такие же расчёты, но в разы быстрее.
Кроме этого, я попробовал посмотреть, как работает модель на тестовых данных. А именно когда VOO = UPRO и колебания в сутки могут быть или +1% или -1%.
К сожалению, математик во мне умер давно, поэтому интерпретировать данные я могу только прямолинейно: по условиям задача заведомо убыточная из-за сложного процента, доля UPRO значения не имеет (банкротство тоже сделал нулевым).
Собственно сводная таблица это и показала: серии независимо от пропорции VOO/URPO идентичные. Серий с прибылью меньше, чем серий с профитом, медиана ниже стартового капитала.
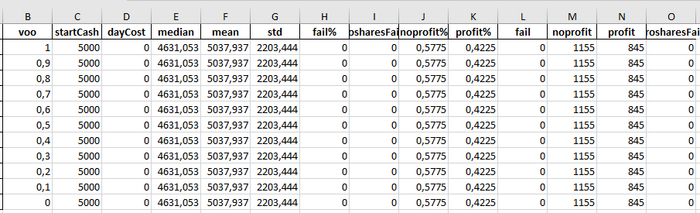
Кто умеет ещё в какой-то математике, прилагаю файл с сериями испытаний.
analytic_test.xlsx (614.8 килобайт)
-
Алгоритм Биффа. Часть 2.
Итак, по модели Биффа 1 возражений не последовало, считаем что она рабочая.
На этом этапе у нас есть процедура (кнопка Calculate EV), что по заданному соотношению VOO / UPRO, считает процент банкротств и среднее ЕВ стратегии.
Также есть процедура (в коде она называется FindBestRatio), которая используя функцию Calculate EV примерно 10 раз, находит оптимальное отношение VOO / UPRO с точностью до 0.1%, которое соответствует предельному риску, который мы задали. Это уже не мало - инвестор может каждый день за пару секунд узнать какого оптимального соотношения нужно придерживаться, учитывая, что и к-во дней изменилось и стартовый капитал изменился, и делать перерасчет этого соотношения хоть каждый день.
Но мы пошли дальше. Мы хотим сделать симуляцию этого реального инвестора и в этой симуляции перерасчитывать лучшее соотношение как можно чаще. В результате мы хотим узнать, как изменится наше средне-ожидаемое ЕВ и не изменится ли оптимальное стартовое соотношение VOO / UPRO из-за того что мы применяем более продвинутую стратегию.
Для начала прикинем примерное время расчетов. Процедура FindBestRatio, после распараллеливания может давать результат за 1 сек. Это очень хороший результат - за 1 сек рассчитывается 1-10 милльярдов элементарных дней и сильно ускорить ее уже вряд ли получится. Возьмем для примера симуляцию на 1000 дней и мы хотим делать перерасчет каждый 100-й день, т.е. таких перерасчетов будет 10 для каждой симуляции. Итак мы 10 раз запускаем процедуру FindBestRatio по 1 сек, итого 10 сек на одну симуляцию. Чтобы получить более-менее достоверные результаты нужно 100 000 симуляций - это займет 1 000 000 сек = более 11 дней. Это неприемлимое время - как видим задачу в лоб не решить за разумное время.
На этом месте хотелось бы остановиться и задать вопрос - что бы вы предложили делать дальше? Какой метод, алгоритм применить? Кто хочет подумать над этим, не читайте дальше.
Мы решили применить рассчитаные заранее таблицы. На первый взляд у этой задачи слишком много входных параметров и рассчитать таблицы для всех случаев - нереальная задача. Но более пристальный взгляд показал, что играет роль только отношение стартового капитала к расходу и 1000$ к 1$ даст такой же результат как 10 000$ к 10$. В дальнейшем мы нормализуем стартовый капитал делением на расход, а расход всегда принимаем равным 1$. Итого для заданного предельного риска, только два параметра изменяются - это текущий капитал и к-во дней, оставшихся до конечного срока. И для этих двух параметров мы можем заранее рассчитать оптимальное соотношение, применив процедуру FindBestRatio и занести результат в двухмерную таблицу.
Эта таблица будет иметь дискретное к-во ячеек - это означает, что если мы примем точность до 1%, то у нас будет 100 ячеек для диапазона 0%-100%, а если мы примем точность 0.1%, то у нас будет 1 000 ячеек для этого диапазона. К примеру, если в ячейке 500 (соответствует 50%) будет записано число 1000, а в ячейке 501 (соответствует 50.1%) будет записано число 1002, то это означает, что для всех капиталов в диапазоне от 1000$ до 1002$ лучшим соотношением VOO / UPRO будет 50.1%. Этой упрощенной модели вполне достаточно для наших рассчетов.
Предположим, что у нас уже есть заранее расчитанная таблица, как теперь будут выглядеть наши симуляции. Пример, мы рассчитываем для 1000 дней и хотим делать перерасчет каждые 100 дней.
В первый день мы выбираем какое-то наше соотношение (в дальнейшем мы его будем подбирать методом больше-меньше для нахождения оптимального). и следующие 100 дней мы придерживаемся этого соотношения. На 900-й день у нас образовался какой-то случайный капитал Х в результате 100 дней случайных изменений котировок. Теперь мы в таблице в строчке, которая соответствует 900-му дню, ищем ячейку в которой будет записано число Х (или немного больше) и по номеру этой ячейки узнаем искомый процент соотношения VOO / UPRO. Следующие 100 дней мы будем придерживаться этого табличного значения. На 800 дней у нас новое значение капитала У - и мы снова находим оптимальное соотношение из таблицы. И так до конца. Нахождение ячейки по заданному капиталу - это очень быстрая функция (максимум 10 итерраций двоичным поиском) и поэтому вся симуляция лишь немного дольше будет идти чем Бифф 1.
Тот пример, на который предварительно нужно было 12 дней, займет около часа на составление всей таблицы и меньше минуты, чтобы потом пользоваться таблицей в любой день и с любым стартовым капиталом.
Теперь мы стоим перед выбором - каким образом заполнять таблицу, как расчитывать оптимальное соотношение? На данном этапе у нас есть три версии и мы все еще в поиске лучшего варианта.
А что предложите вы?
-
Здесь уже прозвучал очень интересный вопрос, но ответа так и не последовало.
Возьмём простую задачу.
Надо 6 умножить на 4. Мы пишем супер функцию, которая за миллион итераций выдаёт какое-то значение. А как нам проверить, что это именно то значение, которое мы ищем?
В моём примере мы можем руками посчитать 6+6+6+6=24 или 24/4=6. В вашем варианте как это проверяется? Уже придуман тепличный вариант исходных данных, который можно просчитать на бумаге и сравнить с результатами программы?
Цитата (Galax @ 24.12.21)
находит оптимальное отношение VOO / UPRO с точностью до 0.1%
Это особенно хорошо выглядит на фоне ряда факторов, которые не учтены в алгоритме:
- фиксированная стоимость лота (нельзя купить VOO на $10);
- комиссии брокера за ребалансировку;
- возможная налоговая нагрузка за ежедневную ребалансировку;
-
Marauder62,
Я уже скинул автору дневника скрипт, который делает такие же расчёты, но в разы быстрее.
Такие же расчеты - это какие?
У нас на 1000 дней, 1 000 000 симуляций уходит 2-5 сек на домашних компах. Это 1 милльярд элементарных дней и в каждый день вызывается дважды функция рандома - очень медленная функция по-сравнению с обычными умножениями-сложениями.
Можешь ответить за сколько ты сделаешь такой тест и на каком языке программирования?
-
Не по оптимизации. Если весь риск разорения как-то распределяется по оставшимся отрезкам ребалансировок (инвестор-то пока не разорился раз пользуется), то на последнем отрезке Biff будет рисковать по полной. Если не так, то объясните как?
-
Цитата (Test2 @ 24.12.21)
Не по оптимизации. Если весь риск разорения как-то распределяется по оставшимся отрезкам ребалансировок (инвестор-то пока не разорился раз пользуется), то на последнем отрезке Biff будет рисковать по полной. Если не так, то объясните как?
Хороший вопрос. Обсудим его в третьей части, когда я буду объяснять три алгоритма создания таблицы.
-
-
-
Цитата (Marauder62 @ 24.12.21)
Это особенно хорошо выглядит на фоне ряда факторов, которые не учтены в алгоритме:
- фиксированная стоимость лота (нельзя купить VOO на $10);
- комиссии брокера за ребалансировку;
- возможная налоговая нагрузка за ежедневную ребалансировку;
Предлагаю сначала разобраться в вопросе, а уже потом писать здесь, а то все 3 пункта мимо. У большинства американских брокеров VOO можно купить хоть на 1 доллар, комиссий с 2021 года нет, налоги это личное дело каждого, не учитываются и никогда не будут.
Цитата (Marauder62 @ 24.12.21)
Вы тратите слишком много ресурсов в пустую.
Моделировать что-то на д7 в 2021 году - это сопоставимо с использованием счёт вместо калькулятора.
Я уже скинул автору дневника скрипт, который делает такие же расчёты, но в разы быстрее.
Полегче, а Меркатор то всех программистов уволит из-за тебя. Во первых, какие были входящие данные? Например для самых самых минимальных, ниже некуда на данный момент программа делает примерно 5000 циклов по 50 миллионов шагов за 5 минут. Сколько шагов делает твой скрипт? 50 тысяч?
-
Galax, у тебя какой камень это считает?
-
Цитата (Marauder62 @ 24.12.21)
Galax, у тебя какой камень это считает?
Т.е твое отставание в 1000 раз ты списываешь на слабость твоего процессора?
У меня стыдно признаться - i3 2900.
Кстати, за последний месяц я уже трижды слышал, что Python самый быстрый язык программирования. Да, он самый популярный сейчас, с этим никто не спорит. Но почему эти питонисты не удосужатся загуглить о его быстродействии? Они бы могли с удивлением обнаружить, что он раз в 10-15 медленнее С++, С#, Java. А Delphi хоть и не популярный сейчас, по быстродействию стоит рядом с C++.
-
Я больше не буду спорить в этой ветке.
1. Отмечу только, что я нигде не писал, какой язык самый быстрый.
2. Ориентировался на "возможную многопоточность вашего софта" (т.е. в момент написания моего скрипта такого быстродействия ещё не было)
Цитата (Galax @ 24.12.21)
это лучше чем 2 сек на 1 000 000 итераций?
Ну и последнее, 1 000 000 итераций по 1000 дней за 2 секунды - это очень крутой результат! Просто потому что это 10^9 расчетных дней, а топовый AMD Ryzen 9 5950X выдаёт только 98,336 MOps/Sec для Floating Point Math
2 человека читают эту тему (2 гостя):
Зачем регистрироваться на GipsyTeam?
- Вы сможете оставлять комментарии, оценивать посты, участвовать в дискуссиях и повышать свой уровень игры.
- Если вы предпочитаете четырехцветную колоду и хотите отключить анимацию аватаров, эти возможности будут в настройках профиля.
- Вам станут доступны закладки, бекинг и другие удобные инструменты сайта.
- На каждой странице будет видно, где появились новые посты и комментарии.
- Если вы зарегистрированы в покер-румах через GipsyTeam, вы получите статистику рейка, бонусные очки для покупок в магазине, эксклюзивные акции и расширенную поддержку.