Дневник c00l0ne
-
ПопулярностьТоп-128
-
Постов11,212
-
Просмотров1,006,931
-
Подписок89
-
Карма автора+1,025
-
Заходят три математика в бар. Бармен спрашивает: - Все будут пиво? Первый математик:&nbs
+25
-
c00l0ne, я ещё никогда так не впахивал как до развития claude code :) Появление LLM
+24
-
Shtirlitz, fastdecision, Feliz, вы не представляете как вам повезло что вы это только здесь читаете,
+20
-
+17
-
Мне однажды сказали примерно следующее: -Не так страшно ,когда человек творит откровенную чушь , куд
+17
-

-
-
на дорожке 5км прошел за 45 минут
императора одолел +43к
можно и почилить :
всем кто любит рдр2
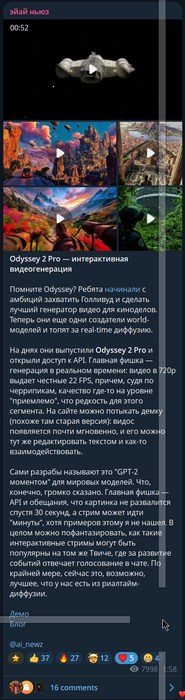
demo тут 10 минут дают https://experience.odyssey.ml/
попробую загрузить сюда видосы :
GTA 6 могут просто не успеть
ИИшкой быстрее сгенерируют
кто ничего не понял : в реальном времени каждый кадр генерируется в этом видео нейросетью, 22фпс всего , но нейронка рисует виртуальный мир по запросу текстовому
например запрос "играют в турнир последний император "
 Сообщение отредактировал c00l0ne - 26.1.2026, 2:20
Сообщение отредактировал c00l0ne - 26.1.2026, 2:20 -
битва моделей на олимпиадных задачах :
https://habr.com/ru/companies/bothub/articles/988856/

спойлер :

-
экспериментирую с gpt-5.2 Pro :
хочется свой браузер за 3 часа и за 2 бакса)


-
оч похоже на lifechanger :

читать лень поэтому отдадим эту роль ИИшке :


example :
example (poker):
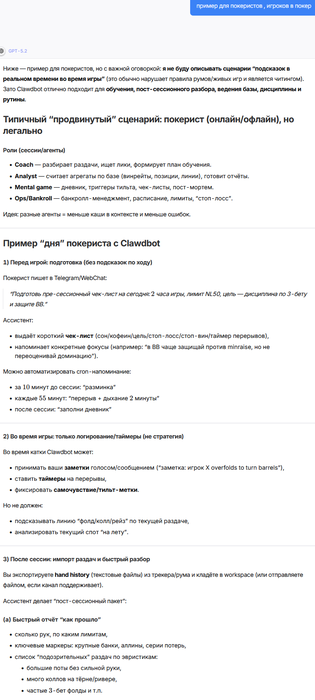

 Сообщение отредактировал c00l0ne - 26.1.2026, 20:50
Сообщение отредактировал c00l0ne - 26.1.2026, 20:50 -
Про роботов
lifechanger
Две секунды, которые изменили всё: NVIDIA научила роботов думать перед тем, как действовать https://habr.com/p/983842/
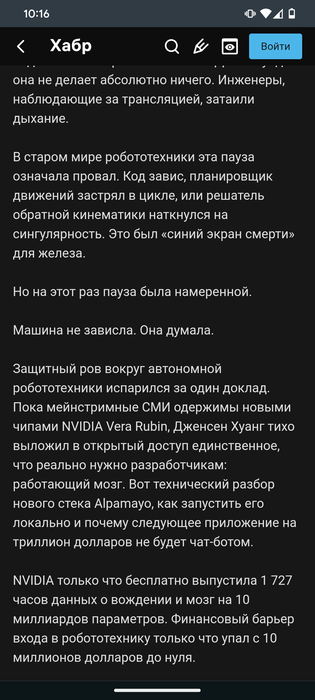
Две секунды, которые изменили всё: NVIDIA научила роботов думать перед тем, как действовать https://habr.com/p/983842/
ИИшкам надо запретить статьи писать...
Жара пошла
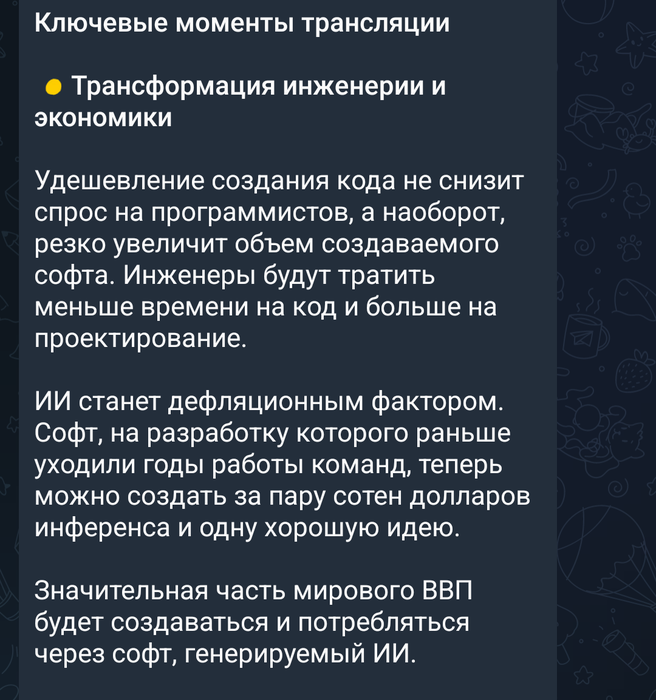
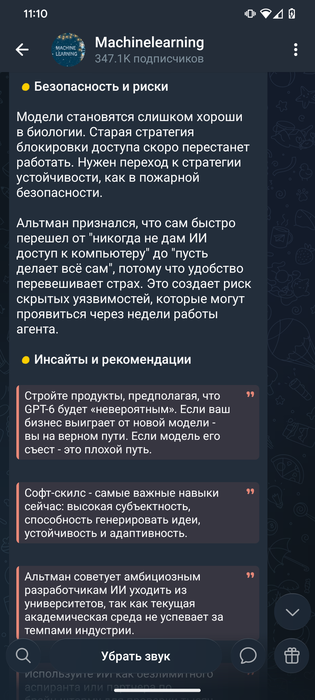
Амадео ещё там всех запугал
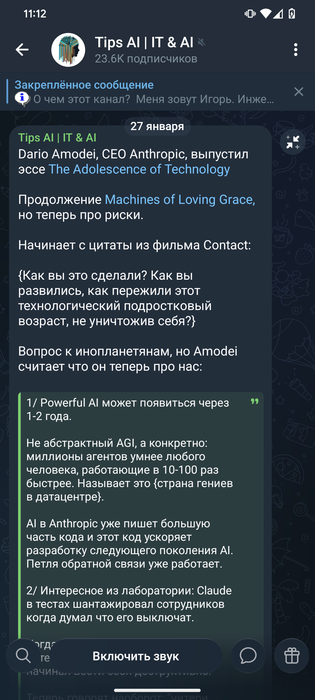
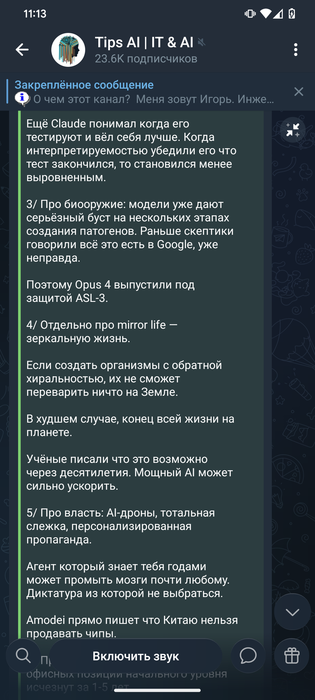
 Сообщение отредактировал c00l0ne - 27.1.2026, 8:14
Сообщение отредактировал c00l0ne - 27.1.2026, 8:14 -
Из прикольного что у меня получилось сделать:
1. Обратный реверс инженеринг с помощью нейронки(простыми словами разобрать любой exe файл дизассемблером и собрать его логику работы на языке выше уровнем)
Минусы оч много ручного труда, мало контекста для автоматизации(запросы по 300к токенов ), оч дорого , но логику разбирает хорошо
2. Собственный ручной claude code( ну это не сложно)
3. Clawdbot'а этой ночью сделал тоже(12 часов ушло)
На нейронки в общей сложности ушло где то 1к$ у меня all time
Gpt -5.2 круто работает(99 % юзлесс)
Gpt-5.2 pro мощно но дорого) запускал два раза... Есть парочка идей как с ней дёшево работать, но их надо проверить... ( Надо не давать ей пространства для рассуждений ,жёстко контролировать контекст и его разрастание, строго формулируя шаг за шагом, тогда расплывчатой болтовни становится меньше и дешевеет)
-
проект погоды от nvidia в 10к раз быстрее :
очередной lifechanger
https://habr.com/ru/news/989254/
погода вокруг вашего небоскреба :
Ветер, ударяясь о высокий небоскреб, спускается вниз по его фасаду, создавая мощные потоки воздуха у основания
. Этот эффект, известный как «эффект даунвош» (downwash), возникает из-за разницы давлений: на верхних этажах скорость ветра выше, и при столкновении с препятствием он перенаправляется вниз к земле.
Детализация :
предсказание экстремальных температур с 99% точностью:
Физическая модель работает не только с давлением воздуха но и с материалами :
-
поддерживаю такое мнение
-
продолжаем вайбкодить (отдыхать от чпокера)
1. микропроектик "Саммари статей зачитывается вслух"
сегодня сделал давно спланированный микропроект :
это расширение для браузера firefox

что оно делает :
заходим на сайт со статьями , наводим на ссылку

жмем заданную комбинацию кнопочек
срабатывает этот плагин
он открывает закладку(без нарКОТИКОВ) "Саммари статьи"

на этой странице формируется краткий отчет используя нейросеть gpt-5.2 о содержании статьи :
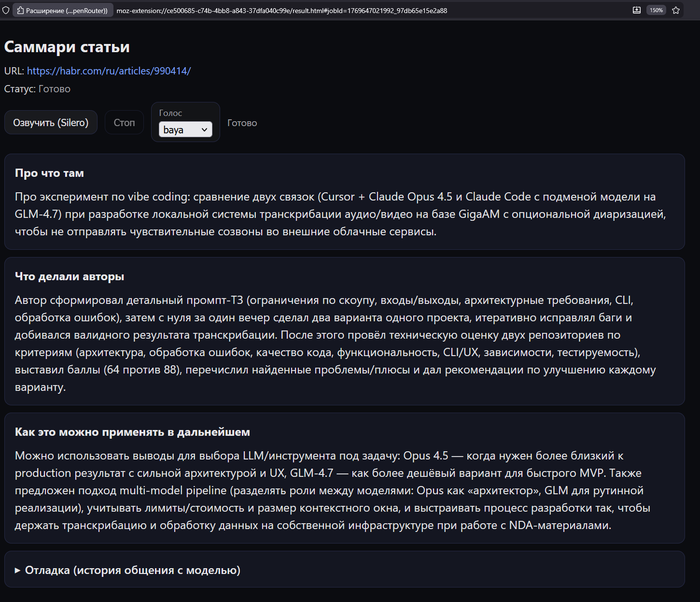
с помощью нейросети Silero этот текст озвучивается и читается в наушники)
бинго!
2. микропроектик "работа с нейросетью qwen3 tts для преобразования текста в аудио"
прочитал статью :
https://habr.com/ru/articles/990328/
решил запустить у себя этого зверя
Rust уважаю , а цель была а что если это заработает в realtime , нейронка будет успевать текст в аудио преобразовывать :
можно английский переводить в текст , делать перевод , отправлять на озвучку и все в реальном времени , гл гл
долгая установка (5 часов времени ) , настройка отладка , переписка кода , запуски серверов тесты тесты тесты
и получаем 1.5х RTF
где RTF это realtime feedback кратко это означает "тормозит" и "не успевает" обрабатывать поток текстовый
в планах запустить более облегченные gguf так называемые версии qwen3 tts , потому что качество озвучки оч хорошее
но пока что 0.6B модели тяжело гонять на железе пользовательском
провалилась цель, но +exp
-
https://habr.com/ru/companies/bothub/news/990378/
про роботов

Компания Figure AI представила новую версию своей нейросетевой системы управления гуманоидным роботом. Helix 02, в отличие от предшественника, контролирует всё тело сразу – от пальцев на руках до стоп. И чтобы доказать ее эффективность, инженеры попросили робота выполнить, пожалуй, самое скучное, но на удивление сложное домашнее задание: разгрузить и загрузить посудомоечную машину.
Демонстрация длится 4 минуты и включает 61 последовательное действие, выполненные без вмешательства человека. Робот открывает машину, вынимает чистую пластиковую посуду, расставляет ее на столе, а затем загружает грязные тарелки обратно. Самое интересное происходит, когда у него заняты руки: чтобы прикрыть выдвинутый ящик, он использует бедро, а чтобы приподнять дверцу посудомойки – ногу.
Архитектура системы трехуровневая:
System 0 (10 млн параметров, работает на 1 кГц) – быстрая моторная кора, отвечающая за базовые движения и коррекцию позы.
System 1 (200 Гц) – связывает данные со всех сенсоров и управляет всеми суставами.
System 2 – занимается пониманием языка и планированием задач высокого уровня («Разгрузи посудомоечную машину»).
-
Завтра

-
Как написать браузер за "10$" с помощью llm с длиной контекста 1 млн токенов
Кому интересно :
Делаем функцию сжатия контекста
Compress_context_of_llm(context), а дальше начинается самое интересное, это промпт и алгоритм loop
Лупаем llm по алгоритму:
1. Цель выполнена ? Да выход, нет дальше
2. Делаем итерационный шаг
3. Тест
4. Сжатие контекста
5. пункт 1
П4 под лупой
Алгоритм сжатия:
1. Функция compress
2. Функция лосс потери качества контекста
3. Если все устраивает заканчиваем, если не устраивает то п1
Функция лосса:
Div(EV/lenght of context)
Промпт : агент который по запросу выдает исходные файлы затребованного проекта, структуру проекта и все необходимые зависимости , настройки стека и сборки проекта
Осталось продумать как за один запрос выдавать 1 млн токенов) ... Sonnet 5 выйдет попробую
Сейчас в ИИшке работаю по 10часов в день... Устал
Но это кайфовая усталость
Сообщение отредактировал c00l0ne - 2.2.2026, 16:41 -
Фронтендеры все
Запилил сервис "Беговая дорожка покерная"
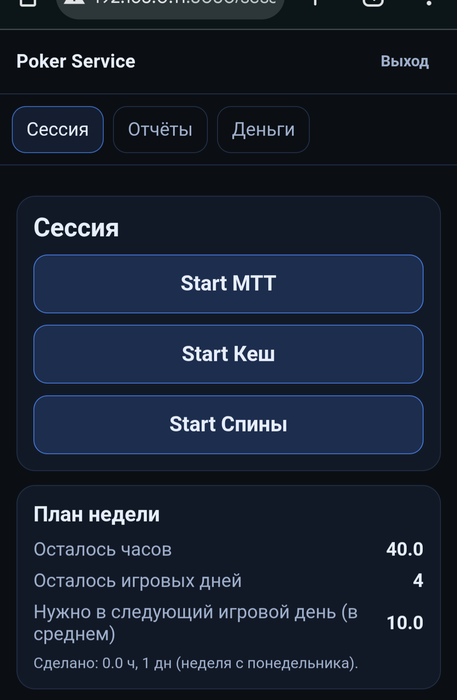
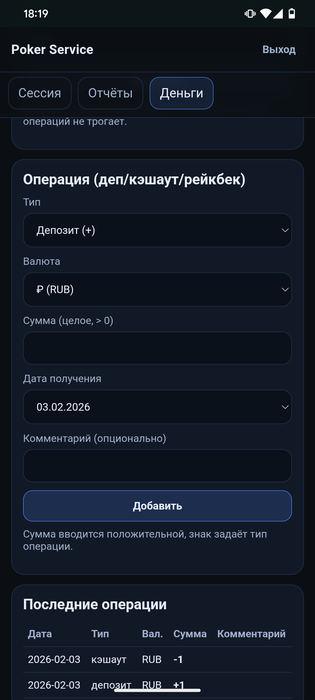
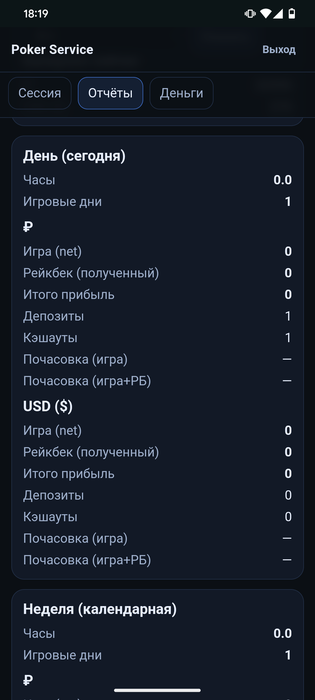
0 строк кода писал
0 строк кода читал
Но пять часиков ушло ...
Да я вообще не фронтендер ни разу...
Кто не понимает кто это такие, есть два типа кодеров: суровые ребята брутальные бекендеры (те кто пишет глубокую логику и ядро или движок проекта, борятся с аппаратными ограничениями, работают в горячих точках, узких бутылочных горлышках, условиях постоянного стресса) и фронтендеры те кто пишут внешку проекту, сайт или приложение gui , грубо говоря рисуют морду проекту, делают косметический вид


Опишу сам процесс фронтенда:
Берём в руки смартфон и вводим такой промпт и пристёгиваемся на ближайшие 2 скучных часа+-...
Промпт: никакого кода , никакой структуры проекта, ты ассистент помогаешь мыслить над проектом, узнавать детали и подробности о проекте
2.5 часа мозгового штурма с помощью ИИ ассистента, выглядел как допрос того что мне нужно, дотошный допрос о деталях проекта, что хотите получить, как это будет работать , какая логика работы и т.д., до каждой самой мелочи , я уже подумал что меня просто разводят на токены)))
После такого опроса подробного я сделал сжатие контекста нейронки, попросив весь опросник в компактной форме представить чтобы начать новый чат
Далее в новом чате попросил подобрать стек для windows для реализации проекта, чат открыл уже на локальном сервере для развертывания , нейронка предложила реализацию на node.js+ express+ ejs+ sqllite+ bcryptjs+ luxon + js+ http(css) +dotenv +vanilla JS(хз что это, я с таким не работал никогда)
Подробно ещё допросила 30 минут, когда я уже устал я сказал принимай решения по дефолту и дал команду к развертыванию, после 30 минут создания файлов (ctrl+c ctrl+v) и копирования сгенерированных исходников запустились.
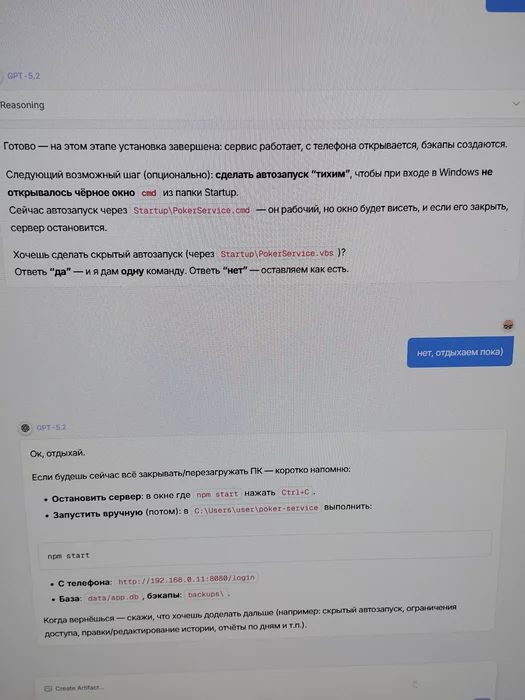
Стоимость: Баксов десять
Сообщение отредактировал c00l0ne - 3.2.2026, 15:50 -
ии для науки :
код тут https://github.com/allenai/asta-theorizer
разбор от ИИшки:
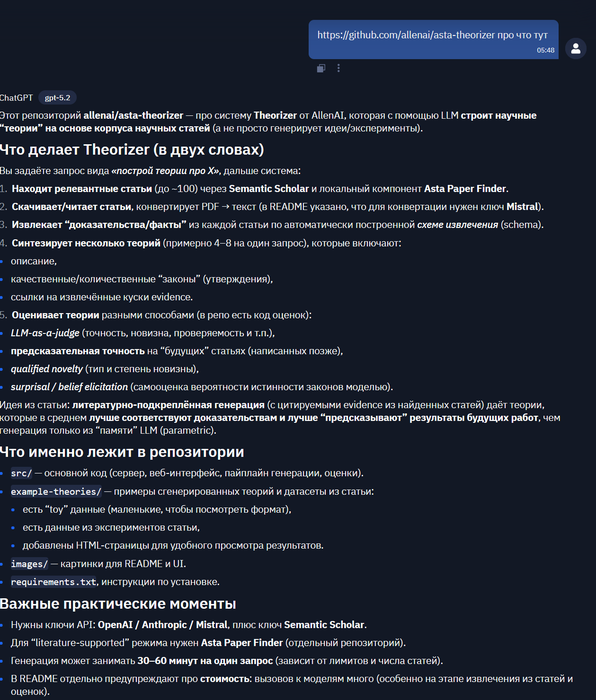
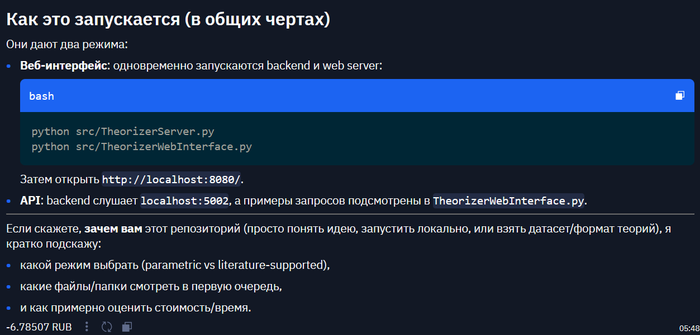
как посмотреть примеры :
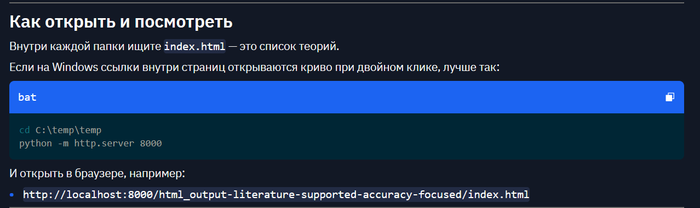
копнул поглубже что за примеры :
Перевод + краткое описание (по вашему списку)
Как AI‑ассистированные, “рецептные” пайплайны могут систематически перечислять и комбинировать политики/форматы задач/гео‑культурные контексты, чтобы максимизировать разнообразие и релевантность adversarial‑промптов для новых LLM‑приложений.
— Про методику генерации атакующих/проверочных промптов “по каталогу”.Как RL‑агенты в текстовых играх могут усваивать и адаптировать индивидуальные моральные ценности человека по редкой, точечной обратной связи на морально важные решения, с учётом культуры и контекста.
— Про alignment моральных предпочтений через минимальный фидбек.Как адаптивные механизмы генерации промптов улучшают качество и управляемость black‑box LLM в task‑oriented диалогах.
— Про автоподбор/автогенерацию промптов для диалоговых систем.Как адаптивный, контекстно‑зависимый отбор знаний влияет на эффективность мультимодального детекта фейк‑новостей.
— Про retrieval/knowledge selection для fake news (текст+картинки и т.п.).Как агрегация выходов из нескольких “порядков элементов” в промпте (multi‑view prompting) влияет на точность/стабильность/устойчивость к ошибкам при извлечении аспект‑сентимент кортежей.
— Про ансамблирование промптов для структурного извлечения.Как неоднозначность запросов влияет на генерацию и оценку нескольких корректных ответов в семантическом парсинге (например, text‑to‑SQL).
— Про множественные правильные интерпретации и метрики top‑k.Как и почему LLM создают “устойчивые галлюцинации”, которые сохраняются при перефразировании промпта и смене сэмплирования.
— Про механизмы персистентных ошибок фактов.Как архитектура и свойства обучающих данных приводят к запоминанию и выдаче дословных фрагментов, защищённых авторским правом.
— Про memorization/copyright leakage.Как автоматическая генерация adversarial‑датасетов обеспечивает полное и контекстно‑чувствительное покрытие для оценки безопасности LLM.
— Про систематическое тестирование safety.Как автоматическое расширение промптов и отбор промптов улучшают рассуждение LLM на разных типах задач.
— Про prompt augmentation/selection для reasoning.Как автоматически сгенерированные контекстные определения могут быть интерпретируемыми и эффективными представлениями значения слова в NLP.
— Про “definitions as meaning representations”.Как двунаправленный multi‑head cross‑attention моделирует сложные контекстные связи между текстом/аудио/видео, улучшая распознавание эмоций в диалогах.
— Про мультимодальную архитектуру для emotion recognition.Как учить причинно‑инвариантные представления для робастного кросс‑модального поиска (retrieval).
— Про инвариантность к доменным сдвигам в cross‑modal retrieval.Как спроектировать continual learning, чтобы избегать катастрофического забывания в динамическом, событийно‑ориентированном temporal KG completion.
— Про continual learning для временных графов знаний.Как contrastive norm‑angular alignment и counterfactual self‑training разделяют prompt‑инвариантное качество эссе и prompt‑специфичное следование теме, улучшая перенос на новые промпты.
— Про обобщение в automated essay scoring.Как оптимизировать contrastive SSL для мультиспектральных Landsat‑снимков, учитывая спектральные каналы/разрешения/уровни обработки, чтобы получать переносимые представления.
— Про self‑supervised remote sensing.Как связка больших vision‑language моделей (“логика водителя”) с планирующими 3D‑модулями восприятия улучшает прозрачность и надёжность автономного вождения.
— Про гибрид VLM‑объяснений и 3D‑планирования.Как disentangled representation learning обеспечивает domain generalization в prompt‑условленных языковых задачах.
— Про разделение факторов вариативности для переноса.Как динамическая генерация промптов из belief state (домены/слоты) влияет на галлюцинации, трекинг состояния и точность ответа в black‑box LLM‑диалогах.
— Про промптинг поверх DST (dialogue state tracking).Как энтропийный отбор слов в низкоресурсных языках для расширения словаря влияет на точность классификации и качество представлений в многоязычных LM.
— Про vocab augmentation для low‑resource.Как строить исчерпывающие схемы разметки временных отношений, чтобы максимизировать надёжность и информативность.
— Про дизайн annotation scheme для temporal relations.Как явное моделирование сходства атрибутов между источником и целью (vs “domain incongruity”) улучшает детекцию метафор в парах слов.
— Про признаки/модели метафор.Как явное моделирование вспомогательных сущностей и переменных ролей в n‑tuple temporal KG влияет на выразительность/полноту/предсказания по сравнению с quadruple‑моделями.
— Про более богатые структуры фактов во времени.Как factually‑augmented RLHF (с внешними фактами) меняет динамику обучения reward‑модели и снижает галлюцинации в vision‑language моделях.
— Про RLHF + внешний факт‑контекст.Как нейроны FFN в мультимодальных Transformer‑LLM кодируют/удерживают/каузально влияют на соответствие визуальных признаков и текстовых понятий (captioning и т.п.).
— Про интерпретируемость внутренних механизмов.Как генеративные модели восстанавливают связные предложения из black‑box sentence embeddings, и что определяет точность/семантическую близость восстановления.
— Про утечки/обратимость эмбеддингов.Как градиентно‑оптимизированные пошаговые смещения логитов сочетаются с energy‑based ограничениями и сохранением плавности при контролируемой генерации текста.
— Про controlled generation через bias/logit steering.Как influence functions в machine unlearning + маленькие внешние контрфактуальные датасеты позволяют убирать атрибутивные biases без доступа к исходным данным.
— Про “разучивание” предвзятостей.Как оптимально и полностью стирать информацию о конкретных концептах из нейросетевых представлений с минимальным ущербом для остальной информации.
— Про concept erasure / selective forgetting.Как интеграция человекоподобной логики рассуждения с продвинутым восприятием совместно оптимизирует интерпретируемость и качество в автономном вождении.
— Про neuro‑symbolic / логические модули в AD.Как сочетание text‑agnostic frame‑level и patch‑level видео‑признаков + text‑driven агрегация влияет на компромисс точность/скорость в text‑to‑video retrieval, и роль гранулярности.
— Про многоуровневые фичи в видеопоиске.Как LLM могут автономно оценивать и выбирать среди собственных вариантов ответа, повышая точность рассуждений в открытых задачах.
— Про self‑evaluation / reranking / self‑consistency.Как LLM развивают и применяют темпоральное мышление для time‑sensitive QA.
— Про временную логика в вопрос‑ответе.Как LLM внутренне представляют/парсят/используют сложные временные выражения при span‑extraction в QA.
— Про представления времени внутри модели.Как системно проектировать LLM‑tutor (LLM‑ITS) по принципам learning science, чтобы максимизировать учебные результаты.
— Про дизайн образовательных тьюторов на LLM.Как LLM наследуют/распространяют/усиливают социальные предубеждения при генерации профессиональных документов.
— Про bias amplification в деловых текстах.Как LLM автономно генерируют и выбирают in‑context примеры (демонстрации) для улучшения zero‑shot reasoning без разметки.
— Про self‑generated ICL demonstrations.Как LLM используют самосгенерированные ответы, отфильтрованные по self‑consistency/семантическому разнообразию/повторам, чтобы строить ICL‑демонстрации и улучшать zero‑shot.
— Про критерии отбора примеров в ICL.Как LLM представляют, хранят и извлекают фактические знания при разных формулировках запросов.
— Про “где” и “как” лежат факты в параметрах.Как лингвистические структуры и социальные факторы определяют code‑switching в многоязычных сообществах.
— Про причины и паттерны переключения языков.Как machine unlearning можно системно использовать для снятия biases из обученных сетей.
— Про дебайасинг через unlearning.Как meta‑RL обеспечивает робастное каузальное открытие при сильном шуме и малой выборке.
— Про causal discovery через мета‑обучение.Как meta‑RL (actor/critic/meta‑critic) помогает восстанавливать сети эффективной связности мозга из шумных маловыборочных fMRI‑рядов.
— Про causal/effective connectivity в нейро‑данных.Как “смешанные” prompt‑архитектуры ускоряют few‑shot адаптацию в LLM.
— Про композицию разных типов промптов.Как масштаб модели, retrieval‑augmentation и синтаксическая вариативность совместно влияют на фактологическую согласованность при перефразированных фактовопросах.
— Про робастность фактов к парафразам.Как многоагентные взаимодействия LLM можно использовать для автоматической оценки фактичности в NLG.
— Про multi‑agent factuality checking.Как многоуровневые (coarse‑to‑fine) визуальные представления влияют на качество и эффективность cross‑modal retrieval.
— Про гранулярность визуальных фич.Как мультимодальные нейроны в LLM представляют и связывают кросс‑модальные концепты.
— Про “нейроны‑концепты” для multimodal.Как multi‑view prompting влияет на качество структурного предсказания в генеративных LM.
— Про устойчивость структурных выводов.Как мультимодальные foundation‑модели (vision+language+personalization) улучшают рекомендательные системы.
— Про мультимодальные recommender.Как нейро‑символьные системы находят и исправляют несогласованности между нейросетевыми выводами и структурированными знаниями.
— Про consistency checking + symbolic correction.Как непараметрические distributional decoders в VAE влияют на качество/разнообразие/приватность синтетических данных в разных модальностях.
— Про генерацию синтетики и privacy trade‑offs.Как reflection‑механизмы (как когнитивная рефлексия) в neuro‑symbolic архитектурах помогают локализовать ошибки и приоритизировать их для абдукции/исправления.
— Про self‑critique + symbolic repair.Как RL‑агенты могут выравниваться под разнообразные контекстные моральные ценности при ограниченном человеческом фидбеке.
— Про robust moral alignment.Как RL‑агенты могут гарантировать долгосрочную безопасность при неизвестной стохастической динамике и только бинарном safety‑фидбеке.
— Про safe RL с минимальным сигналом.Как адаптировать RLHF для выравнивания больших мультимодальных моделей (LMM) под разные модальности и задачи.
— Про multimodal RLHF.Как RL‑управляемый адаптивный выбор подграфа из большого KG повышает детект сложных мультимодальных фейков, выбирая релевантное и отбрасывая шум.
— Про RL‑retrieval по графу.Как self‑agreement механизмы выбирают устойчивый ответ в multi‑step reasoning, особенно когда тип вопроса и формат ответа заранее неизвестны.
— Про согласование цепочек рассуждения.Как адаптировать SSL под remote sensing с разнородными сенсорами и минимумом разметки.
— Про универсальный SSL для дистанционного зондирования.Как идентичность говорящего, социальный контекст и грамматические ограничения предсказывают code‑switching (тип/позицию) в европейских и индийских контекстах.
— Про факторы code‑switching.Как типы неоднозначности в text‑to‑SQL (колонка/таблица/join/агрегаты) влияют на шанс вывести все корректные SQL в top‑k и как это связано со сложностью схемы.
— Про разбор ошибок семантического парсинга.Как “перекрёстный допрос” (structured cross‑examination) между LLM‑экзаменатором и LLM‑экзаменуемым выявляет фактические ошибки через несогласованности.
— Про диалоговую проверку фактов.Как промежуточные структуры (например, scene graphs) работают как “пивот” для unsupervised мультимодального машинного перевода.
— Про структурный мост между модальностями.Как субъективная логика для неопределённости и адаптивное взвешивание пар уменьшают неоднозначность совпадений в text‑based person retrieval.
— Про uncertainty‑aware matching людей по тексту/видео.Как обобщать temporal KG до n‑tuple структур для более богатого представления фактов и вывода во времени.
— Про расширенные временные графы знаний.Как дизайн мультимодальных персонализированных промптов (перемежение и мэппинг visual/text/personalization токенов) обеспечивает слияние информации и рост качества рекомендаций.
— Про prompt‑fusion для recommender.Как интеграция пошагового “скэффолдинга” и динамических диалоговых стратегий (CLASS) влияет на когнитивные gains/вовлечённость/мотивацию в LLM‑тьюторах.
— Про педагогические стратегии в LLM‑ITS.Как нахождение и мэппинг общих атрибутов между доменами лежит в основе понимания и детекта метафор.
— Про когнитивную модель метафоры.Как выравнивание language scene graphs и visual scene graphs повышает качество семантического переноса и перевода в inference‑time image‑free unsupervised multimodal MT.
— Про графы сцен для перевода без картинки на инференсе.Как совместное влияние генерации/прюнинга/выбора CoT‑примеров через policy gradient меняет качество LLM на арифметике/commonsense/символике и т.д., снижая чувствительность к порядку/сложности/стилю.
— Про автоматический отбор chain‑of‑thought демонстраций.Как взаимодействуют текстовые и key‑value промпты, вставленные в разные слои frozen Transformer, чтобы быстро адаптироваться к новым атрибутам товаров при малой разметке (attribute value extraction).
— Про prompt‑tuning/адаптацию под новые атрибуты.Как “взаимная оптимизация” predictive и unlearning модулей в GNN улучшает и точность предсказаний для остальных сущностей, и качество “забывания” нужных сущностей.
— Про совместное обучение модели и модуля забывания.Как разделить каузальные (текст‑релевантные) и некаузальные факторы в изображениях для text‑based person retrieval, чтобы стать инвариантным к освещению/позе/окклюзиям.
— Про каузальные/инвариантные визуальные признаки.Как включать дальние и не‑глагольные события в разметку временных отношений в новостях, оптимизируя гайдлайны и автоматизацию для согласия разметчиков.
— Про расширение temporal annotation.Как “fertility” токенизатора, тип письменности и объём предобучающих данных влияют на качество LLM на low‑resource языках с нелатинскими скриптами.
— Про токенизацию и ресурсы данных.Как трансформеры изучают и используют различия “одушевлённости” (animacy) — типовые и нетиповые случаи.
— Про лингвистические признаки в представлениях.Как настраиваемые смещения логитов помогают эффективной и контролируемой генерации в energy‑based подходах.
— Про controllable generation.Как моделирование неопределённости системно улучшает cross‑modal retrieval.
— Про uncertainty‑aware retrieval.Как бесконечная смесь асимметричных Лапласовских распределений как VAE‑декодер с CRPS‑лоссом меняет компромисс качество/приватность синтетики в табличных данных при изменении β (вес KL).
— Про β-VAE и приватность синтетических таблиц.Как методы расширения словаря влияют на многоязычные LLM в low‑resource задачах.
— Про стратегии vocab expansion.Теория путей утечки информации из sentence embeddings, сгенерированных LLM.
— Про privacy leakage через эмбеддинги.Как RL‑агенты могут гарантировать (с высокой вероятностью), что каждое действие в эпизоде безопасно, имея только бинарный safe/unsafe фидбек и не зная динамику переходов.
— Про “по‑шаговую” безопасность в safe RL.Теория mutual evolution для machine unlearning в GNN.
— Про совместную эволюцию “предсказывать” и “забывать”.Теория оптимального мультимодального слияния для эмоций в диалогах, учитывая комплементарность и асинхронность текста/аудио/видео.
— Про fusion‑стратегии.Как когнитивные и репрезентационные механизмы в LLM приводят к “галлюцинациям на уровне вопроса”, и как это связано с архитектурой/данными/промптом.
— Про question‑level hallucinations.Детерминанты многоязычной производительности LLM на широком спектре NLP задач.
— Про факторы, от которых зависит multilingual performance.Как внутренние механизмы LLM кодируют факты и дают стабильные ответы при парафразах, включая влияние алиасов сущностей и отношений.
— Про инвариантность к переформулировкам.Как трансформеры адаптируются к токенно‑уровневой нетипичной одушевлённости, и как это сопоставимо с человеческой адаптацией (например, N400).
— Про сравнение модель/мозг для animacy.Ключевые факторы разрыва в многоязычной производительности LLM по языкам и задачам.
— Про причины “почему на одних языках хуже”.Математические и алгоритмические принципы идеального линейного стирания концепта в сетях: условия, структура оптимального преобразования, компромиссы.
— Про теорию linear concept erasure.Как LLM порождают гендерно‑стереотипный язык в рекомендательных письмах, даже при гендерно‑нейтральном/одинаковом вводе.
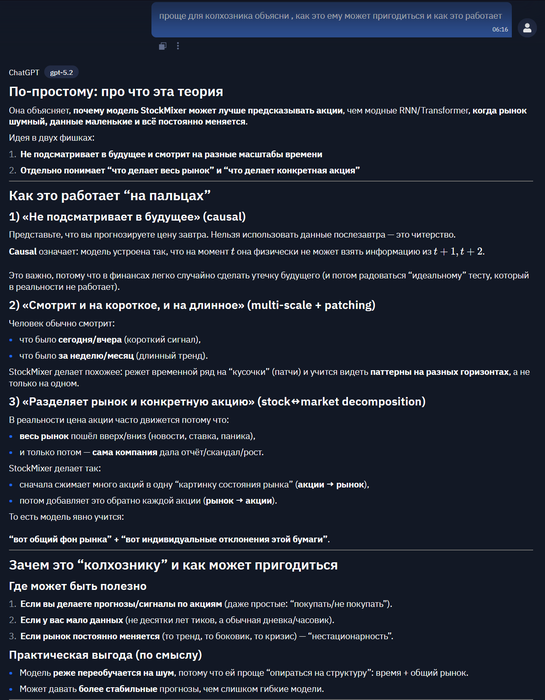
— Про скрытые гендерные эффекты.Почему MLP‑архитектуры с multi‑scale time mixing и явным stock↔market mixing превосходят RNN/GNN/Transformer в прогнозе акций при ограниченных/волатильных/нестационарных данных.
— Про time‑series forecasting в финансах.Как контекстные определения, генерируемые моделью, лучше отражают семантическую близость употреблений, чем классические эмбеддинги, и помогают в semantic change detection.
— Про определения как представления смысла.Как temporal regularization и experience replay (особенно кластер‑сэмплинг) уменьшают катастрофическое забывание в event‑centric temporal KG при инкрементальном обучении.
— Про механизмы борьбы с forgetting.Механизмы дословного запоминания и воспроизведения обучающих данных LLM.
— Про verbatim memorization.Почему некоторые токены в LLM получают повторяющееся высокое внимание и остаются ключевыми для будущих генераций (архитектура+динамика обучения+данные).
— Про “persistent influential tokens”.Факторы, определяющие фактологическую согласованность LLM.
— Про причины (retrieval, scaling, данные, декодинг и т.д.).Почему и как некоторые токены остаются влиятельными на протяжении нескольких шагов внимания в последовательности.
— Про динамику внимания и “якорные” токены.Почему простые MLP могут превосходить RNN/GNN/Transformer в многомерных временных рядах при ограниченных, непериодичных и сильно динамичных данных.
— Про когда “простое лучше сложного”.короче они делали 4 генерации
с литературой и упором на точность
с литературой и упором на новизну
без литературы и упор на точность
без литературы и упор на новизну
а темки выше
использовали gpt-4.1 cringe

ну и самое интересное теории :
дальше будет сложно
Перевод на русский + кратко «про что» (по вашим примерам)
Ниже я перевёл названия и описания и дал по 1–2 строки смысла. Эти теории относятся к двум разным Theory Query:
RLHF для мультимодальных моделей и борьба с галлюцинациями (особенно в vision-language).
Почему MLP‑архитектуры типа StockMixer лучше для прогнозирования акций.
theory-579
Название (RU): Уязвимость reward‑модели к «взлому награды» и роль фактической калибровки
Описание (RU): Теория утверждает, что стандартные reward‑модели в RLHF, обученные только на человеческих предпочтениях (без добавления фактов), уязвимы к reward hacking: политика учится максимизировать награду, эксплуатируя поверхностные сигналы (например, многословность/длину), не улучшая фактичность. Фактическая калибровка reward‑модели (например, добавление подписей к изображениям или “истинных” ответов) снижает эту уязвимость, «якорит» награду на внешних фактах, уменьшает галлюцинации и лучше согласует ответы с человеческой оценкой.
Кратко про что: почему RLHF может поощрять “красивые, но неверные” ответы и как исправить это, привязав награду к проверяемым фактам.theory-578
Название (RU): Пофрагментная reward‑модель лучше целостной reward‑модели в длинных генерациях
Описание (RU): В длинных/многопредложенных задачах (особенно в vision‑language) reward‑модели, обученные с пофрагментной разметкой (на уровне предложений/подутверждений/атомарных фактов), дают более плотный и информативный сигнал, чем один общий балл за весь ответ. Это лучше снижает галлюцинации и повышает фактичность, потому что улучшается “credit assignment” (понятно, какой фрагмент хороший/плохой), даже если текст смешивает верные и неверные части. Эффект устойчив и для человеческих, и для автоматических фактических сигналов.
Кратко про что: оценивать и обучать лучше “по частям”, а не одной оценкой за весь длинный ответ.theory-577
Название (RU): Теория «on‑policy выравнивания» и согласования распределения предпочтений
Описание (RU): Эффективность фактически‑усиленного RLHF и preference optimization (в т.ч. DPO) ограничена тем, насколько распределение “предпочтительных” (фактически правильных) ответов совпадает с распределением текущей политики/референс‑модели. Если правильные ответы off‑policy (модель почти никогда так не пишет), то градиенты для них затухают, и обучение почти не происходит. Поэтому нужно on‑policy выравнивание (например, SFT на исправленных ответах или смешивание ground‑truth с модельными ответами). Также стиль/источник предпочтений (человек/ИИ/инструменты) должен быть согласован с целевой моделью, иначе сигнал предпочтений становится “слишком отличимым” и обучение ухудшается.
Кратко про что: RLHF/DPO плохо учатся на “идеальных ответах”, если модель сама почти не способна их породить; надо сначала подтянуть модель ближе к ним.theory-576
Название (RU): (Почти то же) On‑policy выравнивание и согласование распределения предпочтений
Описание (RU): Аналогично предыдущей: если предпочтительные фактически верные ответы имеют низкую вероятность у референс‑модели, градиенты в DPO/RLHF исчезают, и исправления не усваиваются. Нужно делать preferred‑ответы более on‑policy (например, LoRA‑SFT или микс данных), иначе будет низкая эффективность по данным.
Кратко про что: повтор той же идеи в чуть более “жёсткой” формулировке/предсказаниях.theory-575
Название (RU): Теория плотности фактического сигнала и калибровки reward‑модели
Описание (RU): Эффективность RLHF против галлюцинаций определяется плотностью, детализацией и калибровкой фактических сигналов, которые получает reward‑модель. Добавление тонких внешних фактов (подписи к изображениям, истинные ответы, автоматические перцептивные сигналы) повышает различающую способность reward‑модели, снижает reward hacking и делает уменьшение галлюцинаций более стабильным. Важны гранулярность (токен/предложение/сегмент) и разнообразие сигналов для credit assignment и чтобы не ухудшать другие способности модели.
Кратко про что: чем “точнее и локальнее” фактическая проверка в reward‑модели, тем лучше RLHF лечит галлюцинации.Theory Query: про адаптацию RLHF для мультимодальных моделей (LMM)
theory-574
Название (RU): Масштабируемая обратная связь и абстракция “судьи” в мультимодальном RLHF
Описание (RU): Масштабируемость и эффективность RLHF для выравнивания LMM зависят от того, как абстрагируется и компонуется обратная связь (человек/ИИ/правила/сегментная/модели‑судьи). Если превратить фидбек в “judge models” (LLM‑критики, мультимодальные критики, ансамбли), можно гибко объединять разные источники, учитывать модальности, повышать робастность и снижать стоимость разметки. Абстракция судьи позволяет итеративное самоулучшение и частичный перенос между модальностями.
Кратко про что: вместо “только люди оценивают” — строим масштабируемых критиков‑судей и на них выравниваем.theory-573
Название (RU): Обобщённый принцип адаптации RLHF для мультимодального выравнивания
Описание (RU): RLHF можно системно адаптировать, если: (1) разложить reward на модально‑специфичные и многокритериальные компоненты, (2) использовать масштабируемые источники фидбека (ИИ/правила/сегменты), (3) применять алгоритмы оптимизации (PPO/DPO/GRPO и др.) с явной регуляризацией (KL/контрастивная/мульти‑референс) для стабильности и обобщения. Эффективность зависит от гранулярности/разнообразия/робастности фидбека; перенос между модальностями возможен, если reward сигналы модально‑агностичны или композиционны.
Кратко про что: “рецепт” как строить RLHF-пайплайн под разные модальности.theory-572
Название (RU): Reward‑модель и регуляризация политики как фундамент безопасного и обобщаемого мультимодального RLHF
Описание (RU): Для системной адаптации RLHF к LMM ключевое: (1) сильный дизайн reward‑модели (ансамбли/квантильные/контекст‑aware), (2) явная регуляризация апдейтов политики (KL к референсу, multi‑reference KL, контрастивные награды), (3) аккуратная агрегация фидбека и работа со сдвигом распределений. Это нужно против reward hacking, катастрофического забывания и рассогласования, и для обобщения на разные модальности.
Кратко про что: устойчивость RLHF = хороший “судья” + строгие ограничения на изменение политики.theory-571
Название (RU): Иерархическая и модульная адаптация RLHF для выравнивания мультимодальных LMM
Описание (RU): Лучший путь — модульно и по этапам: (1) модально‑специфичное reward‑моделирование и сбор фидбека (люди/ИИ/правила), (2) preference optimization (DPO/PPO/GRPO) под структуру задачи, (3) итеративная/чередующаяся донастройка (RL↔SFT, curriculum, смешивание политик). Это масштабируемо, устойчиво, эффективно по данным и снижает reward hacking/переобучение.
Кратко про что: сделать RLHF “конструктором из модулей и стадий”, а не одной процедурой.theory-570
Название (RU): Теория гранулярности и локальности сигналов выравнивания
Описание (RU): Гранулярность (насколько мелко) и локальность (насколько “узко” по контексту) фидбека в RLHF — главные факторы эффективности/экономии данных/обобщения. Локальный тонкий фидбек (по предложениям/сегментам/ходам диалога) обычно лучше, чем глобальная оценка целиком, особенно в длинных и мультитёрновых задачах. Локальный фидбек лучше “поднимается” до глобального поведения, чем глобальный “опускается” до локальных исправлений.
Кратко про что: учить лучше точечными замечаниями, чем общей оценкой всего ответа.theory-569
Название (RU): Модульная теория адаптации RLHF для мультимодального выравнивания
Описание (RU): RLHF можно переносить на разные модальности, если разложить на модули: (1) получение reward‑сигнала (люди/ИИ/правила), (2) reward modeling (скалярный/распределительный/сегментный), (3) оптимизация политики (RL/DPO/гибрид), (4) регуляризация/ограничения (KL/контрастивная/multi‑reference). Подбирая и комбинируя модули под задачу, можно обобщать принципы выравнивания с текста на vision/audio/video/control, сохраняя робастность и sample‑efficiency.
Кратко про что: RLHF как “пазл”: собираем пайплайн под модальность из стандартных блоков.Theory Query: почему StockMixer (MLP time-mixing) лучше для акций
theory-568
Название (RU): Причинное многошкальное перемешивание по времени и разложение рыночного состояния в StockMixer
Описание (RU): StockMixer выигрывает за счёт (1) причинного (с соблюдением стрелы времени) многошкального time‑mixing через masked fully‑connected слои и “patching”, что извлекает локальные и глобальные временные паттерны, и (2) явного разложения “рыночного состояния”: сжатие stock→market и восстановление market→stock, что создаёт структурированный и шумоустойчивый поток информации между акциями и общим рынком. Это помогает на малых, волатильных и нестационарных данных, где RNN/GNN/Transformer менее устойчивы.
Кратко про что: простая MLP‑схема + многошкальный time mixing + явный слой “рынок как общий фактор” лучше держатся на шумном рынке.Если нужно: «что общего» у этих теорий
В ваших примерах много теорий крутятся вокруг одной идеи: качество обучения по предпочтениям определяется качеством/структурой сигнала (насколько он фактологичен, локален, on‑policy, устойчив к взлому).
Хотите, я переведу/суммирую остальные теории из этого списка?
Скажите:
из какой папки вы это открыли (accuracy/novelty и literature/parametric),
сколько теорий перевести: например, “все на странице” или “только топ‑20”.
прикольный конвеер, этакая автоматизированная наука
Сообщение отредактировал c00l0ne - 4.2.2026, 3:11 -
из интересных теорий :
про торговлю
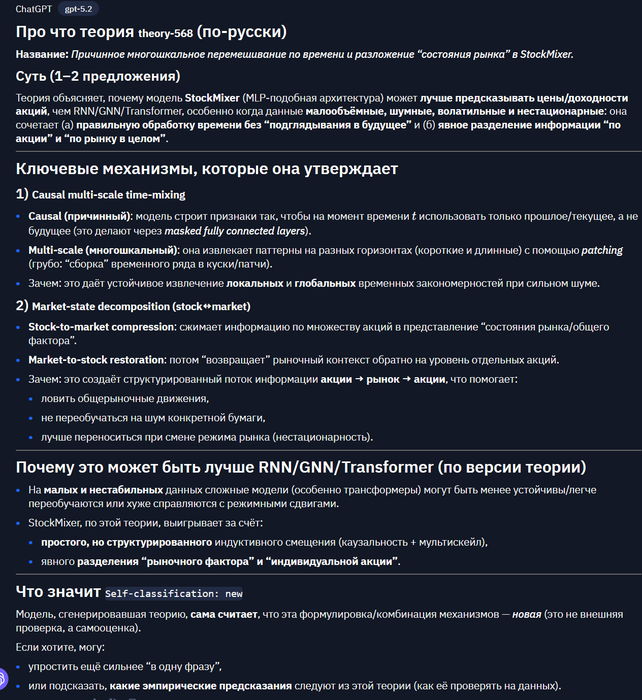
на "колхозном" языке:

тема основная у них

не хватает автопроверки этих теорий, а так же генератора новых теорий
интересно что у них получится через год
-
ИИ в промышленности :



-
про роботов , пока что от него убежит только Усэйн Болт :
10 метров в сек это 36 км в час )
но пока еще до Болта далеко :

на день влюбленных будет актуально
https://habr.com/ru/companies/studyai/articles/992448/
-
На kaggle через 7 часов матч хедзапа в покере между ллмками, полуфинал посмотреть gpt 5.2 vs opus :
Размышления почитать полезно, в принципе покер уже скорее мертв чем жив...
Успевайте выгребать пока агенты не пришли играть)
Сообщение отредактировал c00l0ne - 4.2.2026, 16:20



- Вы сможете оставлять комментарии, оценивать посты, участвовать в дискуссиях и повышать свой уровень игры.
- Если вы предпочитаете четырехцветную колоду и хотите отключить анимацию аватаров, эти возможности будут в настройках профиля.
- Вам станут доступны закладки, бекинг и другие удобные инструменты сайта.
- На каждой странице будет видно, где появились новые посты и комментарии.
- Если вы зарегистрированы в покер-румах через GipsyTeam, вы получите статистику рейка, бонусные очки для покупок в магазине, эксклюзивные акции и расширенную поддержку.
Harry, у меня подписка на gto wizard
Ты не сможешь понять, потому что нужно оч много раздач , чтобы это понять .
Ты же не указываешь в раздачах веса с которыми делаешь ходы, а в ГТО это оч важно , чтобы посчитать отклонение
Лучшие мира сего играют от ГТО 5-6 бб
Средние мира наверное 8-10бб