Дневник c00l0ne
-
ПопулярностьТоп-162
-
Постов11,212
-
Просмотров1,012,980
-
Подписок90
-
Карма автора+1,029
-
Заходят три математика в бар. Бармен спрашивает: - Все будут пиво? Первый математик:&nbs
+25
-
c00l0ne, я ещё никогда так не впахивал как до развития claude code :) Появление LLM
+24
-
Shtirlitz, fastdecision, Feliz, вы не представляете как вам повезло что вы это только здесь читаете,
+20
-
+17
-
Мне однажды сказали примерно следующее: -Не так страшно ,когда человек творит откровенную чушь , куд
+17
-

-
вероятность интересно какая, на дверной замок записали падение крошечного метеорита с кратером 2 см :
-
читали уже ?
как солверные челы Фила Айви обували
и Гас Хансена...
про трутеллера :


ps кто английским не владеет как я устанавливайте DeepL for Windows
выделяете абзац и два раза жмете CTRL+C
Сообщение отредактировал c00l0ne - 18.1.2025, 4:41 -
Купил o1 на месяц подписку, если есть какие то вопросы интересные пишите , поспрашиваю...
Это конечно не o1 pro за 200$ в мес и не o3 mini которая не за горами, это не суперскиловая и такая же супернедосягаемая o3 и o3 pro , но в целом впечатляющие результаты умеет выдавать:


вот такое решение на одну суперсложную задачку выдает :

решение :
Сообщение отредактировал c00l0ne - 19.1.2025, 6:45 -
задача на самом деле не супер сложная как автор ее представляет в ролике , добавил одно измерение :

формула выглядит верной 1/2^n
еще маленько "помучал " про решение через интегралы


слабовато) я подобную задачу сдавал на 2ом курсе в качестве экзамена
Сообщение отредактировал c00l0ne - 19.1.2025, 17:59 -
новости ИИ

-
Серхи Грац
Вуп вуп , всех пересидел...
Мисскликал ,ошибался ...
Гсч все простило
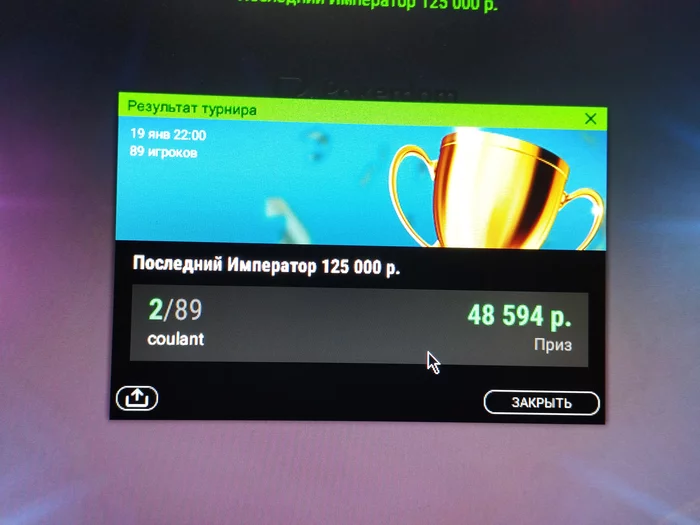
Бр 80к
-

Ты там не заснул в топ6-8?) как будто связь пропадала
-
Dino84 @ 19.01.25
Ты там не заснул в топ6-8?) как будто связь пропадала
Тянуть время +Ев как ты это не понимаешь и там не 10% рои, нормально ты там со всеми разобрался) только против короткого я бы не задвигал, когда ты его вроде скупануть мог легко и фулл собрать, мог его ещё быстрее убрать... Такой трудный путь в мтт ... Доехать кайф конечно, в императоре х2 кайф
-

c00l0ne, не турниры, а шляпа.
-
Сообщение отредактировал c00l0ne - 20.1.2025, 1:06
-
у NesherBoy'я подсмотрел марафон по мтт холдему :
- отыграть 1000 турниров без реентри
- вход не позднее 50 бб стеков
по времени это займет где-то 1.5 месяца
набить 100к рук и посмотреть свои ев / bb
взять треню или самостоятельно разобрать базу
потом можно поплотнее покатать с реентри ...
-
тут такие новости подъезжают с каждым месяцем :

https://habr.com/ru/companies/bothub/news/874794/
осталось 10 дней
это оч опасно
30 января представят в Вашингтоне
Сообщение отредактировал c00l0ne - 20.1.2025, 4:53 -
-
ии(пора бложик в ИИ новости переименовывать ):

Если что-то про покер хочется обсудить — спрашивайте.
Но, думаю, с появлением солвера Олега вопросы по китайскому покеру лучше решать там.Тут солвер «всего и всея» буквально пишется на глазах… В интересное времечко живём!
Что происходит, многим, наверное, будет непонятно. Есть вопрос, есть ответ. Представьте интернет в виде:
ВОПРОС – ОТВЕТ
— Земля круглая? — Да!
— Чем занимается офтальмолог? — Лечит глазные заболевания.
И так далее.Весь интернет в виде «вопрос–ответ», представьте — это тысячи дисков информации, накопившейся за время существования интернета.
Всё это научились использовать в качестве данных для обучения трансформер-нейросети. Выше я уже показывал пример примитивного трансформера, который разгадывал закономерности во входящей последовательности цифр.
Так вот, когда трансформер обучили на данных из интернета, оказалось, что нейросеть неплохо научилась отвечать на вопросы и выдавать достаточно правильные ответы даже на те вопросы, которых не было в датасете, — но ответ «вытекал» из других вопросов. При этом иногда возникали «галлюцинации».
Затем был запущен алгоритм, когда трансформер в попытке ответить правильно начал проверять свои ответы самостоятельно, подтверждая каждый шаг рассуждения и выстраивая собственную цепочку логики. Это позволило исключить львиную долю галлюцинаций.
Так началась эра «о1».
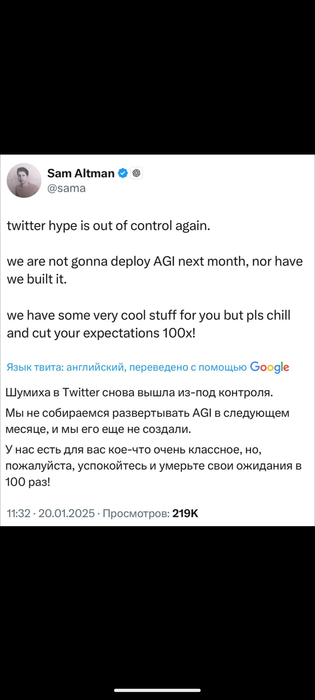
Не так давно (месяца не прошло) OpenAI продемонстрировала «о3».
Этот трансформер не только подтверждает свои рассуждения, но и оценивает разные способы решения задачи. Это называется Reinforcement Learning, когда модель оценивает возможные пути и выбирает максимально оптимальный вариант.И вот вышла новость: …
*(грамматические ошибки исправлены с помощью openai o1)

Немного напишу про своё детство.
Сколько себя помню, я всегда решал сложные задачи: в школьные годы были решены почти все сборники задач по математике, логике, программированию… Постоянно шёл поиск задач, которые сложнее, глубже, требуют больше времени на размышления и труда. Для чего? Да чтобы получить кайф, когда её решаешь!
Мозг, как мне кажется, работает по принципу алгоритма Reinforcement Learning. Он награждает нас, когда результат достигнут, но награды всё же недостаточно, чтобы мы остановились и не искали новую цель. Так продолжается процесс эволюции.
Примерно так и создатели трансформера пошли по этому пути: они «награждают» процесс мышления модели, процесс размышления, от чего модель начинает пробовать новые пути решения задач и находит их!
На самом деле это невероятно… Но факт: в итоге они получают некоторое подобие мышления.
Да, это ограниченное мышление в рамках данных, использованных при обучении (данных из интернета).
Но, возможно, и этих данных хватит, чтобы найти что-то новое: синтезировать данные для дальнейшего обучения, создавать более совершенные модели и так далее. Обучать всё более и более сложные модели, чтобы достичь машины, сравнимой с человеком, а возможно, и превосходящей его. Аминь.
*(грамматические ошибки исправлены с помощью openai o1)
момент "озарения" у нейросети :

ps :
Если они берут данные из интернета , надо больше писать про китайский покер )
Побочно решат игру при обучении трансформера)
Сообщение отредактировал c00l0ne - 21.1.2025, 10:22 -
Anthropic :

крутая статья по тестированию видеокарт
Сообщение отредактировал c00l0ne - 21.1.2025, 19:53 -
Самые лёгкие минус тысяча пятьсот в моей жизни
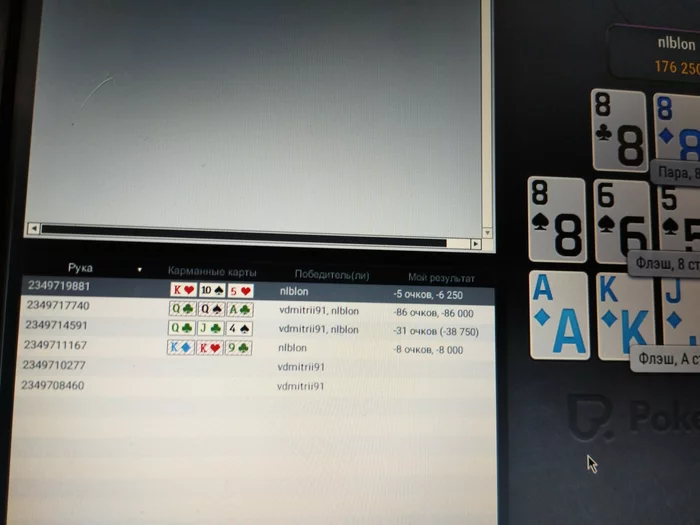
Стол с двумя фишами
-
здрасти... робоход
робобег
-
записываю: пнд вт ср играю в холдем ... в китайском ловить не х ... чего ...
худшие составы в турнирах , какие то бестолковые дешевые фрироллы с оверлеем 50к ))) покердом такой пд ... буэ
-
AI Revolution starting :
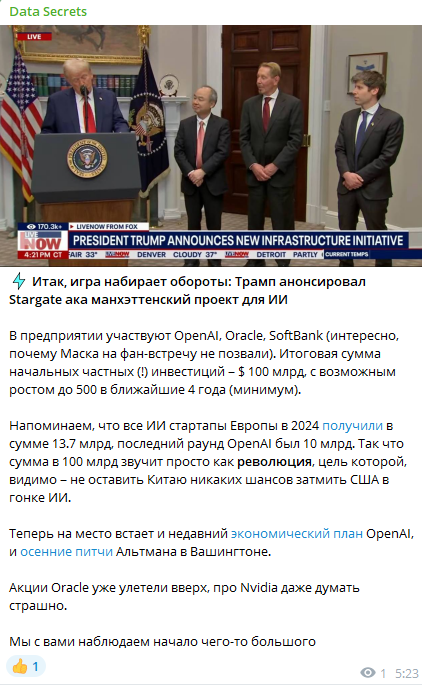
китайцы забайтили оч плотно трампа)
если Дядя Сэм готов отгрузить 500 млрд $ на все это это гг
Сообщение отредактировал c00l0ne - 22.1.2025, 2:41
- Вы сможете оставлять комментарии, оценивать посты, участвовать в дискуссиях и повышать свой уровень игры.
- Если вы предпочитаете четырехцветную колоду и хотите отключить анимацию аватаров, эти возможности будут в настройках профиля.
- Вам станут доступны закладки, бекинг и другие удобные инструменты сайта.
- На каждой странице будет видно, где появились новые посты и комментарии.
- Если вы зарегистрированы в покер-румах через GipsyTeam, вы получите статистику рейка, бонусные очки для покупок в магазине, эксклюзивные акции и расширенную поддержку.
Переводчики вышли из чата