



Статистика
Всего постов
3225
843,553 просмотров
Новых постов
+0
1 в день
Лучшие посты автора
Лучшие посты читателей
Самые активные читатели
| s4ekotilla | 129 |
| VANISH | 111 |
| Дизель | 52 |
| StratoLifter | 41 |
| Bagaiev | 39 |
-

-
 Сколько тебе было лет, когда поступали в джава школу? Как рассматриваете шансы выбиться в программисты 30 летнему? (в джава-школу уже не возьмут) Какие языки считаешь перспективными?
Сколько тебе было лет, когда поступали в джава школу? Как рассматриваете шансы выбиться в программисты 30 летнему? (в джава-школу уже не возьмут) Какие языки считаешь перспективными? -
 Кстати, никто не пробовал делать первую задачу с числами Фибоначчи? На мой взгляд, она не так проста, как кажется на первый взгляд.
Кстати, никто не пробовал делать первую задачу с числами Фибоначчи? На мой взгляд, она не так проста, как кажется на первый взгляд.Цитата (goba @ 16.5.2017)
Ну а считать простые числа дальше миллиарда на тестовом задании уже вряд ли попросят.
...
А можно же BitSet использовать, который занимает в java меньше памяти чем массив boolean
Не, ну им же надо (по идее) посмотреть, что ты и граничные условия учитываешь с своем решении. По крайней мере, если бы я проводил собеседование, то обязательно спросил бы. Другое дело, что когда сидишь один в переговорке, на такое можно и забить.
Да, битсет выглядит как хорошая альтернатива. Забыл про него :)Цитата (Stimpacked @ 16.5.2017)
Сколько тебе было лет, когда поступали в джава школу? Как рассматриваете шансы выбиться в программисты 30 летнему? (в джава-школу уже не возьмут) Какие языки считаешь перспективными?
1. Спустя пару недель после начала учебы мне стукнуло 26.
2. Шансы чуть ниже студентов, но есть и вполне реальные. Со мной вместе джава-школу проходил 30-летний парень, который больше 10 лет прослужил в армии и был оттуда уволен, после чего пошел в разработку ПО. И все ок, его взяли и до сих пор вполне успешно работает.
Было бы желание, короче говоря.
3. Перспективны и надежны топ-5 (условно) языки из рейтинга популярных, а также набирают популярность JavaScript и Go. -
Как я уже писал, в пятницу я был на собеседовании в Комтек. Помимо того, что у меня и так осталось не очень впечатление от конторы, так со мной еще вчера связалась hr и задала интересный вопрос:
"Здравствуйте Андрей, вот у вас зарплата, указанная в резюме, это желаемая ЗП?"
Я даже прифигел немного. Ну, а какие еще варианты есть? Что я нулем ошибся? Выяснилось, что они мне могут предложить лишь "немного меньше". Насколько немного, hr не уточнила, однако это уже тревожный звонок.
Затем мне еще прислали тестовое задание следующего содержания:Цитата
Using the Eclipse Sirius framework http://www.eclipse.org/sirius/
please create the diagram editor for any simple domain (from 3 to 5 entities).
https://wiki.eclipse.org/Sirius/Tutorials/StarterTutorial can be used as a reference implementation.
http://www.eclipse.org/ecoretools/doc/index.html may help to create domain (semantic) model.
Я пролистал оба туториала, и на примерно 40 страницах обнаружил целых 5 строк джавовского кода (и то, они были сгенерированы). А вся работа заключается в создании каких-то формочек, кнопочек и стилей через редактор.
Ну и тем более, что, судя по всему, все тестовое задание состоит в прохождении этого туториала.
Короче говоря, с утра написал им письмо о том, что я решил сконцентрироваться на других потенциальных проектах. Удачи им в поиске. -
В школу T-Systems вроде можно только в течении 3 лет после окончания университета. Java - круто, но вот в моем городе вакансий джуниоров нет. Сам работал косвенно связанно с программированием (программировал микроконтроллеры на ASM), вот что теперь делать хз, так как без ООП все бесперспективно.
-
Цитата (Stimpacked @ 17.5.2017)
В школу T-Systems вроде можно только в течении 3 лет после окончания университета. Java - круто, но вот в моем городе вакансий джуниоров нет. Сам работал косвенно связанно с программированием (программировал микроконтроллеры на ASM), вот что теперь делать хз, так как без ООП все бесперспективно.
1. Информацию про 3 года слышу впервые. Не ручаюсь конечно, но думаю что это не так, и примеры из жизни это подтверждают.
2. Как я уже писал, стоит смотреть на языки, которые востребованы в твоем городе (или в тех местах, куда планируется переезд)
Какое-то время назад я выкладывал информацию про казанский иннополис от человека, который там отучился. Может быть интересно для тебя.
3. Что делать? Учиться, учиться и еще раз учиться. Из воздуха ничего не появится. -
strkk, расскажи, как проходят рабочие будни программиста? Каждый "втыкает" в свой монитор, или есть какая-то движуха, обсуждения, интересные задачи, командировки может? В чем кайф от работы, ты как я понимаю, его получаешь?
-
Вот еще один способ найти prime numbers, используя чит
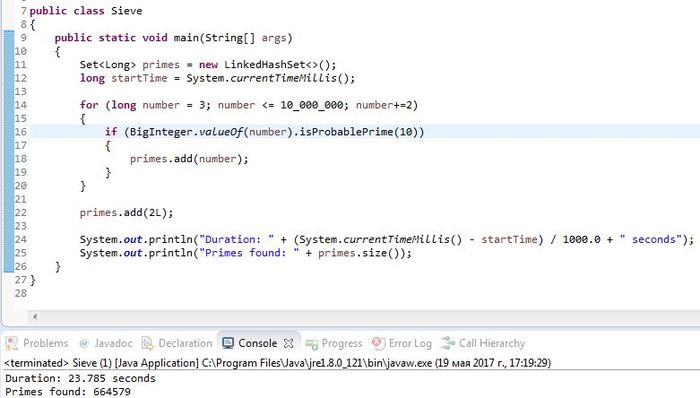
-
Про рабочие будни. Решил описать один мой день, а именно вчерашний (пятницу).
Начало рабочего дня у нас в компании не фиксированное. Это очень удобно. Я приезжаю на работу в период с 8 до 10.30, в зависимости от того, во сколько проснусь. Кто-то приезжает и к 11, и к 12 и даже к часу, уезжая вечером. Лично мне нравится начинать работу пораньше и заканчивать часов в 5, чтобы вечером было больше свободного времени.
Обычно я закачиваю себе на телефон или в киндл видео/книги, которые смотрю/читаю по пути.
Стандартная картина в утреннее время на "Василеостровской" - пробка к эскалатору. В особо плохое время эта пробка не успевает рассосаться до приезда следующего поезда, и выйти из дверей, соседствующих с пробкой бывает проблематично.
Приходим в офис.
Утро начинается с разбора почты, а дальше идут обычные дела. Мое рабочее место находится в обычном опен-спейсе. От рабочего места покериста отличается разве что наличием перегородки.
По офису хожу в тапках (на фото выше можно разглядеть под столом). Дресскода как такового нет, кто-то ходит и с разноцветными волосами и ирокезами. Прошлым летом я ходил в шортах и шлепанцах, отношение к этому довольно спокойное.
Опенспейс - не единственный тип рабочих пространств. Я уже 3 раза переезжал с места на место и до этого 2 раза сидел в небольших комнатах на полтора десятка человек. Мне такой тип нравится куда больше. Обычно обстановка рабочая, все сидят довольно тихо и размеренно кликают и печатают, периодически обсуждаются рабочие вопросы. Все это уже давно стало привычным фоном, на который лично я не обращаю внимания. Что периодически раздражает - это нерабочие разговоры про машины, поездки, треп по мобильнику и петросянство различных мастей. В упор не понимаю, почему не выйти и не поговорить по телефону в коридоре или не пойти куда-нибудь в другое место для обсуждения ближайшего отпуска.
Кто-то сидит в наушниках, лично я ими не пользуюсь и музыку не слушаю.
Часов в 11 с коллегами ходим завтракать, пить кофе и пообщаться. На фото где-то половина кухни, моя сбербанковская кружка с конференции JPoint. За стенкой с телевизором находится помещение с кулерами, кофеварками, микроволновками и холодильником. Многие приходят со своей едой (я в большинстве случаев тоже).
На стеллаже в углу различные настольные игры, такие как дженга, джангл спид, алиас и другие. В том числе шахматы, для них даже часы есть. Телевизор с X-box и кинектом, а также несколько игр к нему.
Слева на фото видно выход на террасу. Еще неделю назад шел снег, но теперь погода отличная и можно сидеть и там. На фото где-то половина террасы.
С другой половины видно Исаакиевский собор.
Дальше идет работа. Примерно в начале первого хожу играть в теннис, а потом на обед. В настольный теннис у нас играет на неплохом уровне человек 7-8, найти партнера обычно нетрудно. В игровой комнате есть гантели, коврики, турник, пара столов для кикера и теннисный стол. Сейчас идет у нас внутренний парный турнир, иногда там бывает многолюдно.

Мы с моим партнером уже вошли в топ-3, проиграв в финале виннеров (играем по системе с двойным выбиванием) фаворитам турнира. Сейчас ждем соперника из нижней сетки.
Иногда, когда не беру еду с собой, то хожу по окрестным общепитам. Самый ближайший находится прямо в нашем бизнес-центре.
Столовую около полугода назад отремонтировали, а также сменилась кейтеринговая компания-подрядчик. Раньше был интерьер заводской столовки, теперь стало гораздо уютнее.
Также есть небольшая зона-аквариум, где можно наблюдать за происходящим во дворе.
Цены:
Комплексные обеды - 150р (салат + второе + компот), 175р (еще + суп) и 250р (тот же набор что за 175, только более дорогие блюда)
В пешей доступности есть несколько столовых, кафе и баров, цены примерно такие же.
Дальше снова возвращаемся к работе с перерывом на кофе в районе 16.00
В это время чаще всего бывают различные телеконференции с немецкими коллегами, какие-то внутренние митинги, отмечания дней рождения и т.п. Различные встречи (а также мои встречи с ученицами) проводятся в переговорках. Их довольно много, различных размеров и обстановок. Какие-то из них нельзя забронировать простым смертным вроде меня, некоторые любят использовать для проведения собеседований, чтобы впечалить кандидата - на 7 этаже есть несколько таких комнат с видами на Исаакий.
Заканчиваю работать я обычно в 17-18 часов, после чего либо еду домой, либо провожу занятие или иду снова играть в теннис.
Наш двор.
Периодически приезжают немцы.
Командировки в Германию периодически случаются, правда я ниразу туда не ездил. Офисы есть почти во всех крупных (и не только) немецких городах. В одном из проектов отправляют сотрудников в Швейцарию.
Также есть командировки на различные конференции по России.
В принципе, это мой обычный день :)
По поводу задач отвечу позже, отдельным постом. -
 Интересно.
Интересно.
что за цифры на фото в метро? справа и слева время до прибытия поезда? а по середине время с секундами? просто привычней видеть : а не .
сорри есть вопросы покажутся глупыми, у нас в городе нет метро -
digitalmind, по центру -- местное время, справа/слева -- время с отбытия последнего поезда в этом направлении.
-

Цитата (goba @ 20.5.2017)
digitalmind, по центру -- местное время, справа/слева -- время с отбытия последнего поезда в этом направлении.
Вот кстати никогда не понимал, на кой хрен мне время отбытия, когда тебя всегда интересует время прибытия) А время отбытия интересно разве что машинисту следующего поезда, так он думаю эту инфу итак знает. В общем не понимаю почему бы не поменять эту систему. -
Slavik7, ну вот первое что выдал мне гугл по этому запросу - ссылка. Правда, после прочтения остается вопрос - если это время для машиниста, то зачем эти таймеры установлены в вестибюлях с горизонтальным лифтом (как, например, Василеостровская с фото), где машинисту их все равно не видно?
-
Еще одна контора прислала тестовое задание. На выбор 2 задачи.
Одна из них меня заинтересовала, думаю вам тоже будет интересно.Цитата
Необходимо написать класс Planner, который в методе planTasks получает имя текстового файла в котором каждая строка содержит целое положительное число(номер задачи) за которым следует через пробел другое целое положительное число(номер зависимой задачи).
Метод должен вернуть список содержащий в свою очередь списки тех задач которые можно выполнить независимо друг от друга.
Например для файла со следующим содержимым:
12 22
0 13
11 22
2 12
11 21
22 31
21 31
12 21
13 31
2 13
0 11
0 12
11 12
Метод вернет список, состоящий из 5 таких списков:
[0, 2]
[11, 13]
[12]
[22, 21]
[31]
В данном примере задачи 0 и 2 не зависят ни от кого и могут быть выполнены первыми, задачи 11 и 13 зависят только от 0 и 2 и выполняются потом и т.д.
К тестовому заданию прилагается архив с двумя наборами данных:
https://drive.google.com/file/d/0Bz18Sau7nJ6NeE1BY0ZfM2htR0U/view?usp=sharing
Задача будет считаться решенной, если класс Planner возвращает корректный результат для набора данных data2.txt за разумное время (несколько минут) на машине класса intel core i3 с 8гб RAM.
Задача будет считаться решенной отлично, если класс Planner возвращает корректный результат для набора данных data2.txt за менее чем 1 минуту на той же машине, при ограничении объема кучи 1гб (-Xmx1024M).
При решении задачи можно использовать любые библиотеки и фреймворки. Система сборки maven или gradle.
Не совсем понятно, что делать в случае циклов.
А так, по идее, данные - это список ребер в графе. К нему можно применить топологическую сортировку и затем выпиливать все вершины, на которые нет ссылок, до тех пор, пока их не останется совсем (ну или цикл не останется?)
В общем, надо будет завтра попробовать написать такую реализацию и посмотреть, что можно улучшить. -
Сам на Java не пишу, но решал бы задачу примерно так.
Нужно решить в каком виде хранить данные при загрузке с файла. Это могут быть списки, динамические массивы, связные списки и т.д.
Структура данных такая: Номер задачи, Счетчик, и список зависимых задач (заносим в список все зависимые задачи от данного Номера задачи).
Пусть мы решаем хранить эту структуру данных в списке List.
При считывании данных с файла добавляем данные в List по правилу:
- первое число (Номер задачи) - если еще нет в списке такого числа, то добавляем его и счетчик выставляем в 0, если уже есть, то счетчик не меняем;
в списке с этим числом добавляем в список зависимых задач второе число из этой же строчки данных.
- второе число (номер зависимой задачи) - если нет такого числа в списке, то добавляем его и счетчик выставляем в 0, иначе счетчик не меняем.
После этого счетчик увеличиваем на 1 (счетчик для этого второго числа).
В результате после одноразового считывания всего файла у нас должен получиться список с такой структурой данных:
Первое число - уникальный Номер задачи, Счетчик - к-во задач от которых зависит данная задача (от 0 и больше), и список всех номеров зависимых задач.
Далее в цикле делаем следующее:
1. Проверяем весь список и ищем Номера задачи, где счетчик равен 0 - это искомые номера задач для данной итерации, выводим их.
2. Для каждого из этих найденных номеров в списке смотрим весь список зависимых задач и для каждого номера зависимой задачи уменьшаем соответствующий ему счетчик на 1.
3. Удаляем из списка все записи с только-что найденными номерами.
Пока список не пуст переходим на пункт 1.
Вот такой вкратце алгоритм. Самое сложное - как эффективно реализовать список, чтобы можно было проверять есть ли уже в списке данный номер, находить быстро нужный номер и изменять его счетчик, а также удалять уже найденные номера. -
Galax, Вот я написал 1 в 1 то, что ты обозначил. С той лишь разницей, что все это
Цитата (Galax @ 23.5.2017)
Номер задачи, Счетчик, и список зависимых задач (заносим в список все зависимые задачи от данного Номера задачи)
предоставляет библиотека, которая составляет ориентированный граф.
Правда, закончилось выполнение на том, что я вылетел с OutOfMemoryError еще на этапе добавления данных из файла в граф. Надо будет попробовать упростить это как-нибудь. -
-
goba, это на миддла (вроде бы). Вообще в требованиях указан опыт работы от 1 года и хорошее знание Java SE.
Вторая задача под спойлером. Мне даже интересно, неужели кто-то действительно ее предпочел? Это же полная жесть для написания в качестве тестового задания, по сравнению с альтернативой. Я прочитал первые три слова и мне уже захотелось закрыть это :)Необходимо реализовать сервер, принимающий UDP пакеты на порт 7000, с геоданными от неких мобильных устройств, устройства могут присылать данные с одного и того же IP-адреса и различаются только по уникальному 6-байтному идентификатору в пакете.
Геоданные(Время, широта и долгота) необходимо сохранить в реляционную БД и после успешной записи подтвердить получение пакета ответным пакетом, в случае ошибки записи в БД никакого ответа не высылается.
Формат пакета с гео-данными:
Поле
Тип
6-байтный адрес устройства(MAC)
48-бит беззнаковое целое
Тип пакета(PT)
8-бит беззнаковое целое (1 у пакета данных)
Порядковый номер пакета (ID)
32-бит беззнаковое целое (всегда увеличивается на 1 при отправке нового пакета устройством, начиная с 0)
Время определения местоположения
64-бит беззнаковое целое (Время UTC в миллисекундах с 01.01.1970 00:00:00)
Широта
64-бит вещественное (double) (южная широта отрицательная)
Долгота
64-бит вещественное (double) (западная долгота отрицательная)
Формат пакета подтверждения:
Поле
Тип
6-байтный адрес устройства(MAC)
48-бит беззнаковое целое (соответствует полю MAC подтверждаемого пакета)
Тип пакета(PT)
8-бит беззнаковое целое (2 у пакета-подтверждения)
Порядковый номер подтвержденного пакета (ACKID)
32-бит беззнаковое целое (равно полю ID пакета, который подтверждаем)
Порядок байт в пакетах - сетевой (BIG-ENDIAN)
Каждое устройство шлет пакеты 1 раз в секунду. Если не получает подтверждения - повторяет пакет каждые 100мс до момента формирования нового пакета. Количество устройств в сети около 1000.
При решении задачи можно использовать любые библиотеки и фреймворки. Система сборки maven или gradle. За использование в задаче PostgreSQL и Vert.X дополнительные плюсы при оценке результата. -
Так самое сложное в этой задаче, как сохранить в памяти огромный массив данных. Я посмотрел что в Delphi объект TList имеет ограничение (по-моему 16380 элементов) - это очень мало для такой задачи. Так что придется придумывать что-то свое. Наверное динамические массивы подошли бы, но придется писать свои процедуры добавления в массив, удаления и поиска нужного элемента и т.д.
Интересно, как это решается в Java? -
strkk, спасибо! Да, первая задача выглядит куда привлекательнее этой. Может быть тех, кто решает вторую берут в другой отдел, где нужны первые три слова из условия?
Galax, беглый поиск подсказывает, что в java максимальный размер для ArrayList порядка 2^31 (пишут что 2^31-1, но обычно память заканчивается быстрее). На практике на одном компьютере ограничением служит объем оперативки, а не максимально возможное число элементов в массиве.
1 человек читает эту тему (1 гость):
Зачем регистрироваться на GipsyTeam?
- Вы сможете оставлять комментарии, оценивать посты, участвовать в дискуссиях и повышать свой уровень игры.
- Если вы предпочитаете четырехцветную колоду и хотите отключить анимацию аватаров, эти возможности будут в настройках профиля.
- Вам станут доступны закладки, бекинг и другие удобные инструменты сайта.
- На каждой странице будет видно, где появились новые посты и комментарии.
- Если вы зарегистрированы в покер-румах через GipsyTeam, вы получите статистику рейка, бонусные очки для покупок в магазине, эксклюзивные акции и расширенную поддержку.
По факту и 100 000 000 и миллиард спокойно пролезают по памяти даже в такой "лобовой" реализации. А можно же BitSet использовать, который занимает в java меньше памяти чем массив boolean.
Ну а считать простые числа дальше миллиарда на тестовом задании уже вряд ли попросят.
P.S. Извиняюсь, если меня стало слишком много в этом дневнике! Просто увидел задачу про решето Эратосфена и решил попробовать написать, а потом захотелось выложить свой код и пошло-поехало...
P.P.S. Отличный дневник, кстати, выкладывай побольше интересных историй из жизни программистов!